 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards more patient friendly clinical notes through language models and ontologies
Dec 23, 2021



Clinical notes are an efficient way to record patient information but are notoriously hard to decipher for non-experts. Automatically simplifying medical text can empower patients with valuable information about their health, while saving clinicians time. We present a novel approach to automated simplification of medical text based on word frequencies and language modelling, grounded on medical ontologies enriched with layman terms. We release a new dataset of pairs of publicly available medical sentences and a version of them simplified by clinicians. Also, we define a novel text simplification metric and evaluation framework, which we use to conduct a large-scale human evaluation of our method against the state of the art. Our method based on a language model trained on medical forum data generates simpler sentences while preserving both grammar and the original meaning, surpassing the current state of the art.
Correlations between Word Vector Sets
Oct 07, 2019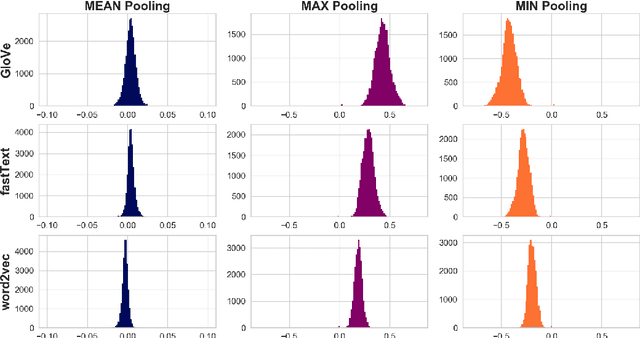
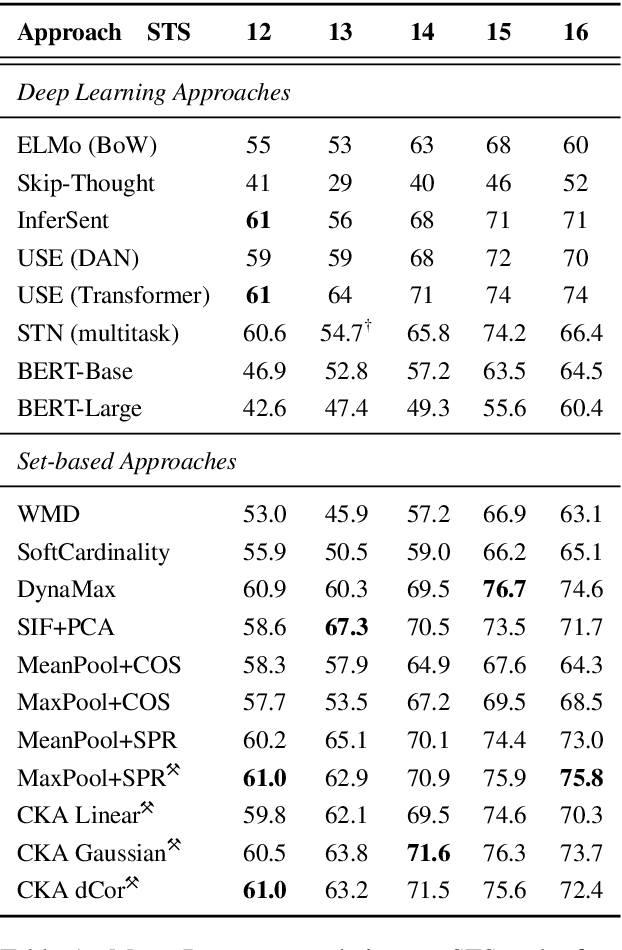
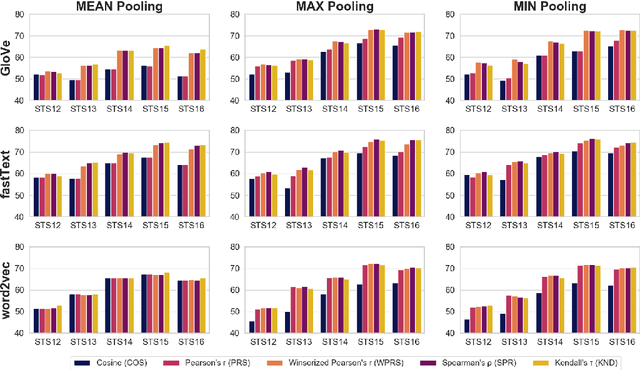

Similarity measures based purely on word embeddings are comfortably competing with much more sophisticated deep learning and expert-engineered systems on unsupervised semantic textual similarity (STS) tasks. In contrast to commonly used geometric approaches, we treat a single word embedding as e.g. 300 observations from a scalar random variable. Using this paradigm, we first illustrate that similarities derived from elementary pooling operations and classic correlation coefficients yield excellent results on standard STS benchmarks, outperforming many recently proposed methods while being much faster and trivial to implement. Next, we demonstrate how to avoid pooling operations altogether and compare sets of word embeddings directly via correlation operators between reproducing kernel Hilbert spaces. Just like cosine similarity is used to compare individual word vectors, we introduce a novel application of the centered kernel alignment (CKA) as a natural generalisation of squared cosine similarity for sets of word vectors. Likewise, CKA is very easy to implement and enjoys very strong empirical results.
