 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobilePlantViT: A Mobile-friendly Hybrid ViT for Generalized Plant Disease Image Classification
Mar 20, 2025Plant diseases significantly threaten global food security by reducing crop yields and undermining agricultural sustainability. AI-driven automated classification has emerged as a promising solution, with deep learning models demonstrating impressive performance in plant disease identification. However, deploying these models on mobile and edge devices remains challenging due to high computational demands and resource constraints, highlighting the need for lightweight, accurate solutions for accessible smart agriculture systems. To address this, we propose MobilePlantViT, a novel hybrid Vision Transformer (ViT) architecture designed for generalized plant disease classification, which optimizes resource efficiency while maintaining high performance. Extensive experiments across diverse plant disease datasets of varying scales show our model's effectiveness and strong generalizability, achieving test accuracies ranging from 80% to over 99%. Notably, with only 0.69 million parameters, our architecture outperforms the smallest versions of MobileViTv1 and MobileViTv2, despite their higher parameter counts. These results underscore the potential of our approach for real-world, AI-powered automated plant disease classification in sustainable and resource-efficient smart agriculture systems. All codes will be available in the GitHub repository: https://github.com/moshiurtonmoy/MobilePlantViT
Soybean Disease Detection via Interpretable Hybrid CNN-GNN: Integrating MobileNetV2 and GraphSAGE with Cross-Modal Attention
Mar 03, 2025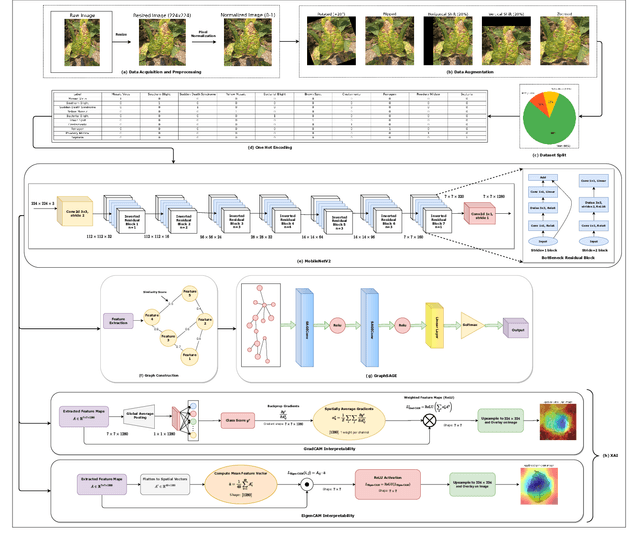
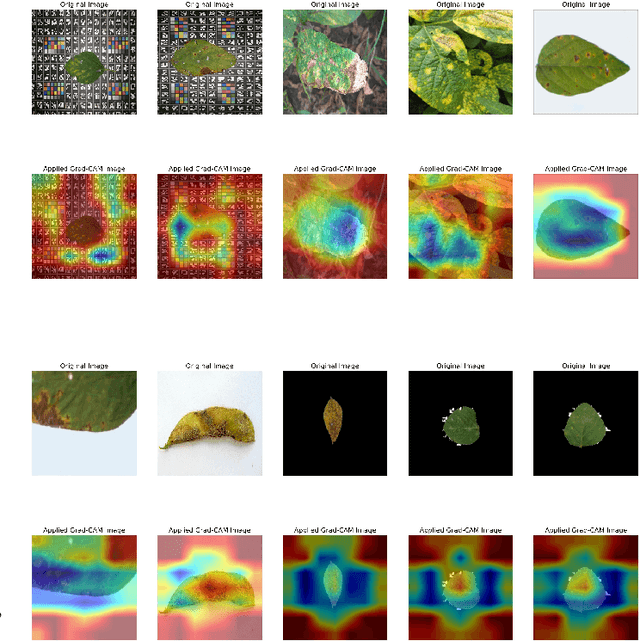
