 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrelations between Word Vector Sets
Oct 07, 2019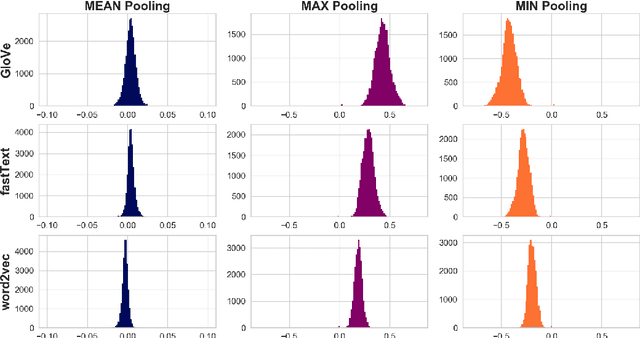
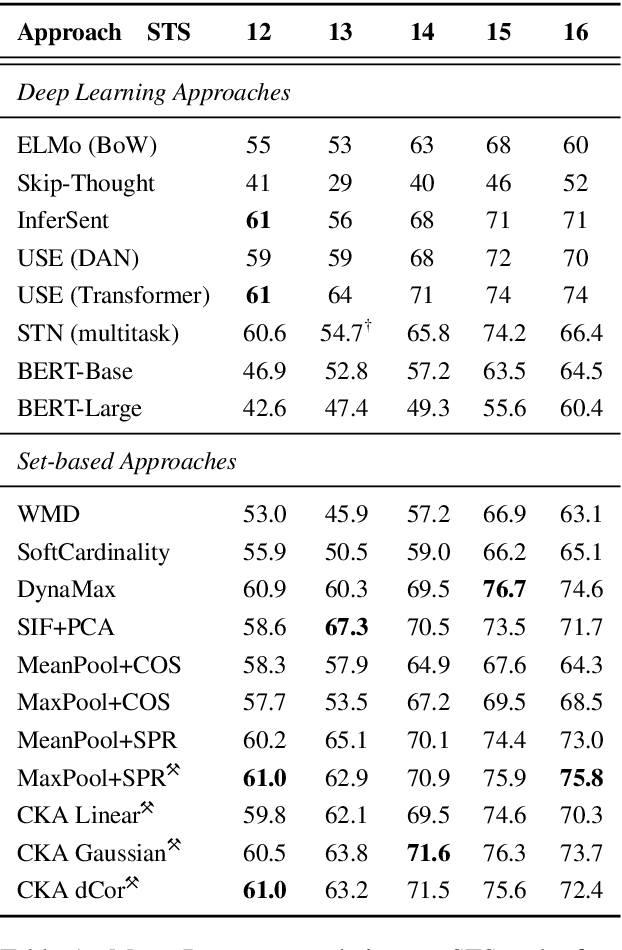
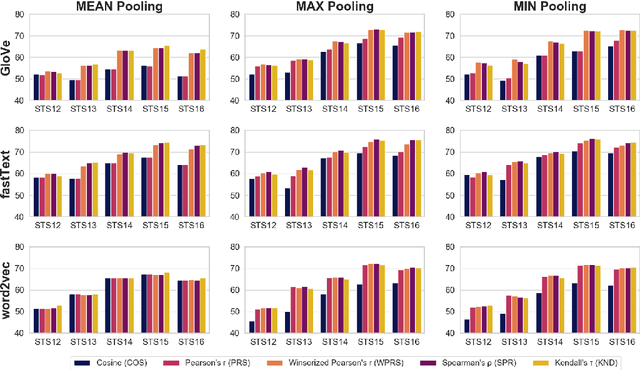

Similarity measures based purely on word embeddings are comfortably competing with much more sophisticated deep learning and expert-engineered systems on unsupervised semantic textual similarity (STS) tasks. In contrast to commonly used geometric approaches, we treat a single word embedding as e.g. 300 observations from a scalar random variable. Using this paradigm, we first illustrate that similarities derived from elementary pooling operations and classic correlation coefficients yield excellent results on standard STS benchmarks, outperforming many recently proposed methods while being much faster and trivial to implement. Next, we demonstrate how to avoid pooling operations altogether and compare sets of word embeddings directly via correlation operators between reproducing kernel Hilbert spaces. Just like cosine similarity is used to compare individual word vectors, we introduce a novel application of the centered kernel alignment (CKA) as a natural generalisation of squared cosine similarity for sets of word vectors. Likewise, CKA is very easy to implement and enjoys very strong empirical results.