 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoBERTa-BiLSTM: A Context-Aware Hybrid Model for Sentiment Analysis
Jun 01, 2024Effectively analyzing the comments to uncover latent intentions holds immense value in making strategic decisions across various domains. However, several challenges hinder the process of sentiment analysis including the lexical diversity exhibited in comments, the presence of long dependencies within the text, encountering unknown symbols and words, and dealing with imbalanced datasets. Moreover, existing sentiment analysis tasks mostly leveraged sequential models to encode the long dependent texts and it requires longer execution time as it processes the text sequentially. In contrast, the Transformer requires less execution time due to its parallel processing nature. In this work, we introduce a novel hybrid deep learning model, RoBERTa-BiLSTM, which combines the Robustly Optimized BERT Pretraining Approach (RoBERTa) with Bidirectional Long Short-Term Memory (BiLSTM) networks. RoBERTa is utilized to generate meaningful word embedding vectors, while BiLSTM effectively captures the contextual semantics of long-dependent texts. The RoBERTa-BiLSTM hybrid model leverages the strengths of both sequential and Transformer models to enhance performance in sentiment analysis. We conducted experiments using datasets from IMDb, Twitter US Airline, and Sentiment140 to evaluate the proposed model against existing state-of-the-art methods. Our experimental findings demonstrate that the RoBERTa-BiLSTM model surpasses baseline models (e.g., BERT, RoBERTa-base, RoBERTa-GRU, and RoBERTa-LSTM), achieving accuracies of 80.74%, 92.36%, and 82.25% on the Twitter US Airline, IMDb, and Sentiment140 datasets, respectively. Additionally, the model achieves F1-scores of 80.73%, 92.35%, and 82.25% on the same datasets, respectively.
Ecological Data Analysis Based on Machine Learning Algorithms
Dec 21, 2018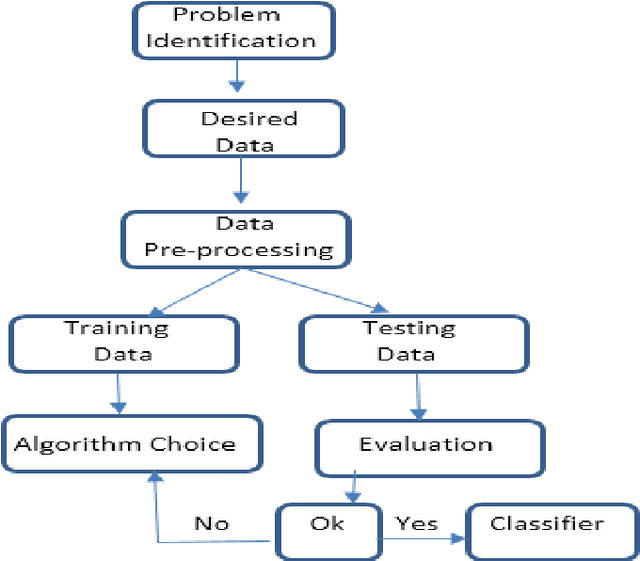


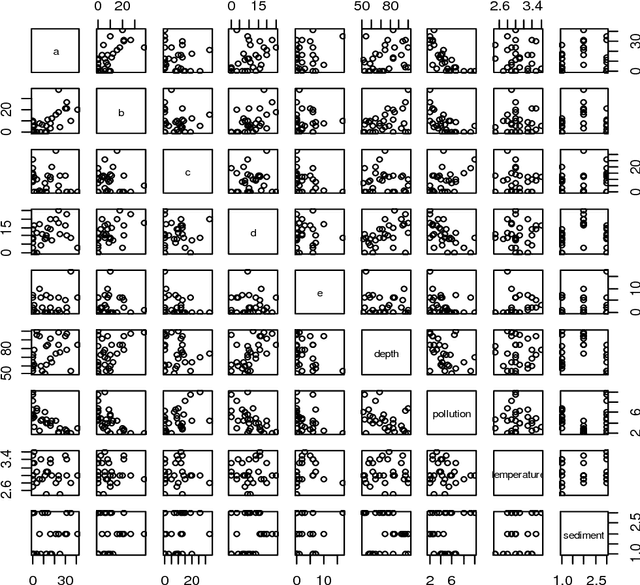
Classification is an important supervised machine learning method, which is necessary and challenging issue for ecological research. It offers a way to classify a dataset into subsets that share common patterns. Notably, there are many classification algorithms to choose from, each making certain assumptions about the data and about how classification should be formed. In this paper, we applied eight machine learning classification algorithms such as Decision Trees, Random Forest, Artificial Neural Network, Support Vector Machine, Linear Discriminant Analysis, k-nearest neighbors, Logistic Regression and Naive Bayes on ecological data. The goal of this study is to compare different machine learning classification algorithms in ecological dataset. In this analysis we have checked the accuracy test among the algorithms. In our study we conclude that Linear Discriminant Analysis and k-nearest neighbors are the best methods among all other methods