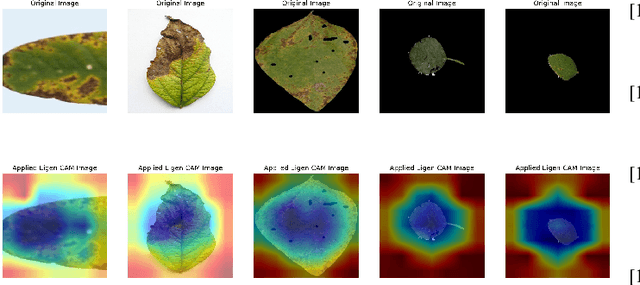
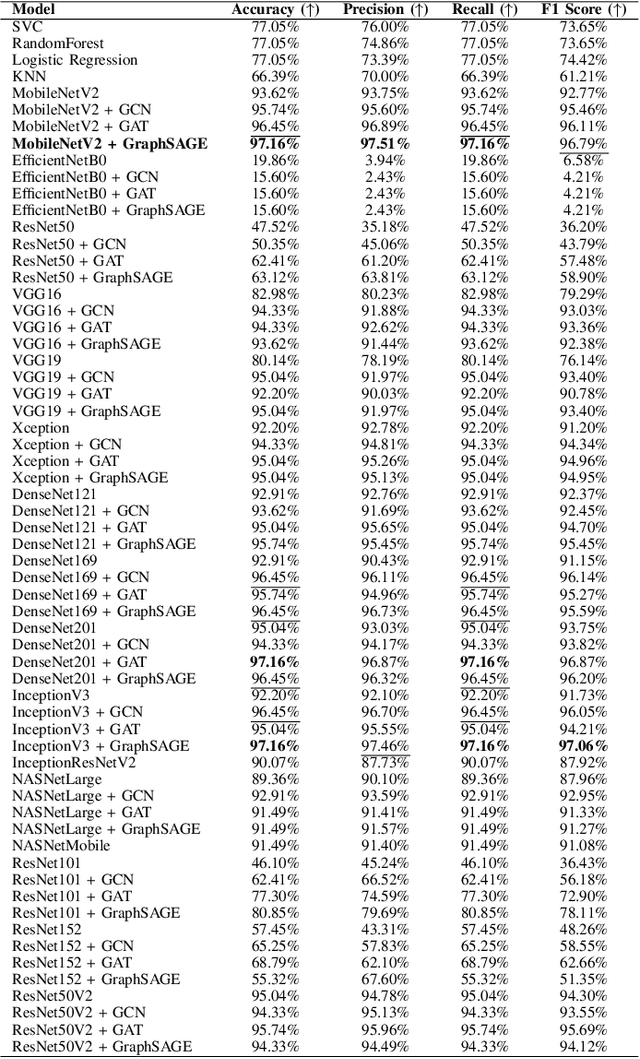
Soybean leaf disease detection is critical for agricultural productivity but faces challenges due to visually similar symptoms and limited interpretability in conventional methods. While Convolutional Neural Networks (CNNs) excel in spatial feature extraction, they often neglect inter-image relational dependencies, leading to misclassifications. This paper proposes an interpretable hybrid Sequential CNN-Graph Neural Network (GNN) framework that synergizes MobileNetV2 for localized feature extraction and GraphSAGE for relational modeling. The framework constructs a graph where nodes represent leaf images, with edges defined by cosine similarity-based adjacency matrices and adaptive neighborhood sampling. This design captures fine-grained lesion features and global symptom patterns, addressing inter-class similarity challenges. Cross-modal interpretability is achieved via Grad-CAM and Eigen-CAM visualizations, generating heatmaps to highlight disease-influential regions. Evaluated on a dataset of ten soybean leaf diseases, the model achieves $97.16\%$ accuracy, surpassing standalone CNNs ($\le95.04\%$) and traditional machine learning models ($\le77.05\%$). Ablation studies validate the sequential architecture's superiority over parallel or single-model configurations. With only 2.3 million parameters, the lightweight MobileNetV2-GraphSAGE combination ensures computational efficiency, enabling real-time deployment in resource-constrained environments. The proposed approach bridges the gap between accurate classification and practical applicability, offering a robust, interpretable tool for agricultural diagnostics while advancing CNN-GNN integration in plant pathology research.
