 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreCDo: A Large Corpus for French Cross-Domain Dialect Identification
Paper and Code

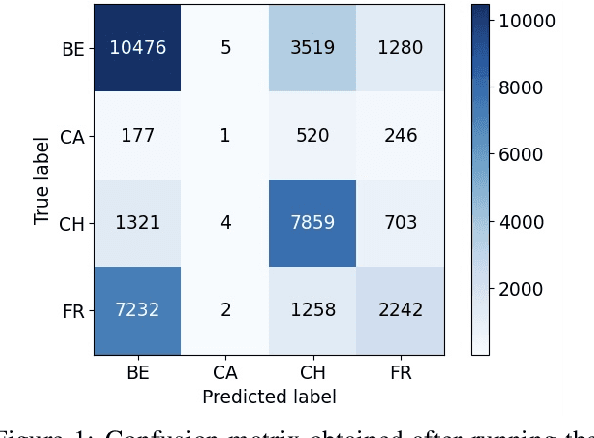

We present a novel corpus for French dialect identification comprising 413,522 French text samples collected from public news websites in Belgium, Canada, France and Switzerland. To ensure an accurate estimation of the dialect identification performance of models, we designed the corpus to eliminate potential biases related to topic, writing style, and publication source. More precisely, the training, validation and test splits are collected from different news websites, while searching for different keywords (topics). This leads to a French cross-domain (FreCDo) dialect identification task. We conduct experiments with four competitive baselines, a fine-tuned CamemBERT model, an XGBoost based on fine-tuned CamemBERT features, a Support Vector Machines (SVM) classifier based on fine-tuned CamemBERT features, and an SVM based on word n-grams. Aside from presenting quantitative results, we also make an analysis of the most discriminative features learned by CamemBERT. Our corpus is available at https://github.com/MihaelaGaman/FreCDo.