 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixMAS: A Framework for Sampling-Based Mixer Architecture Search for Multimodal Fusion and Learning
Dec 24, 2024Choosing a suitable deep learning architecture for multimodal data fusion is a challenging task, as it requires the effective integration and processing of diverse data types, each with distinct structures and characteristics. In this paper, we introduce MixMAS, a novel framework for sampling-based mixer architecture search tailored to multimodal learning. Our approach automatically selects the optimal MLP-based architecture for a given multimodal machine learning (MML) task. Specifically, MixMAS utilizes a sampling-based micro-benchmarking strategy to explore various combinations of modality-specific encoders, fusion functions, and fusion networks, systematically identifying the architecture that best meets the task's performance metrics.
Multimodal Learning with Uncertainty Quantification based on Discounted Belief Fusion
Dec 23, 2024Multimodal AI models are increasingly used in fields like healthcare, finance, and autonomous driving, where information is drawn from multiple sources or modalities such as images, texts, audios, videos. However, effectively managing uncertainty - arising from noise, insufficient evidence, or conflicts between modalities - is crucial for reliable decision-making. Current uncertainty-aware ML methods leveraging, for example, evidence averaging, or evidence accumulation underestimate uncertainties in high-conflict scenarios. Moreover, the state-of-the-art evidence averaging strategy struggles with non-associativity and fails to scale to multiple modalities. To address these challenges, we propose a novel multimodal learning method with order-invariant evidence fusion and introduce a conflict-based discounting mechanism that reallocates uncertain mass when unreliable modalities are detected. We provide both theoretical analysis and experimental validation, demonstrating that unlike the previous work, the proposed approach effectively distinguishes between conflicting and non-conflicting samples based on the provided uncertainty estimates, and outperforms the previous models in uncertainty-based conflict detection.
LUMA: A Benchmark Dataset for Learning from Uncertain and Multimodal Data
Jun 14, 2024
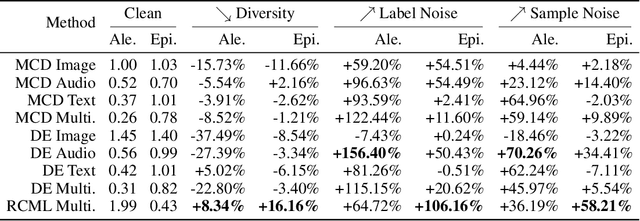


Multimodal Deep Learning enhances decision-making by integrating diverse information sources, such as texts, images, audio, and videos. To develop trustworthy multimodal approaches, it is essential to understand how uncertainty impacts these models. We introduce LUMA, a unique benchmark dataset, featuring audio, image, and textual data from 50 classes, for learning from uncertain and multimodal data. It extends the well-known CIFAR 10/100 dataset with audio samples extracted from three audio corpora, and text data generated using the Gemma-7B Large Language Model (LLM). The LUMA dataset enables the controlled injection of varying types and degrees of uncertainty to achieve and tailor specific experiments and benchmarking initiatives. LUMA is also available as a Python package including the functions for generating multiple variants of the dataset with controlling the diversity of the data, the amount of noise for each modality, and adding out-of-distribution samples. A baseline pre-trained model is also provided alongside three uncertainty quantification methods: Monte-Carlo Dropout, Deep Ensemble, and Reliable Conflictive Multi-View Learning. This comprehensive dataset and its tools are intended to promote and support the development and benchmarking of trustworthy and robust multimodal deep learning approaches.
Linguistic features for sentence difficulty prediction in ABSA
Feb 05, 2024One of the challenges of natural language understanding is to deal with the subjectivity of sentences, which may express opinions and emotions that add layers of complexity and nuance. Sentiment analysis is a field that aims to extract and analyze these subjective elements from text, and it can be applied at different levels of granularity, such as document, paragraph, sentence, or aspect. Aspect-based sentiment analysis is a well-studied topic with many available data sets and models. However, there is no clear definition of what makes a sentence difficult for aspect-based sentiment analysis. In this paper, we explore this question by conducting an experiment with three data sets: "Laptops", "Restaurants", and "MTSC" (Multi-Target-dependent Sentiment Classification), and a merged version of these three datasets. We study the impact of domain diversity and syntactic diversity on difficulty. We use a combination of classifiers to identify the most difficult sentences and analyze their characteristics. We employ two ways of defining sentence difficulty. The first one is binary and labels a sentence as difficult if the classifiers fail to correctly predict the sentiment polarity. The second one is a six-level scale based on how many of the top five best-performing classifiers can correctly predict the sentiment polarity. We also define 9 linguistic features that, combined, aim at estimating the difficulty at sentence level.