DGNN-YOLO: Interpretable Dynamic Graph Neural Networks with YOLO11 for Small Object Detection and Tracking in Traffic Surveillance
Dec 11, 2024
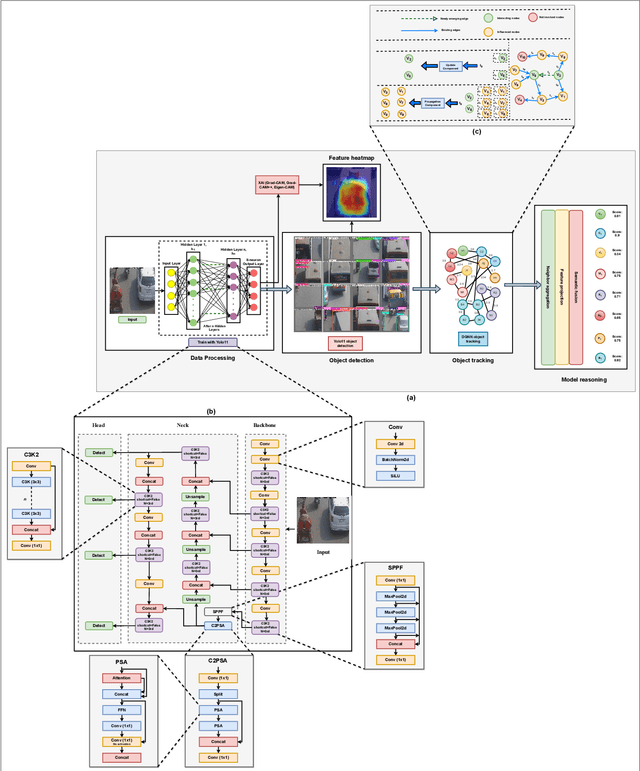
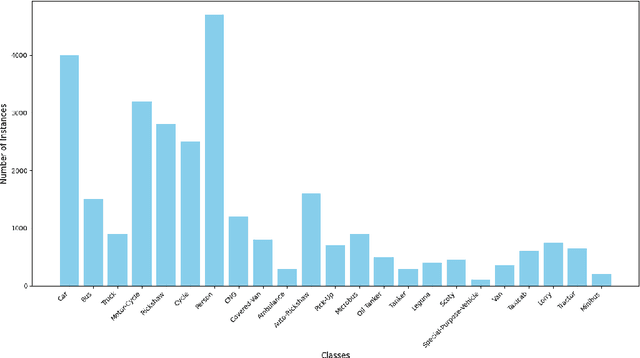
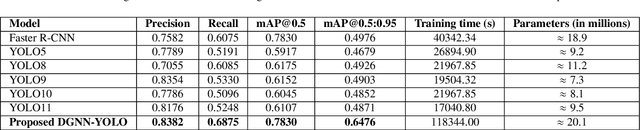
Accurate detection and tracking of small objects, such as pedestrians, cyclists, and motorbikes, is critical for traffic surveillance systems, which are crucial for improving road safety and decision-making in intelligent transportation systems. However, traditional methods face challenges such as occlusion, low resolution, and dynamic traffic conditions, necessitating innovative approaches to address these limitations. This paper introduces DGNN-YOLO, a novel framework integrating dynamic graph neural networks (DGNN) with YOLO11 to enhance small-object detection and tracking in traffic surveillance systems. The framework leverages YOLO11's advanced spatial feature extraction capabilities for precise object detection and incorporates a DGNN to model spatial-temporal relationships for robust real-time tracking dynamically. By constructing and updating graph structures, DGNN-YOLO effectively represents objects as nodes and their interactions as edges, thereby ensuring adaptive and accurate tracking in complex and dynamic environments. Additionally, Grad-CAM, Grad-CAM++, and Eigen-CAM visualization techniques were applied to DGNN-YOLO to provide model-agnostic interpretability and deeper insights into the model's decision-making process, enhancing its transparency and trustworthiness. Extensive experiments demonstrated that DGNN-YOLO consistently outperformed state-of-the-art methods in detecting and tracking small objects under diverse traffic conditions, achieving the highest precision (0.8382), recall (0.6875), and mAP@0.5:0.95 (0.6476), showing its robustness and scalability, particularly in challenging scenarios involving small and occluded objects. This study provides a scalable, real-time traffic surveillance and analysis solution, significantly contributing to intelligent transportation systems.