Neural Language Priors
Oct 04, 2019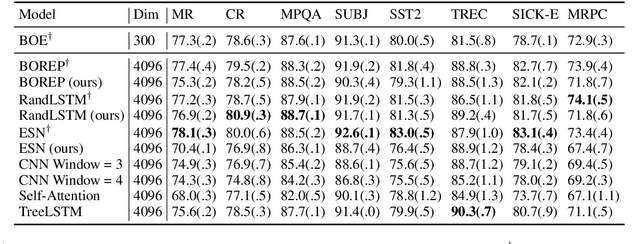
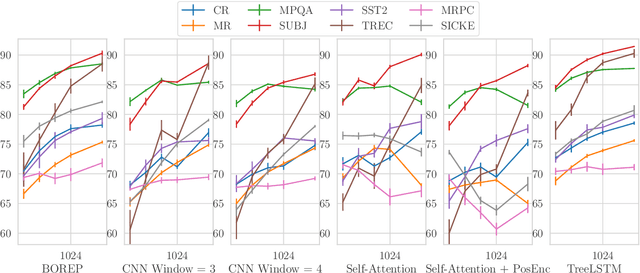
The choice of sentence encoder architecture reflects assumptions about how a sentence's meaning is composed from its constituent words. We examine the contribution of these architectures by holding them randomly initialised and fixed, effectively treating them as as hand-crafted language priors, and evaluating the resulting sentence encoders on downstream language tasks. We find that even when encoders are presented with additional information that can be used to solve tasks, the corresponding priors do not leverage this information, except in an isolated case. We also find that apparently uninformative priors are just as good as seemingly informative priors on almost all tasks, indicating that learning is a necessary component to leverage information provided by architecture choice.
