 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Multimodal Models for Low-Resource Languages: A Survey
Feb 08, 2025



In this survey, we systematically analyze techniques used to adapt large multimodal models (LMMs) for low-resource (LR) languages, examining approaches ranging from visual enhancement and data creation to cross-modal transfer and fusion strategies. Through a comprehensive analysis of 106 studies across 75 LR languages, we identify key patterns in how researchers tackle the challenges of limited data and computational resources. We find that visual information often serves as a crucial bridge for improving model performance in LR settings, though significant challenges remain in areas such as hallucination mitigation and computational efficiency. We aim to provide researchers with a clear understanding of current approaches and remaining challenges in making LMMs more accessible to speakers of LR (understudied) languages. We complement our survey with an open-source repository available at: https://github.com/marianlupascu/LMM4LRL-Survey.
PoPreRo: A New Dataset for Popularity Prediction of Romanian Reddit Posts
Jul 05, 2024



We introduce PoPreRo, the first dataset for Popularity Prediction of Romanian posts collected from Reddit. The PoPreRo dataset includes a varied compilation of post samples from five distinct subreddits of Romania, totaling 28,107 data samples. Along with our novel dataset, we introduce a set of competitive models to be used as baselines for future research. Interestingly, the top-scoring model achieves an accuracy of 61.35% and a macro F1 score of 60.60% on the test set, indicating that the popularity prediction task on PoPreRo is very challenging. Further investigations based on few-shot prompting the Falcon-7B Large Language Model also point in the same direction. We thus believe that PoPreRo is a valuable resource that can be used to evaluate models on predicting the popularity of social media posts in Romanian. We release our dataset at https://github.com/ana-rogoz/PoPreRo.
UnibucLLM: Harnessing LLMs for Automated Prediction of Item Difficulty and Response Time for Multiple-Choice Questions
Apr 20, 2024



This work explores a novel data augmentation method based on Large Language Models (LLMs) for predicting item difficulty and response time of retired USMLE Multiple-Choice Questions (MCQs) in the BEA 2024 Shared Task. Our approach is based on augmenting the dataset with answers from zero-shot LLMs (Falcon, Meditron, Mistral) and employing transformer-based models based on six alternative feature combinations. The results suggest that predicting the difficulty of questions is more challenging. Notably, our top performing methods consistently include the question text, and benefit from the variability of LLM answers, highlighting the potential of LLMs for improving automated assessment in medical licensing exams. We make our code available https://github.com/ana-rogoz/BEA-2024.
Semantic Segmentation Alternative Technique: Segmentation Domain Generation
Jul 06, 2021


Detecting objects of interest in images was always a compelling task to automate. In recent years this task was more and more explored using deep learning techniques, mostly using region-based convolutional networks. In this project we propose an alternative semantic segmentation technique making use of Generative Adversarial Networks. We consider semantic segmentation to be a domain transfer problem. Thus, we train a feed forward network (FFNN) to receive as input a seed real image and generate as output its segmentation mask.
SaRoCo: Detecting Satire in a Novel Romanian Corpus of News Articles
May 14, 2021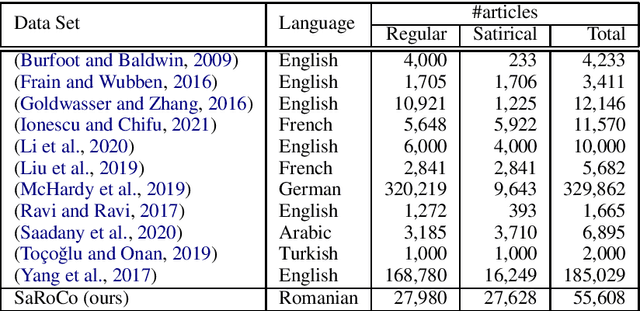


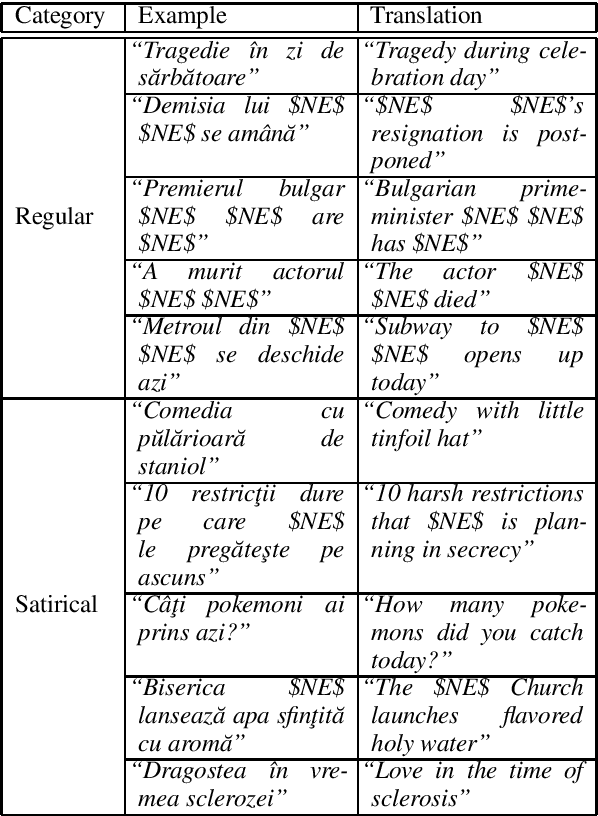
In this work, we introduce a corpus for satire detection in Romanian news. We gathered 55,608 public news articles from multiple real and satirical news sources, composing one of the largest corpora for satire detection regardless of language and the only one for the Romanian language. We provide an official split of the text samples, such that training news articles belong to different sources than test news articles, thus ensuring that models do not achieve high performance simply due to overfitting. We conduct experiments with two state-of-the-art deep neural models, resulting in a set of strong baselines for our novel corpus. Our results show that the machine-level accuracy for satire detection in Romanian is quite low (under 73% on the test set) compared to the human-level accuracy (87%), leaving enough room for improvement in future research.