 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplying Data Augmentation to Handwritten Arabic Numeral Recognition Using Deep Learning Neural Networks
Sep 27, 2017

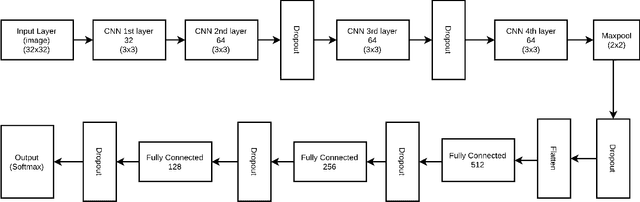
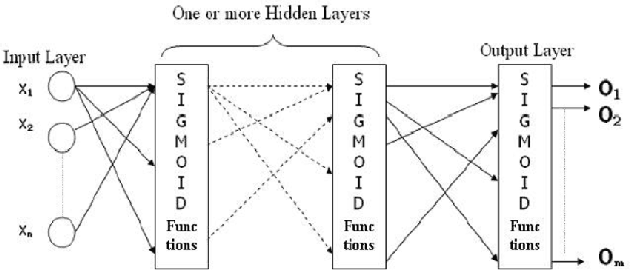
Handwritten character recognition has been the center of research and a benchmark problem in the sector of pattern recognition and artificial intelligence, and it continues to be a challenging research topic. Due to its enormous application many works have been done in this field focusing on different languages. Arabic, being a diversified language has a huge scope of research with potential challenges. A convolutional neural network model for recognizing handwritten numerals in Arabic language is proposed in this paper, where the dataset is subject to various augmentation in order to add robustness needed for deep learning approach. The proposed method is empowered by the presence of dropout regularization to do away with the problem of data overfitting. Moreover, suitable change is introduced in activation function to overcome the problem of vanishing gradient. With these modifications, the proposed system achieves an accuracy of 99.4\% which performs better than every previous work on the dataset.
An Efficient Single Chord-based Accumulation Technique (SCA) to Detect More Reliable Corners
Aug 20, 2017
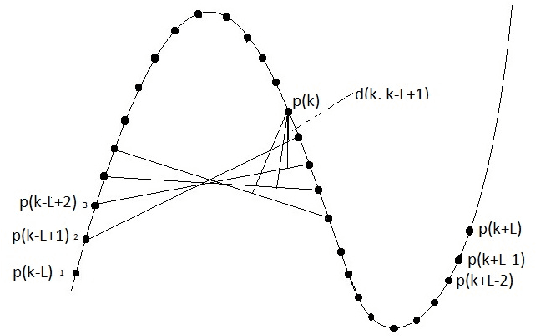


Corner detection is a vital operation in numerous computer vision applications. The Chord-to-Point Distance Accumulation (CPDA) detector is recognized as the contour-based corner detector producing the lowest localization error while localizing corners in an image. However, in our experiment part, we demonstrate that CPDA detector often misses some potential corners. Moreover, the detection algorithm of CPDA is computationally costly. In this paper, We focus on reducing localization error as well as increasing average repeatability. The preprocessing and refinements steps of proposed process are similar to CPDA. Our experimental results will show the effectiveness and robustness of proposed process over CPDA.
Reduction of Overfitting in Diabetes Prediction Using Deep Learning Neural Network
Jul 26, 2017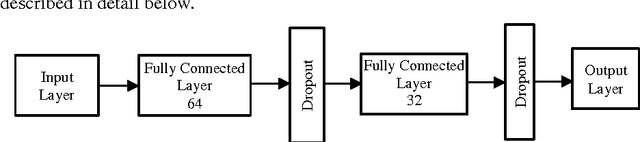
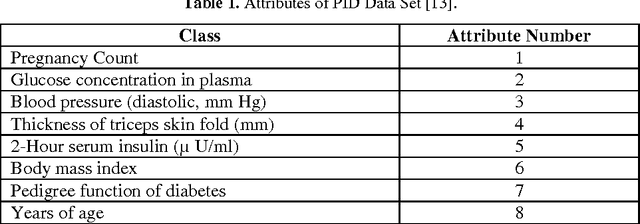
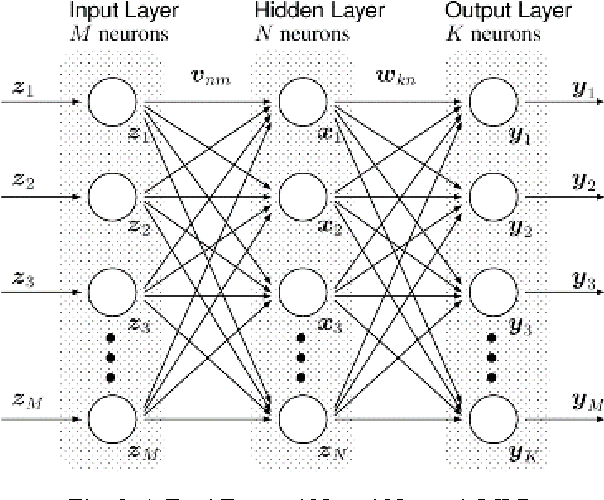
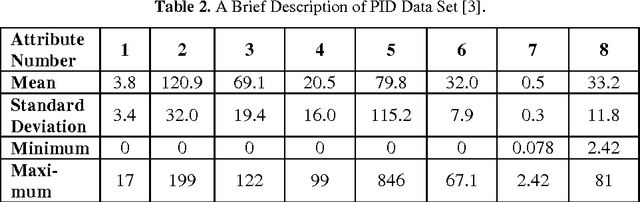
Augmented accuracy in prediction of diabetes will open up new frontiers in health prognostics. Data overfitting is a performance-degrading issue in diabetes prognosis. In this study, a prediction system for the disease of diabetes is pre-sented where the issue of overfitting is minimized by using the dropout method. Deep learning neural network is used where both fully connected layers are fol-lowed by dropout layers. The output performance of the proposed neural network is shown to have outperformed other state-of-art methods and it is recorded as by far the best performance for the Pima Indians Diabetes Data Set.
A Novel Transfer Learning Approach upon Hindi, Arabic, and Bangla Numerals using Convolutional Neural Networks
Jul 26, 2017
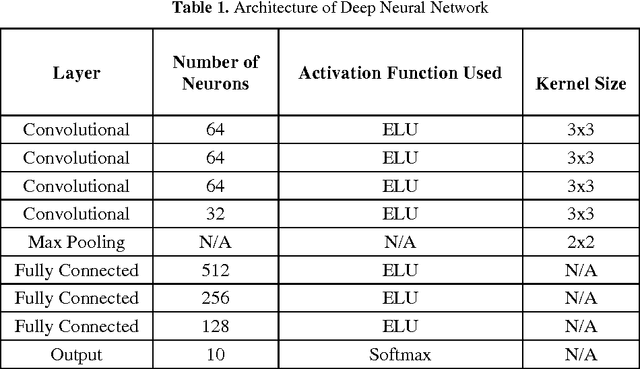

