 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Shapley Additive Explanations to Understand Anomaly Detection Algorithm Behaviors and Their Complementarity
Jan 30, 2026Unsupervised anomaly detection is a challenging problem due to the diversity of data distributions and the lack of labels. Ensemble methods are often adopted to mitigate these challenges by combining multiple detectors, which can reduce individual biases and increase robustness. Yet building an ensemble that is genuinely complementary remains challenging, since many detectors rely on similar decision cues and end up producing redundant anomaly scores. As a result, the potential of ensemble learning is often limited by the difficulty of identifying models that truly capture different types of irregularities. To address this, we propose a methodology for characterizing anomaly detectors through their decision mechanisms. Using SHapley Additive exPlanations, we quantify how each model attributes importance to input features, and we use these attribution profiles to measure similarity between detectors. We show that detectors with similar explanations tend to produce correlated anomaly scores and identify largely overlapping anomalies. Conversely, explanation divergence reliably indicates complementary detection behavior. Our results demonstrate that explanation-driven metrics offer a different criterion than raw outputs for selecting models in an ensemble. However, we also demonstrate that diversity alone is insufficient; high individual model performance remains a prerequisite for effective ensembles. By explicitly targeting explanation diversity while maintaining model quality, we are able to construct ensembles that are more diverse, more complementary, and ultimately more effective for unsupervised anomaly detection.
From Black-Box Tuning to Guided Optimization via Hyperparameters Interaction Analysis
Dec 22, 2025Hyperparameters tuning is a fundamental, yet computationally expensive, step in optimizing machine learning models. Beyond optimization, understanding the relative importance and interaction of hyperparameters is critical to efficient model development. In this paper, we introduce MetaSHAP, a scalable semi-automated eXplainable AI (XAI) method, that uses meta-learning and Shapley values analysis to provide actionable and dataset-aware tuning insights. MetaSHAP operates over a vast benchmark of over 09 millions evaluated machine learning pipelines, allowing it to produce interpretable importance scores and actionable tuning insights that reveal how much each hyperparameter matters, how it interacts with others and in which value ranges its influence is concentrated. For a given algorithm and dataset, MetaSHAP learns a surrogate performance model from historical configurations, computes hyperparameters interactions using SHAP-based analysis, and derives interpretable tuning ranges from the most influential hyperparameters. This allows practitioners not only to prioritize which hyperparameters to tune, but also to understand their directionality and interactions. We empirically validate MetaSHAP on a diverse benchmark of 164 classification datasets and 14 classifiers, demonstrating that it produces reliable importance rankings and competitive performance when used to guide Bayesian optimization.
XStacking: Explanation-Guided Stacked Ensemble Learning
Jul 23, 2025Ensemble Machine Learning (EML) techniques, especially stacking, have been shown to improve predictive performance by combining multiple base models. However, they are often criticized for their lack of interpretability. In this paper, we introduce XStacking, an effective and inherently explainable framework that addresses this limitation by integrating dynamic feature transformation with model-agnostic Shapley additive explanations. This enables stacked models to retain their predictive accuracy while becoming inherently explainable. We demonstrate the effectiveness of the framework on 29 datasets, achieving improvements in both the predictive effectiveness of the learning space and the interpretability of the resulting models. XStacking offers a practical and scalable solution for responsible ML.
An experimental survey and Perspective View on Meta-Learning for Automated Algorithms Selection and Parametrization
Apr 08, 2025



Considerable progress has been made in the recent literature studies to tackle the Algorithms Selection and Parametrization (ASP) problem, which is diversified in multiple meta-learning setups. Yet there is a lack of surveys and comparative evaluations that critically analyze, summarize and assess the performance of existing methods. In this paper, we provide an overview of the state of the art in this continuously evolving field. The survey sheds light on the motivational reasons for pursuing classifiers selection through meta-learning. In this regard, Automated Machine Learning (AutoML) is usually treated as an ASP problem under the umbrella of the democratization of machine learning. Accordingly, AutoML makes machine learning techniques accessible to domain scientists who are interested in applying advanced analytics but lack the required expertise. It can ease the task of manually selecting ML algorithms and tuning related hyperparameters. We comprehensively discuss the different phases of classifiers selection based on a generic framework that is formed as an outcome of reviewing prior works. Subsequently, we propose a benchmark knowledge base of 4 millions previously learned models and present extensive comparative evaluations of the prominent methods for classifiers selection based on 08 classification algorithms and 400 benchmark datasets. The comparative study quantitatively assesses the performance of algorithms selection methods along while emphasizing the strengths and limitations of existing studies.
Uncovering the Limitations of Query Performance Prediction: Failures, Insights, and Implications for Selective Query Processing
Apr 01, 2025Query Performance Prediction (QPP) estimates retrieval systems effectiveness for a given query, offering valuable insights for search effectiveness and query processing. Despite extensive research, QPPs face critical challenges in generalizing across diverse retrieval paradigms and collections. This paper provides a comprehensive evaluation of state-of-the-art QPPs (e.g. NQC, UQC), LETOR-based features, and newly explored dense-based predictors. Using diverse sparse rankers (BM25, DFree without and with query expansion) and hybrid or dense (SPLADE and ColBert) rankers and diverse test collections ROBUST, GOV2, WT10G, and MS MARCO; we investigate the relationships between predicted and actual performance, with a focus on generalization and robustness. Results show significant variability in predictors accuracy, with collections as the main factor and rankers next. Some sparse predictors perform somehow on some collections (TREC ROBUST and GOV2) but do not generalise to other collections (WT10G and MS-MARCO). While some predictors show promise in specific scenarios, their overall limitations constrain their utility for applications. We show that QPP-driven selective query processing offers only marginal gains, emphasizing the need for improved predictors that generalize across collections, align with dense retrieval architectures and are useful for downstream applications.
