 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Education and Research: An Empirical and User Survey-based Analysis
Dec 08, 2025Pretrained Large Language Models (LLMs) have achieved remarkable success across diverse domains, with education and research emerging as particularly impactful areas. Among current state-of-the-art LLMs, ChatGPT and DeepSeek exhibit strong capabilities in mathematics, science, medicine, literature, and programming. In this study, we present a comprehensive evaluation of these two LLMs through background technology analysis, empirical experiments, and a real-world user survey. The evaluation explores trade-offs among model accuracy, computational efficiency, and user experience in educational and research affairs. We benchmarked these LLMs performance in text generation, programming, and specialized problem-solving. Experimental results show that ChatGPT excels in general language understanding and text generation, while DeepSeek demonstrates superior performance in programming tasks due to its efficiency-focused design. Moreover, both models deliver medically accurate diagnostic outputs and effectively solve complex mathematical problems. Complementing these quantitative findings, a survey of students, educators, and researchers highlights the practical benefits and limitations of these models, offering deeper insights into their role in advancing education and research.
Rule-Based Error Classification for Analyzing Differences in Frequent Errors
Nov 01, 2023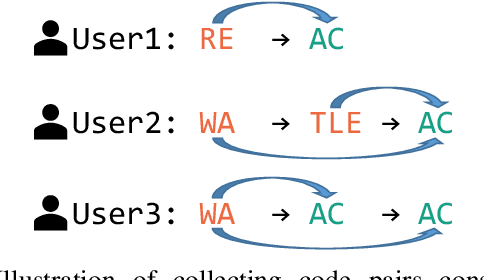
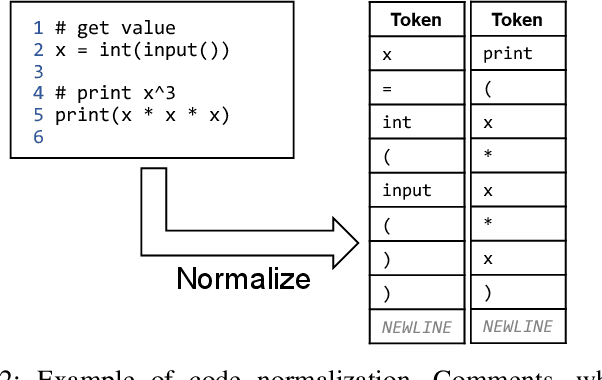
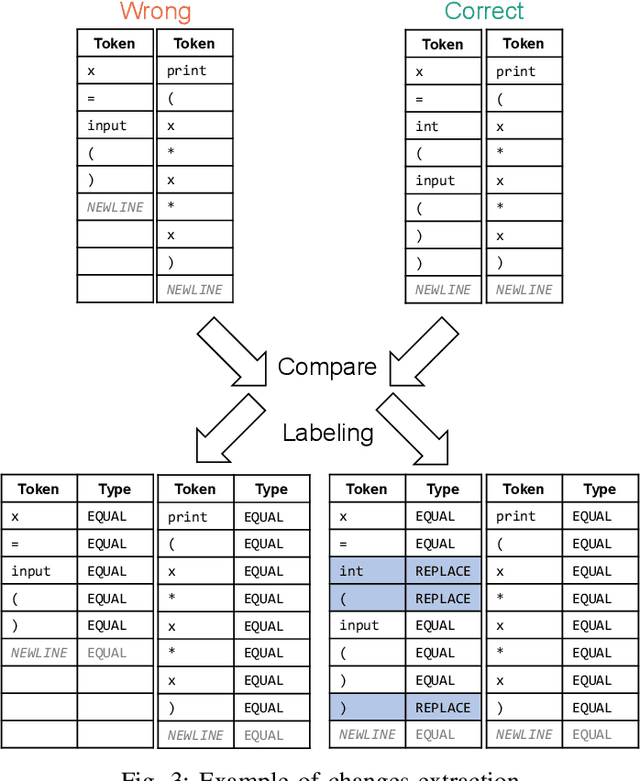

Finding and fixing errors is a time-consuming task not only for novice programmers but also for expert programmers. Prior work has identified frequent error patterns among various levels of programmers. However, the differences in the tendencies between novices and experts have yet to be revealed. From the knowledge of the frequent errors in each level of programmers, instructors will be able to provide helpful advice for each level of learners. In this paper, we propose a rule-based error classification tool to classify errors in code pairs consisting of wrong and correct programs. We classify errors for 95,631 code pairs and identify 3.47 errors on average, which are submitted by various levels of programmers on an online judge system. The classified errors are used to analyze the differences in frequent errors between novice and expert programmers. The analyzed results show that, as for the same introductory problems, errors made by novices are due to the lack of knowledge in programming, and the mistakes are considered an essential part of the learning process. On the other hand, errors made by experts are due to misunderstandings caused by the carelessness of reading problems or the challenges of solving problems differently than usual. The proposed tool can be used to create error-labeled datasets and for further code-related educational research.
Program Repair with Minimal Edits Using CodeT5
Sep 26, 2023Programmers often struggle to identify and fix bugs in their programs. In recent years, many language models (LMs) have been proposed to fix erroneous programs and support error recovery. However, the LMs tend to generate solutions that differ from the original input programs. This leads to potential comprehension difficulties for users. In this paper, we propose an approach to suggest a correct program with minimal repair edits using CodeT5. We fine-tune a pre-trained CodeT5 on code pairs of wrong and correct programs and evaluate its performance with several baseline models. The experimental results show that the fine-tuned CodeT5 achieves a pass@100 of 91.95% and an average edit distance of the most similar correct program of 6.84, which indicates that at least one correct program can be suggested by generating 100 candidate programs. We demonstrate the effectiveness of LMs in suggesting program repair with minimal edits for solving introductory programming problems.