A Unified Framework for Evaluating the Effectiveness and Enhancing the Transparency of Explainable AI Methods in Real-World Applications
Dec 05, 2024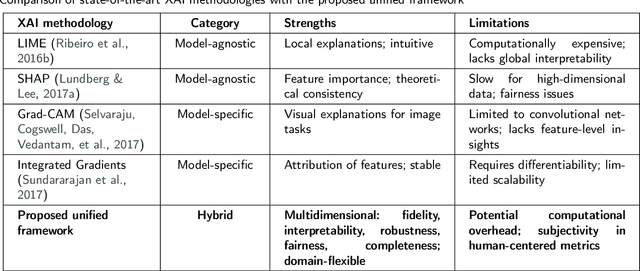
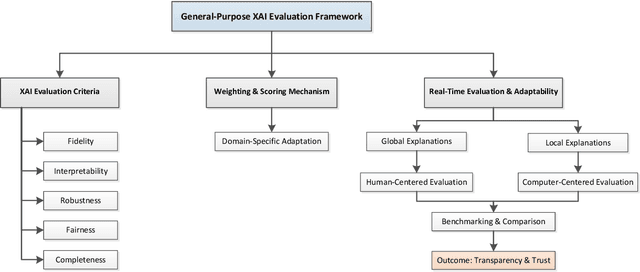
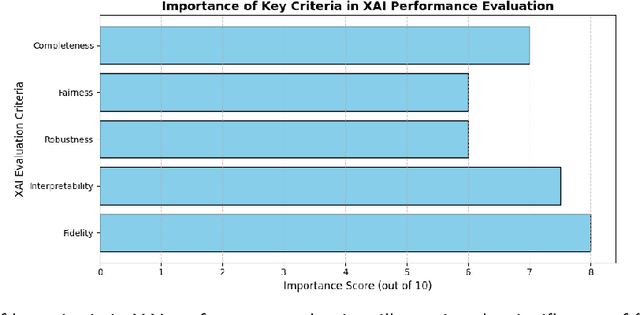
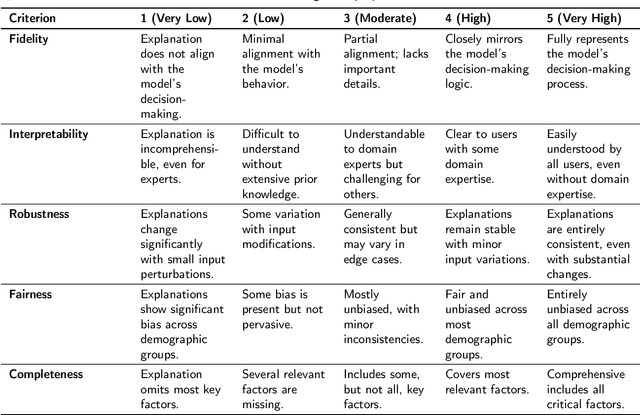
The rapid advancement of deep learning has resulted in substantial advancements in AI-driven applications; however, the "black box" characteristic of these models frequently constrains their interpretability, transparency, and reliability. Explainable artificial intelligence (XAI) seeks to elucidate AI decision-making processes, guaranteeing that explanations faithfully represent the model's rationale and correspond with human comprehension. Despite comprehensive research in XAI, a significant gap persists in standardized procedures for assessing the efficacy and transparency of XAI techniques across many real-world applications. This study presents a unified XAI evaluation framework incorporating extensive quantitative and qualitative criteria to systematically evaluate the correctness, interpretability, robustness, fairness, and completeness of explanations generated by AI models. The framework prioritizes user-centric and domain-specific adaptations, hence improving the usability and reliability of AI models in essential domains. To address deficiencies in existing evaluation processes, we suggest defined benchmarks and a systematic evaluation pipeline that includes data loading, explanation development, and thorough method assessment. The suggested framework's relevance and variety are evidenced by case studies in healthcare, finance, agriculture, and autonomous systems. These provide a solid basis for the equitable and dependable assessment of XAI methodologies. This paradigm enhances XAI research by offering a systematic, flexible, and pragmatic method to guarantee transparency and accountability in AI systems across many real-world contexts.
