 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsultation Checklists: Standardising the Human Evaluation of Medical Note Generation
Nov 17, 2022



Evaluating automatically generated text is generally hard due to the inherently subjective nature of many aspects of the output quality. This difficulty is compounded in automatic consultation note generation by differing opinions between medical experts both about which patient statements should be included in generated notes and about their respective importance in arriving at a diagnosis. Previous real-world evaluations of note-generation systems saw substantial disagreement between expert evaluators. In this paper we propose a protocol that aims to increase objectivity by grounding evaluations in Consultation Checklists, which are created in a preliminary step and then used as a common point of reference during quality assessment. We observed good levels of inter-annotator agreement in a first evaluation study using the protocol; further, using Consultation Checklists produced in the study as reference for automatic metrics such as ROUGE or BERTScore improves their correlation with human judgements compared to using the original human note.
User-Driven Research of Medical Note Generation Software
May 06, 2022



A growing body of work uses Natural Language Processing (NLP) methods to automatically generate medical notes from audio recordings of doctor-patient consultations. However, there are very few studies on how such systems could be used in clinical practice, how clinicians would adjust to using them, or how system design should be influenced by such considerations. In this paper, we present three rounds of user studies, carried out in the context of developing a medical note generation system. We present, analyse and discuss the participating clinicians' impressions and views of how the system ought to be adapted to be of value to them. Next, we describe a three-week test run of the system in a live telehealth clinical practice. Major findings include (i) the emergence of five different note-taking behaviours; (ii) the importance of the system generating notes in real time during the consultation; and (iii) the identification of a number of clinical use cases that could prove challenging for automatic note generation systems.
Human Evaluation and Correlation with Automatic Metrics in Consultation Note Generation
Apr 01, 2022



In recent years, machine learning models have rapidly become better at generating clinical consultation notes; yet, there is little work on how to properly evaluate the generated consultation notes to understand the impact they may have on both the clinician using them and the patient's clinical safety. To address this we present an extensive human evaluation study of consultation notes where 5 clinicians (i) listen to 57 mock consultations, (ii) write their own notes, (iii) post-edit a number of automatically generated notes, and (iv) extract all the errors, both quantitative and qualitative. We then carry out a correlation study with 18 automatic quality metrics and the human judgements. We find that a simple, character-based Levenshtein distance metric performs on par if not better than common model-based metrics like BertScore. All our findings and annotations are open-sourced.
PriMock57: A Dataset Of Primary Care Mock Consultations
Apr 01, 2022



Recent advances in Automatic Speech Recognition (ASR) have made it possible to reliably produce automatic transcripts of clinician-patient conversations. However, access to clinical datasets is heavily restricted due to patient privacy, thus slowing down normal research practices. We detail the development of a public access, high quality dataset comprising of57 mocked primary care consultations, including audio recordings, their manual utterance-level transcriptions, and the associated consultation notes. Our work illustrates how the dataset can be used as a benchmark for conversational medical ASR as well as consultation note generation from transcripts.
Towards more patient friendly clinical notes through language models and ontologies
Dec 23, 2021