Gene Shaving using influence function of a kernel method
Sep 05, 2018
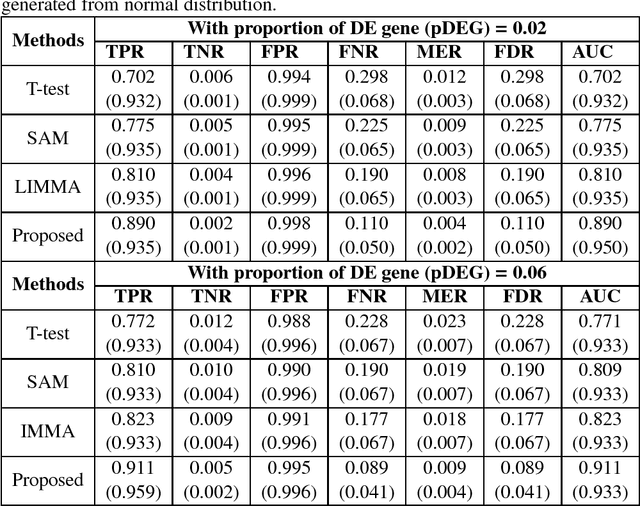

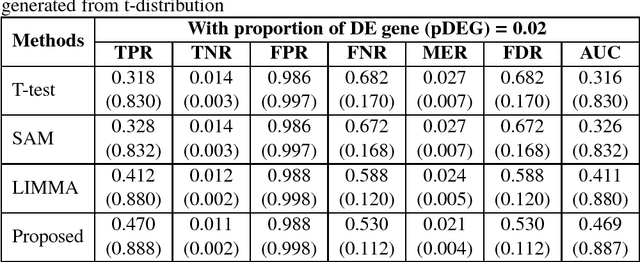
Identifying significant subsets of the genes, gene shaving is an essential and challenging issue for biomedical research for a huge number of genes and the complex nature of biological networks,. Since positive definite kernel based methods on genomic information can improve the prediction of diseases, in this paper we proposed a new method, "kernel gene shaving (kernel canonical correlation analysis (kernel CCA) based gene shaving). This problem is addressed using the influence function of the kernel CCA. To investigate the performance of the proposed method in a comparison of three popular gene selection methods (T-test, SAM and LIMMA), we were used extensive simulated and real microarray gene expression datasets. The performance measures AUC was computed for each of the methods. The achievement of the proposed method has improved than the three well-known gene selection methods. In real data analysis, the proposed method identified a subsets of $210$ genes out of $2000$ genes. The network of these genes has significantly more interactions than expected, which indicates that they may function in a concerted effort on colon cancer.
Kernel Method for Detecting Higher Order Interactions in multi-view Data: An Application to Imaging, Genetics, and Epigenetics
Jul 14, 2017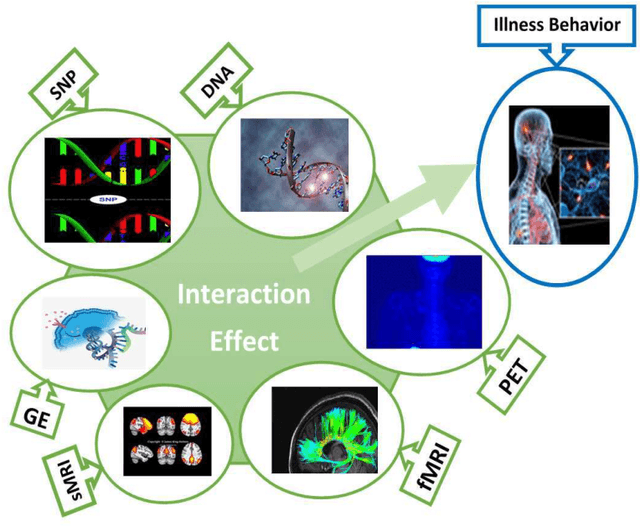
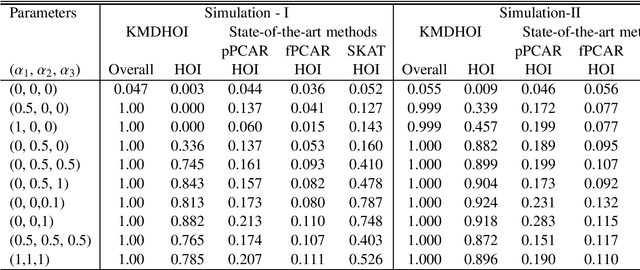

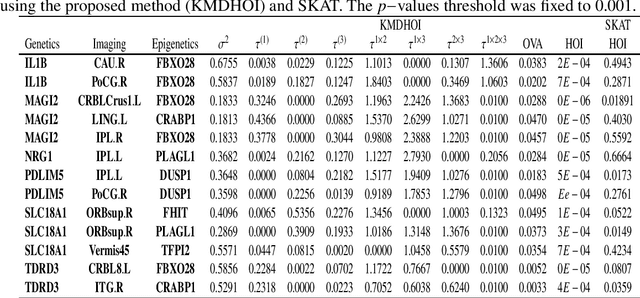
In this study, we tested the interaction effect of multimodal datasets using a novel method called the kernel method for detecting higher order interactions among biologically relevant mulit-view data. Using a semiparametric method on a reproducing kernel Hilbert space (RKHS), we used a standard mixed-effects linear model and derived a score-based variance component statistic that tests for higher order interactions between multi-view data. The proposed method offers an intangible framework for the identification of higher order interaction effects (e.g., three way interaction) between genetics, brain imaging, and epigenetic data. Extensive numerical simulation studies were first conducted to evaluate the performance of this method. Finally, this method was evaluated using data from the Mind Clinical Imaging Consortium (MCIC) including single nucleotide polymorphism (SNP) data, functional magnetic