DGNN-YOLO: Dynamic Graph Neural Networks with YOLO11 for Small Object Detection and Tracking in Traffic Surveillance
Nov 26, 2024Accurate detection and tracking of small objects such as pedestrians, cyclists, and motorbikes are critical for traffic surveillance systems, which are crucial in improving road safety and decision-making in intelligent transportation systems. However, traditional methods struggle with challenges such as occlusion, low resolution, and dynamic traffic conditions, necessitating innovative approaches to address these limitations. This paper introduces DGNN-YOLO, a novel framework integrating dynamic graph neural networks (DGNN) with YOLO11 to enhance small object detection and tracking in traffic surveillance systems. The framework leverages YOLO11's advanced spatial feature extraction capabilities for precise object detection and incorporates DGNN to model spatial-temporal relationships for robust real-time tracking dynamically. By constructing and updating graph structures, DGNN-YOLO effectively represents objects as nodes and their interactions as edges, ensuring adaptive and accurate tracking in complex and dynamic environments. Extensive experiments demonstrate that DGNN-YOLO consistently outperforms state-of-the-art methods in detecting and tracking small objects under diverse traffic conditions, achieving the highest precision (0.8382), recall (0.6875), and mAP@0.5:0.95 (0.6476), showcasing its robustness and scalability, particularly in challenging scenarios involving small and occluded objects. This work provides a scalable, real-time traffic surveillance and analysis solution, significantly contributing to intelligent transportation systems.
Human-in-the-Loop Feature Selection Using Interpretable Kolmogorov-Arnold Network-based Double Deep Q-Network
Nov 06, 2024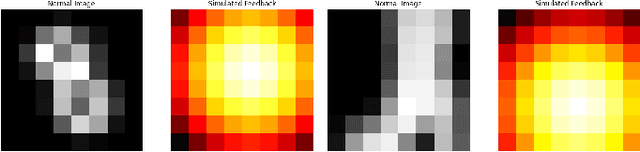
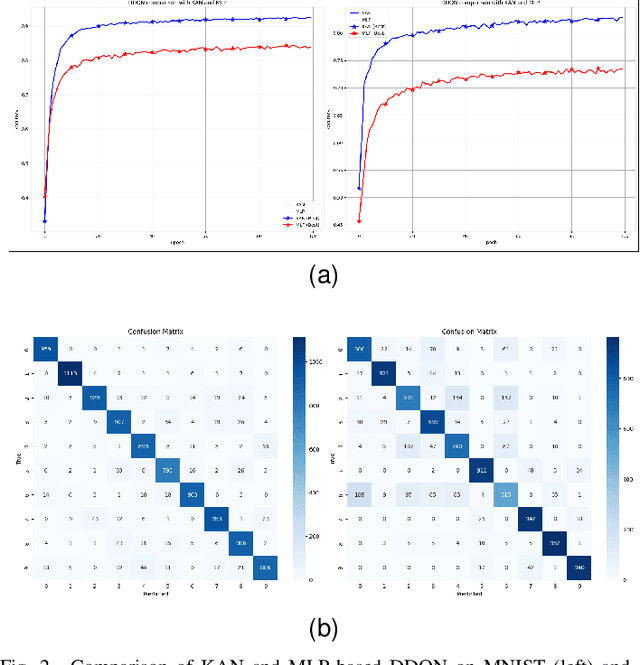
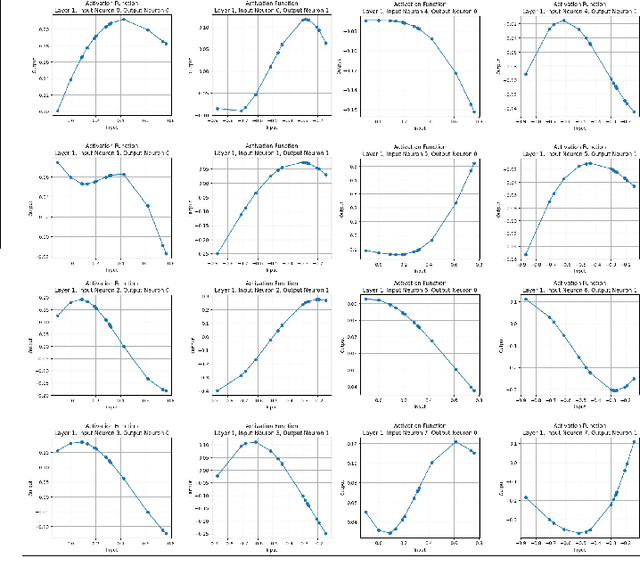
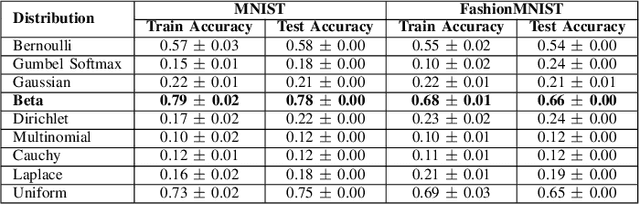
Feature selection is critical for improving the performance and interpretability of machine learning models, particularly in high-dimensional spaces where complex feature interactions can reduce accuracy and increase computational demands. Existing approaches often rely on static feature subsets or manual intervention, limiting adaptability and scalability. However, dynamic, per-instance feature selection methods and model-specific interpretability in reinforcement learning remain underexplored. This study proposes a human-in-the-loop (HITL) feature selection framework integrated into a Double Deep Q-Network (DDQN) using a Kolmogorov-Arnold Network (KAN). Our