 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Legal Argument Mining with Domain Pre-training and Neural Networks
Apr 06, 2022
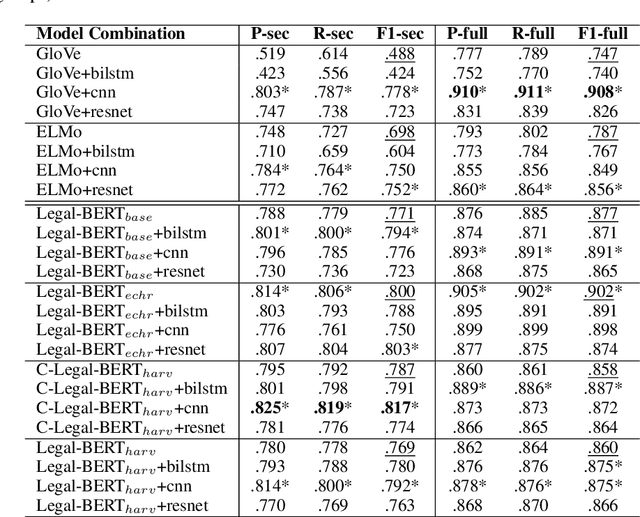
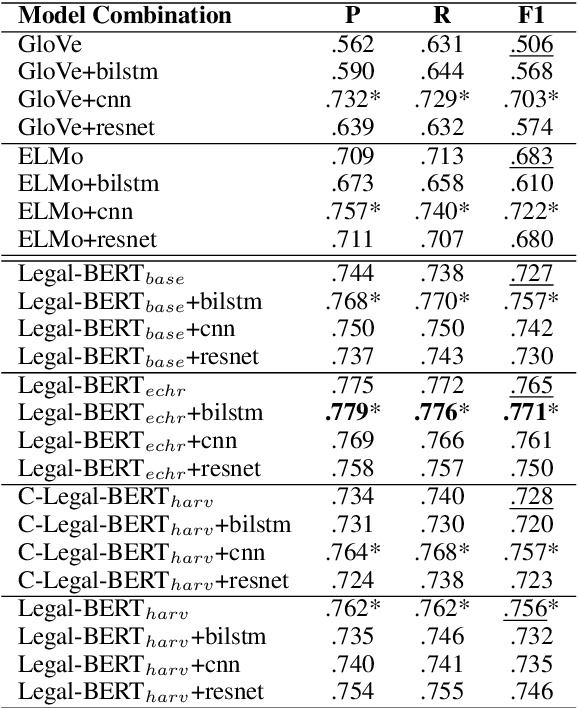
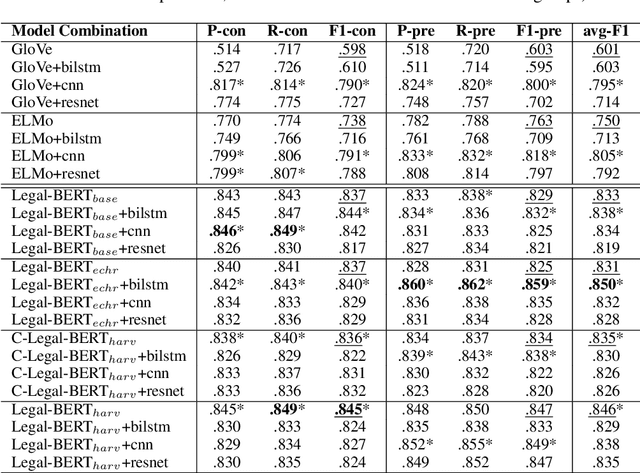
The contextual word embedding model, BERT, has proved its ability on downstream tasks with limited quantities of annotated data. BERT and its variants help to reduce the burden of complex annotation work in many interdisciplinary research areas, for example, legal argument mining in digital humanities. Argument mining aims to develop text analysis tools that can automatically retrieve arguments and identify relationships between argumentation clauses. Since argumentation is one of the key aspects of case law, argument mining tools for legal texts are applicable to both academic and non-academic legal research. Domain-specific BERT variants (pre-trained with corpora from a particular background) have also achieved strong performance in many tasks. To our knowledge, previous machine learning studies of argument mining on judicial case law still heavily rely on statistical models. In this paper, we provide a broad study of both classic and contextual embedding models and their performance on practical case law from the European Court of Human Rights (ECHR). During our study, we also explore a number of neural networks when being combined with different embeddings. Our experiments provide a comprehensive overview of a variety of approaches to the legal argument mining task. We conclude that domain pre-trained transformer models have great potential in this area, although traditional embeddings can also achieve strong performance when combined with additional neural network layers.