resonance imaging (fMRI) scans, and deoxyribonucleic acid (DNA) methylation data, respectfully, in schizophrenia patients and healthy controls. We treated each gene-derived SNPs, region of interest (ROI) and gene-derived DNA methylation as a single testing unit, which are combined into triplets for evaluation. In addition, cardiovascular disease risk factors such as age, gender, and body mass index were assessed as covariates on hippocampal volume and compared between triplets. Our method identified $13$-triplets ($p$-values $\leq 0.001$) that included $6$ gene-derived SNPs, $10$ ROIs, and $6$ gene-derived DNA methylations that correlated with changes in hippocampal volume, suggesting that these triplets may be important in explaining schizophrenia-related neurodegeneration. With strong evidence ($p$-values $\leq 0.000001$), the triplet ({\bf MAGI2, CRBLCrus1.L, FBXO28}) has the potential to distinguish schizophrenia patients from the healthy control variations.
Influence Function and Robust Variant of Kernel Canonical Correlation Analysis
May 09, 2017
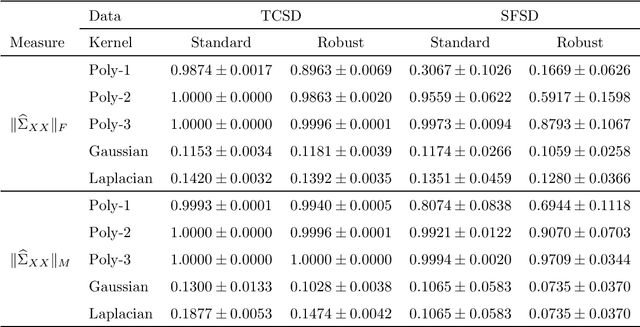


Many unsupervised kernel methods rely on the estimation of the kernel covariance operator (kernel CO) or kernel cross-covariance operator (kernel CCO). Both kernel CO and kernel CCO are sensitive to contaminated data, even when bounded positive definite kernels are used. To the best of our knowledge, there are few well-founded robust kernel methods for statistical unsupervised learning. In addition, while the influence function (IF) of an estimator can characterize its robustness, asymptotic properties and standard error, the IF of a standard kernel canonical correlation analysis (standard kernel CCA) has not been derived yet. To fill this gap, we first propose a robust kernel covariance operator (robust kernel CO) and a robust kernel cross-covariance operator (robust kernel CCO) based on a generalized loss function instead of the quadratic loss function. Second, we derive the IF for robust kernel CCO and standard kernel CCA. Using the IF of the standard kernel CCA, we can detect influential observations from two sets of data. Finally, we propose a method based on the robust kernel CO and the robust kernel CCO, called {\bf robust kernel CCA}, which is less sensitive to noise than the standard kernel CCA. The introduced principles can also be applied to many other kernel methods involving kernel CO or kernel CCO. Our experiments on synthesized data and imaging genetics analysis demonstrate that the proposed IF of standard kernel CCA can identify outliers. It is also seen that the proposed robust kernel CCA method performs better for ideal and contaminated data than the standard kernel CCA.
