 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Language Priors
Paper and Code
Oct 04, 2019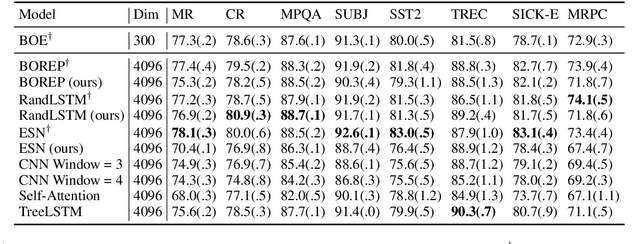
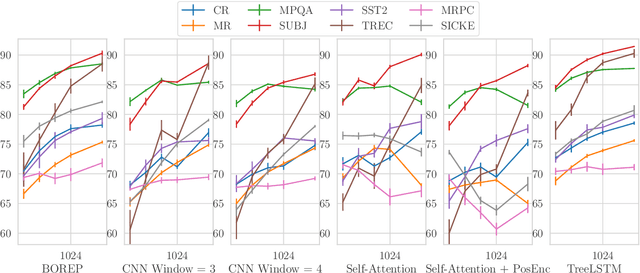
The choice of sentence encoder architecture reflects assumptions about how a sentence's meaning is composed from its constituent words. We examine the contribution of these architectures by holding them randomly initialised and fixed, effectively treating them as as hand-crafted language priors, and evaluating the resulting sentence encoders on downstream language tasks. We find that even when encoders are presented with additional information that can be used to solve tasks, the corresponding priors do not leverage this information, except in an isolated case. We also find that apparently uninformative priors are just as good as seemingly informative priors on almost all tasks, indicating that learning is a necessary component to leverage information provided by architecture choice.