Crisis Domain Adaptation Using Sequence-to-sequence Transformers
Oct 15, 2021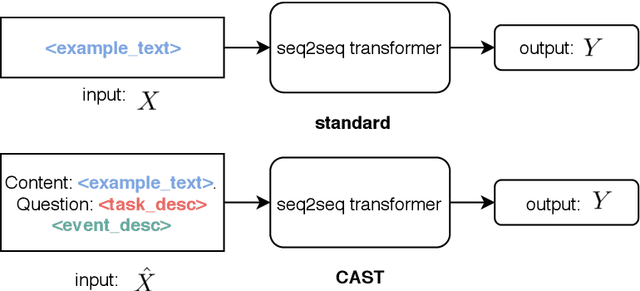
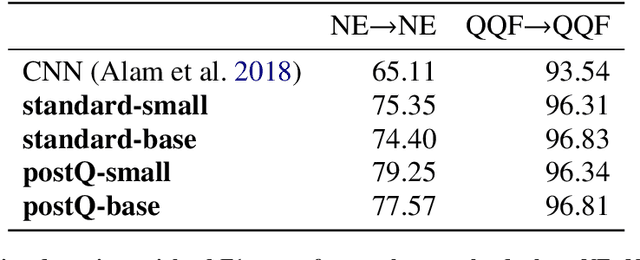

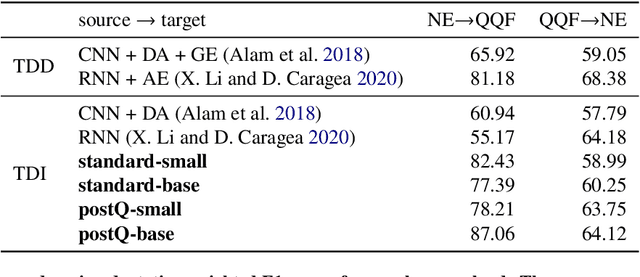
User-generated content (UGC) on social media can act as a key source of information for emergency responders in crisis situations. However, due to the volume concerned, computational techniques are needed to effectively filter and prioritise this content as it arises during emerging events. In the literature, these techniques are trained using annotated content from previous crises. In this paper, we investigate how this prior knowledge can be best leveraged for new crises by examining the extent to which crisis events of a similar type are more suitable for adaptation to new events (cross-domain adaptation). Given the recent successes of transformers in various language processing tasks, we propose CAST: an approach for Crisis domain Adaptation leveraging Sequence-to-sequence Transformers. We evaluate CAST using two major crisis-related message classification datasets. Our experiments show that our CAST-based best run without using any target data achieves the state of the art performance in both in-domain and cross-domain contexts. Moreover, CAST is particularly effective in one-to-one cross-domain adaptation when trained with a larger language model. In many-to-one adaptation where multiple crises are jointly used as the source domain, CAST further improves its performance. In addition, we find that more similar events are more likely to bring better adaptation performance whereas fine-tuning using dissimilar events does not help for adaptation. To aid reproducibility, we open source our code to the community.
Transformer-based Multi-task Learning for Disaster Tweet Categorisation
Oct 15, 2021
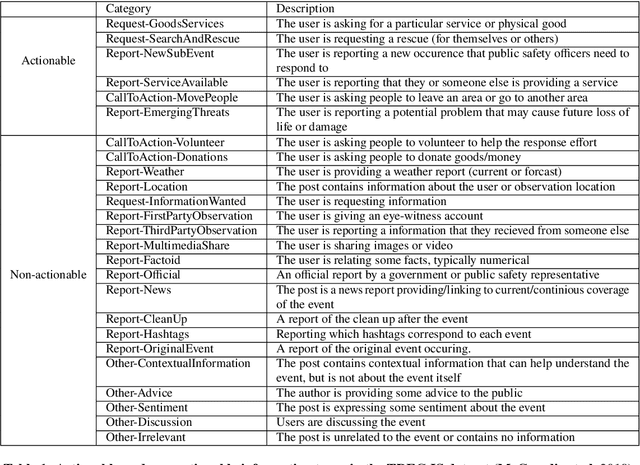
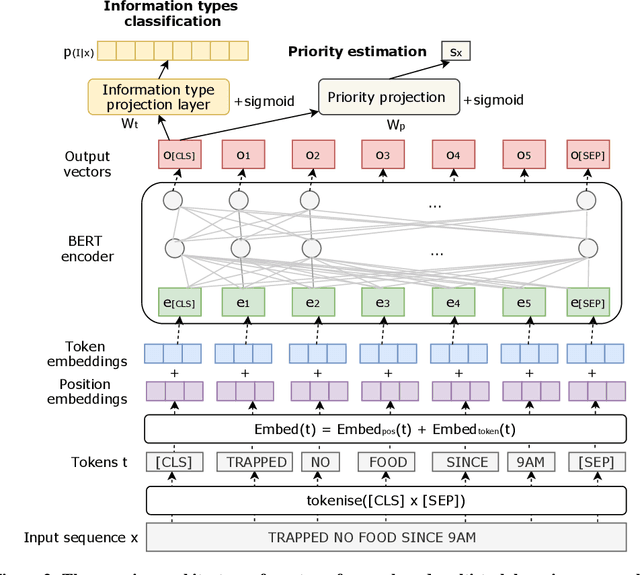
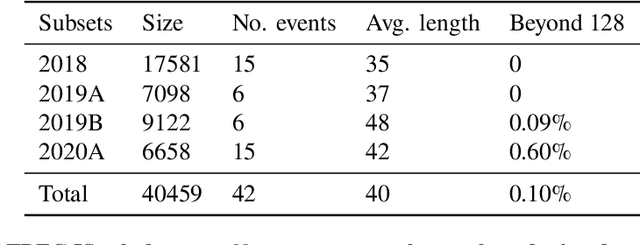
Social media has enabled people to circulate information in a timely fashion, thus motivating people to post messages seeking help during crisis situations. These messages can contribute to the situational awareness of emergency responders, who have a need for them to be categorised according to information types (i.e. the type of aid services the messages are requesting). We introduce a transformer-based multi-task learning (MTL) technique for classifying information types and estimating the priority of these messages. We evaluate the effectiveness of our approach with a variety of metrics by submitting runs to the TREC Incident Streams (IS) track: a research initiative specifically designed for disaster tweet classification and prioritisation. The results demonstrate that our approach achieves competitive performance in most metrics as compared to other participating runs. Subsequently, we find that an ensemble approach combining disparate transformer encoders within our approach helps to improve the overall effectiveness to a significant extent, achieving state-of-the-art performance in almost every metric. We make the code publicly available so that our work can be reproduced and used as a baseline for the community for future work in this domain.