Clinical notes are an efficient way to record patient information but are notoriously hard to decipher for non-experts. Automatically simplifying medical text can empower patients with valuable information about their health, while saving clinicians time. We present a novel approach to automated simplification of medical text based on word frequencies and language modelling, grounded on medical ontologies enriched with layman terms. We release a new dataset of pairs of publicly available medical sentences and a version of them simplified by clinicians. Also, we define a novel text simplification metric and evaluation framework, which we use to conduct a large-scale human evaluation of our method against the state of the art. Our method based on a language model trained on medical forum data generates simpler sentences while preserving both grammar and the original meaning, surpassing the current state of the art.
Towards objectively evaluating the quality of generated medical summaries
Apr 09, 2021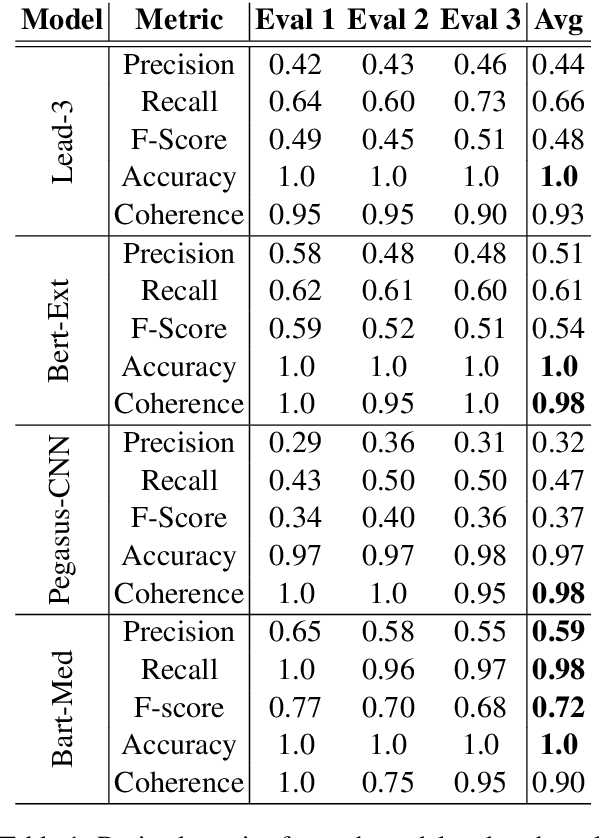

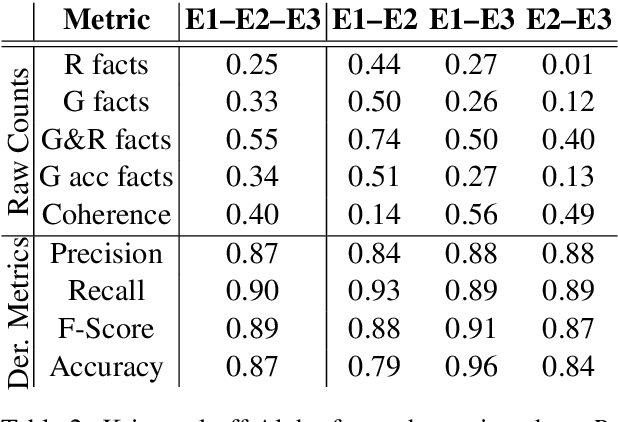

We propose a method for evaluating the quality of generated text by asking evaluators to count facts, and computing precision, recall, f-score, and accuracy from the raw counts. We believe this approach leads to a more objective and easier to reproduce evaluation. We apply this to the task of medical report summarisation, where measuring objective quality and accuracy is of paramount importance.
A preliminary study on evaluating Consultation Notes with Post-Editing
Apr 09, 2021



Automatic summarisation has the potential to aid physicians in streamlining clerical tasks such as note taking. But it is notoriously difficult to evaluate these systems and demonstrate that they are safe to be used in a clinical setting. To circumvent this issue, we propose a semi-automatic approach whereby physicians post-edit generated notes before submitting them. We conduct a preliminary study on the time saving of automatically generated consultation notes with post-editing. Our evaluators are asked to listen to mock consultations and to post-edit three generated notes. We time this and find that it is faster than writing the note from scratch. We present insights and lessons learnt from this experiment.
Don't Settle for Average, Go for the Max: Fuzzy Sets and Max-Pooled Word Vectors
Apr 30, 2019



Recent literature suggests that averaged word vectors followed by simple post-processing outperform many deep learning methods on semantic textual similarity tasks. Furthermore, when averaged word vectors are trained supervised on large corpora of paraphrases, they achieve state-of-the-art results on standard STS benchmarks. Inspired by these insights, we push the limits of word embeddings even further. We propose a novel fuzzy bag-of-words (FBoW) representation for text that contains all the words in the vocabulary simultaneously but with different degrees of membership, which are derived from similarities between word vectors. We show that max-pooled word vectors are only a special case of fuzzy BoW and should be compared via fuzzy Jaccard index rather than cosine similarity. Finally, we propose DynaMax, a completely unsupervised and non-parametric similarity measure that dynamically extracts and max-pools good features depending on the sentence pair. This method is both efficient and easy to implement, yet outperforms current baselines on STS tasks by a large margin and is even competitive with supervised word vectors trained to directly optimise cosine similarity.