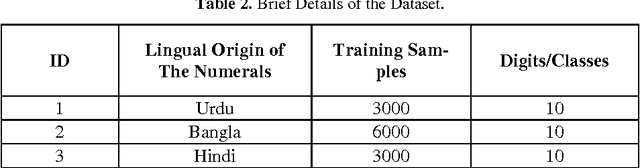
Increased accuracy in predictive models for handwritten character recognition will open up new frontiers for optical character recognition. Major drawbacks of predictive machine learning models are headed by the elongated training time taken by some models, and the requirement that training and test data be in the same feature space and consist of the same distribution. In this study, these obstacles are minimized by presenting a model for transferring knowledge from one task to another. This model is presented for the recognition of handwritten numerals in Indic languages. The model utilizes convolutional neural networks with backpropagation for error reduction and dropout for data overfitting. The output performance of the proposed neural network is shown to have closely matched other state-of-the-art methods using only a fraction of time used by the state-of-the-arts.
Chord Angle Deviation using Tangent (CADT), an Efficient and Robust Contour-based Corner Detector
Feb 16, 2017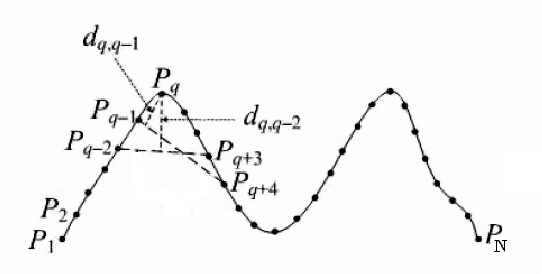

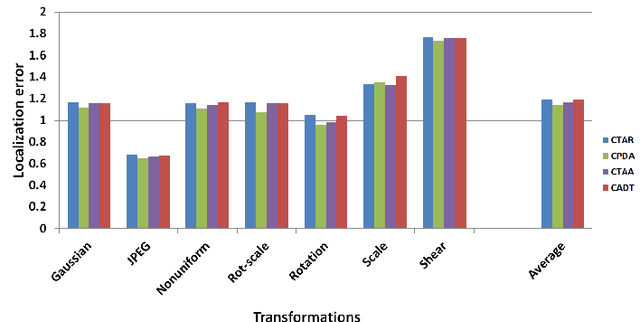
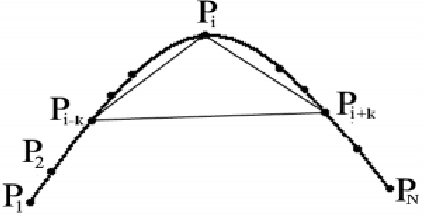
Detection of corner is the most essential process in a large number of computer vision and image processing applications. We have mentioned a number of popular contour-based corner detectors in our paper. Among all these detectors chord to triangular arm angle (CTAA) has been demonstrated as the most dominant corner detector in terms of average repeatability. We introduce a new effective method to calculate the value of curvature in this paper. By demonstrating experimental results, our proposed technique outperforms CTAA and other detectors mentioned in this paper. The results exhibit that our proposed method is simple yet efficient at finding out corners more accurately and reliably.
Handwritten Arabic Numeral Recognition using Deep Learning Neural Networks
Feb 15, 2017Handwritten character recognition is an active area of research with applications in numerous fields. Past and recent works in this field have concentrated on various languages. Arabic is one language where the scope of research is still widespread, with it being one of the most popular languages in the world and being syntactically different from other major languages. Das et al. \cite{DBLP:journals/corr/abs-1003-1891} has pioneered the research for handwritten digit recognition in Arabic. In this paper, we propose a novel algorithm based on deep learning neural networks using appropriate activation function and regularization layer, which shows significantly improved accuracy compared to the existing Arabic numeral recognition methods. The proposed model gives 97.4 percent accuracy, which is the recorded highest accuracy of the dataset used in the experiment. We also propose a modification of the method described in \cite{DBLP:journals/corr/abs-1003-1891}, where our method scores identical accuracy as that of \cite{DBLP:journals/corr/abs-1003-1891}, with the value of 93.8 percent.