Learning Schizophrenia Imaging Genetics Data Via Multiple Kernel Canonical Correlation Analysis
Sep 15, 2016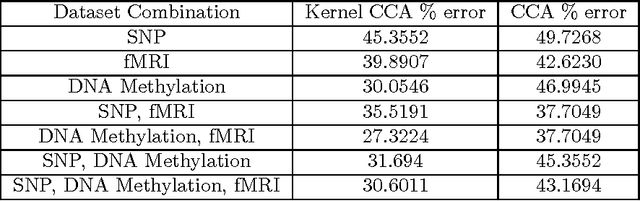
Kernel and Multiple Kernel Canonical Correlation Analysis (CCA) are employed to classify schizophrenic and healthy patients based on their SNPs, DNA Methylation and fMRI data. Kernel and Multiple Kernel CCA are popular methods for finding nonlinear correlations between high-dimensional datasets. Data was gathered from 183 patients, 79 with schizophrenia and 104 healthy controls. Kernel and Multiple Kernel CCA represent new avenues for studying schizophrenia, because, to our knowledge, these methods have not been used on these data before. Classification is performed via k-means clustering on the kernel matrix outputs of the Kernel and Multiple Kernel CCA algorithm. Accuracies of the Kernel and Multiple Kernel CCA classification are compared to that of the regularized linear CCA algorithm classification, and are found to be significantly more accurate. Both algorithms demonstrate maximal accuracies when the combination of DNA methylation and fMRI data are used, and experience lower accuracies when the SNP data are incorporated.
Robust Kernel (Cross-) Covariance Operators in Reproducing Kernel Hilbert Space toward Kernel Methods
Feb 17, 2016
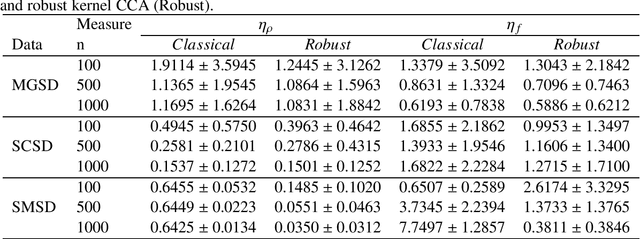
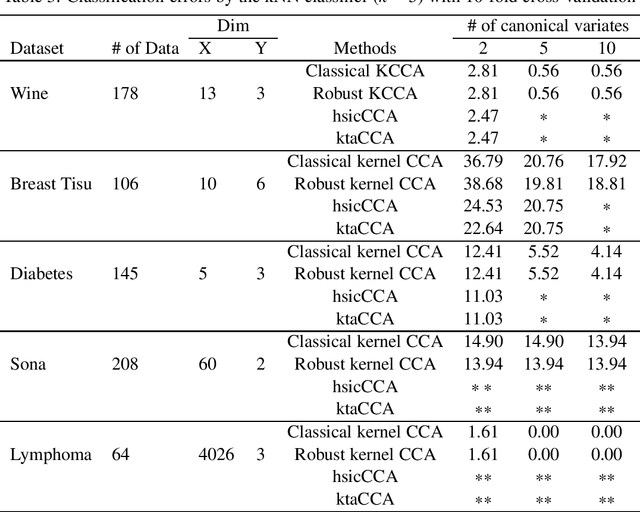

To the best of our knowledge, there are no general well-founded robust methods for statistical unsupervised learning. Most of the unsupervised methods explicitly or implicitly depend on the kernel covariance operator (kernel CO) or kernel cross-covariance operator (kernel CCO). They are sensitive to contaminated data, even when using bounded positive definite kernels. First, we propose robust kernel covariance operator (robust kernel CO) and robust kernel crosscovariance operator (robust kernel CCO) based on a generalized loss function instead of the quadratic loss function. Second, we propose influence function of classical kernel canonical correlation analysis (classical kernel CCA). Third, using this influence function, we propose a visualization method to detect influential observations from two sets of data. Finally, we propose a method based on robust kernel CO and robust kernel CCO, called robust kernel CCA, which is designed for contaminated data and less sensitive to noise than classical kernel CCA. The principles we describe also apply to many kernel methods which must deal with the issue of kernel CO or kernel CCO. Experiments on synthesized and imaging genetics analysis demonstrate that the proposed visualization and robust kernel CCA can be applied effectively to both ideal data and contaminated data. The robust methods show the superior performance over the state-of-the-art methods.