Correlation Coefficients and Semantic Textual Similarity
May 19, 2019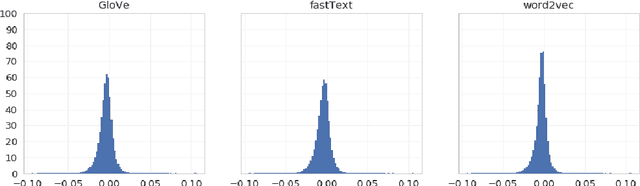
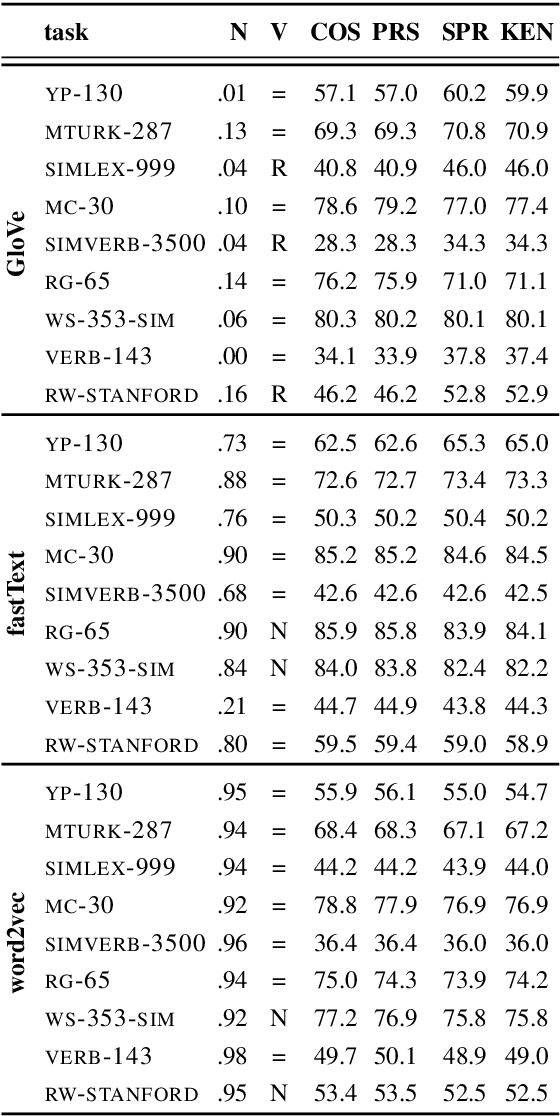
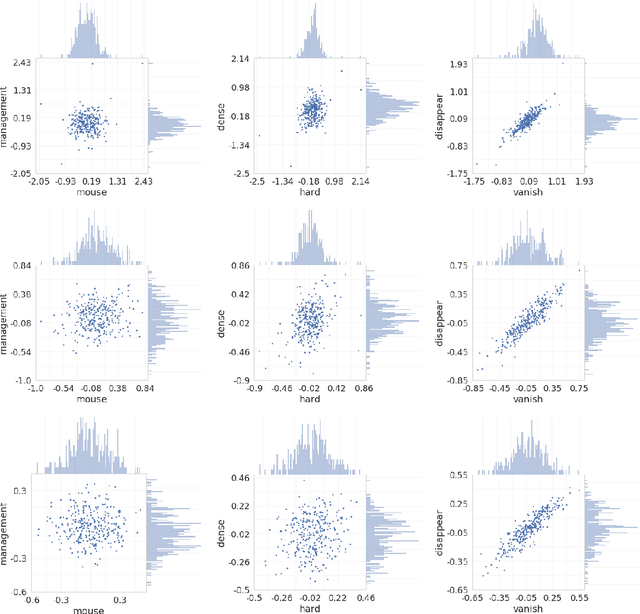
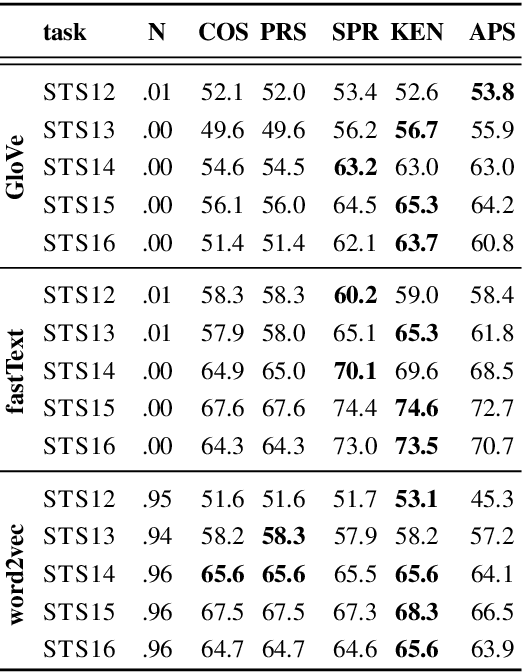
A large body of research into semantic textual similarity has focused on constructing state-of-the-art embeddings using sophisticated modelling, careful choice of learning signals and many clever tricks. By contrast, little attention has been devoted to similarity measures between these embeddings, with cosine similarity being used unquestionably in the majority of cases. In this work, we illustrate that for all common word vectors, cosine similarity is essentially equivalent to the Pearson correlation coefficient, which provides some justification for its use. We thoroughly characterise cases where Pearson correlation (and thus cosine similarity) is unfit as similarity measure. Importantly, we show that Pearson correlation is appropriate for some word vectors but not others. When it is not appropriate, we illustrate how common non-parametric rank correlation coefficients can be used instead to significantly improve performance. We support our analysis with a series of evaluations on word-level and sentence-level semantic textual similarity benchmarks. On the latter, we show that even the simplest averaged word vectors compared by rank correlation easily rival the strongest deep representations compared by cosine similarity.
