 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUCD-CS at W-NUT 2020 Shared Task-3: A Text to Text Approach for COVID-19 Event Extraction on Social Media
Paper and Code

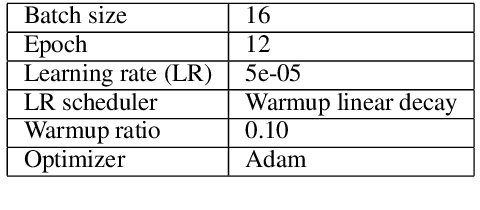
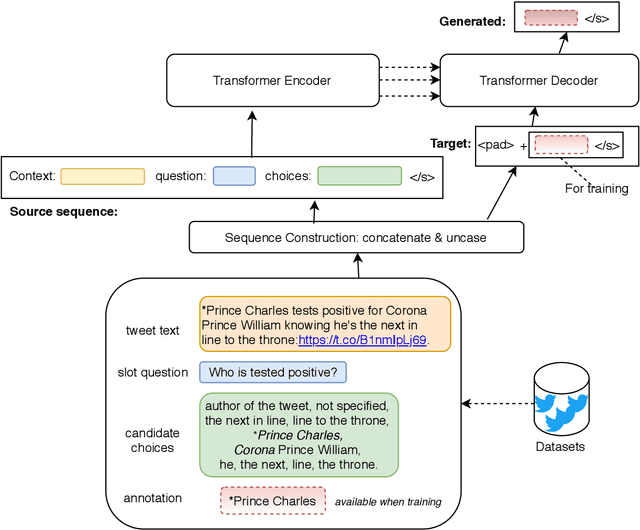
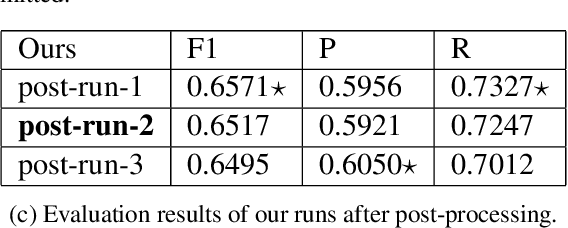
In this paper, we describe our approach in the shared task: COVID-19 event extraction from Twitter. The objective of this task is to extract answers from COVID-related tweets to a set of predefined slot-filling questions. Our approach treats the event extraction task as a question answering task by leveraging the transformer-based T5 text-to-text model. According to the official evaluation scores returned, namely F1, our submitted run achieves competitive performance compared to other participating runs (Top 3). However, we argue that this evaluation may underestimate the actual performance of runs based on text-generation. Although some such runs may answer the slot questions well, they may not be an exact string match for the gold standard answers. To measure the extent of this underestimation, we adopt a simple exact-answer transformation method aiming at converting the well-answered predictions to exactly-matched predictions. The results show that after this transformation our run overall reaches the same level of performance as the best participating run and state-of-the-art F1 scores in three of five COVID-related events. Our code is publicly available to aid reproducibility