Model Lake: a New Alternative for Machine Learning Models Management and Governance
Mar 27, 2025The rise of artificial intelligence and data science across industries underscores the pressing need for effective management and governance of machine learning (ML) models. Traditional approaches to ML models management often involve disparate storage systems and lack standardized methodologies for versioning, audit, and re-use. Inspired by data lake concepts, this paper develops the concept of ML Model Lake as a centralized management framework for datasets, codes, and models within organizations environments. We provide an in-depth exploration of the Model Lake concept, delineating its architectural foundations, key components, operational benefits, and practical challenges. We discuss the transformative potential of adopting a Model Lake approach, such as enhanced model lifecycle management, discovery, audit, and reusability. Furthermore, we illustrate a real-world application of Model Lake and its transformative impact on data, code and model management practices.
Investigating the Duality of Interpretability and Explainability in Machine Learning
Mar 27, 2025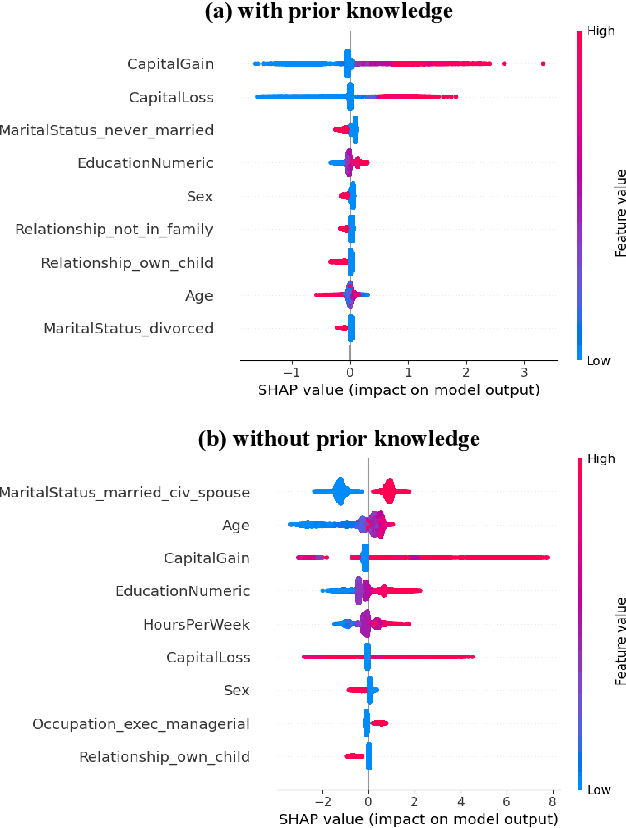
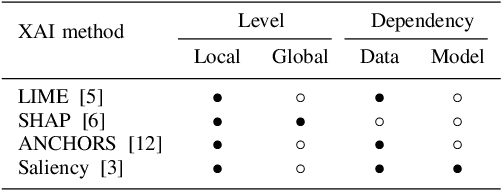
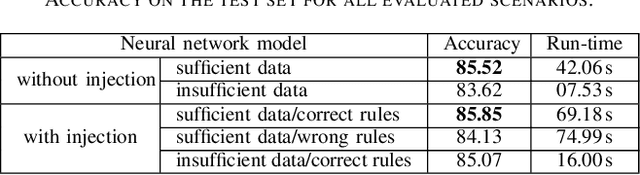

The rapid evolution of machine learning (ML) has led to the widespread adoption of complex "black box" models, such as deep neural networks and ensemble methods. These models exhibit exceptional predictive performance, making them invaluable for critical decision-making across diverse domains within society. However, their inherently opaque nature raises concerns about transparency and interpretability, making them untrustworthy decision support systems. To alleviate such a barrier to high-stakes adoption, research community focus has been on developing methods to explain black box models as a means to address the challenges they pose. Efforts are focused on explaining these models instead of developing ones that are inherently interpretable. Designing inherently interpretable models from the outset, however, can pave the path towards responsible and beneficial applications in the field of ML. In this position paper, we clarify the chasm between explaining black boxes and adopting inherently interpretable models. We emphasize the imperative need for model interpretability and, following the purpose of attaining better (i.e., more effective or efficient w.r.t. predictive performance) and trustworthy predictors, provide an experimental evaluation of latest hybrid learning methods that integrates symbolic knowledge into neural network predictors. We demonstrate how interpretable hybrid models could potentially supplant black box ones in different domains.
Dense Retrieval for Low Resource Languages -- the Case of Amharic Language
Mar 24, 2025This paper reports some difficulties and some results when using dense retrievers on Amharic, one of the low-resource languages spoken by 120 millions populations. The efforts put and difficulties faced by University Addis Ababa toward Amharic Information Retrieval will be developed during the presentation.