Don't Settle for Average, Go for the Max: Fuzzy Sets and Max-Pooled Word Vectors
Apr 30, 2019



Recent literature suggests that averaged word vectors followed by simple post-processing outperform many deep learning methods on semantic textual similarity tasks. Furthermore, when averaged word vectors are trained supervised on large corpora of paraphrases, they achieve state-of-the-art results on standard STS benchmarks. Inspired by these insights, we push the limits of word embeddings even further. We propose a novel fuzzy bag-of-words (FBoW) representation for text that contains all the words in the vocabulary simultaneously but with different degrees of membership, which are derived from similarities between word vectors. We show that max-pooled word vectors are only a special case of fuzzy BoW and should be compared via fuzzy Jaccard index rather than cosine similarity. Finally, we propose DynaMax, a completely unsupervised and non-parametric similarity measure that dynamically extracts and max-pools good features depending on the sentence pair. This method is both efficient and easy to implement, yet outperforms current baselines on STS tasks by a large margin and is even competitive with supervised word vectors trained to directly optimise cosine similarity.
Decoding Decoders: Finding Optimal Representation Spaces for Unsupervised Similarity Tasks
May 09, 2018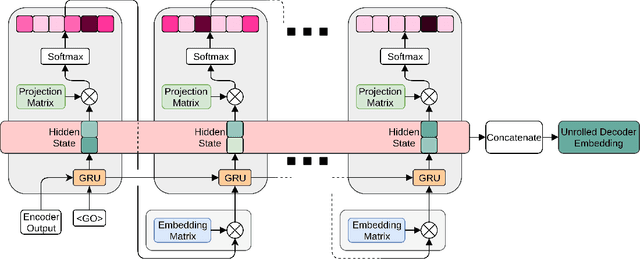
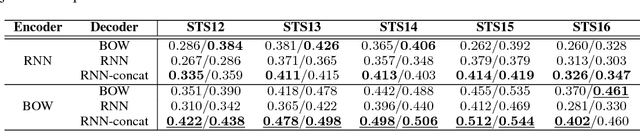
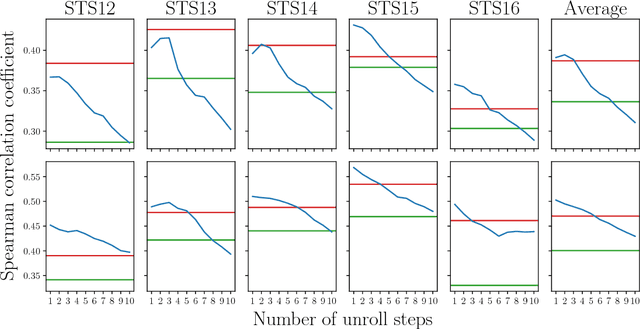

Experimental evidence indicates that simple models outperform complex deep networks on many unsupervised similarity tasks. We provide a simple yet rigorous explanation for this behaviour by introducing the concept of an optimal representation space, in which semantically close symbols are mapped to representations that are close under a similarity measure induced by the model's objective function. In addition, we present a straightforward procedure that, without any retraining or architectural modifications, allows deep recurrent models to perform equally well (and sometimes better) when compared to shallow models. To validate our analysis, we conduct a set of consistent empirical evaluations and introduce several new sentence embedding models in the process. Even though this work is presented within the context of natural language processing, the insights are readily applicable to other domains that rely on distributed representations for transfer tasks.