novel approach leverages simulated human feedback and stochastic distribution-based sampling, specifically Beta, to iteratively refine feature subsets per data instance, improving flexibility in feature selection. The KAN-DDQN achieved notable test accuracies of 93% on MNIST and 83% on FashionMNIST, outperforming conventional MLP-DDQN models by up to 9%. The KAN-based model provided high interpretability via symbolic representation while using 4 times fewer neurons in the hidden layer than MLPs did. Comparatively, the models without feature selection achieved test accuracies of only 58% on MNIST and 64% on FashionMNIST, highlighting significant gains with our framework. Pruning and visualization further enhanced model transparency by elucidating decision pathways. These findings present a scalable, interpretable solution for feature selection that is suitable for applications requiring real-time, adaptive decision-making with minimal human oversight.
Lorentz-Equivariant Quantum Graph Neural Network for High-Energy Physics
Nov 03, 2024



The rapid data surge from the high-luminosity Large Hadron Collider introduces critical computational challenges requiring novel approaches for efficient data processing in particle physics. Quantum machine learning, with its capability to leverage the extensive Hilbert space of quantum hardware, offers a promising solution. However, current quantum graph neural networks (GNNs) lack robustness to noise and are often constrained by fixed symmetry groups, limiting adaptability in complex particle interaction modeling. This paper demonstrates that replacing the Lorentz Group Equivariant Block modules in LorentzNet with a dressed quantum circuit significantly enhances performance despite using nearly 5.5 times fewer parameters. Our Lorentz-Equivariant Quantum Graph Neural Network (Lorentz-EQGNN) achieved 74.00% test accuracy and an AUC of 87.38% on the Quark-Gluon jet tagging dataset, outperforming the classical and quantum GNNs with a reduced architecture using only 4 qubits. On the Electron-Photon dataset, Lorentz-EQGNN reached 67.00% test accuracy and an AUC of 68.20%, demonstrating competitive results with just 800 training samples. Evaluation of our model on generic MNIST and FashionMNIST datasets confirmed Lorentz-EQGNN's efficiency, achieving 88.10% and 74.80% test accuracy, respectively. Ablation studies validated the impact of quantum components on performance, with notable improvements in background rejection rates over classical counterparts. These results highlight Lorentz-EQGNN's potential for immediate applications in noise-resilient jet tagging, event classification, and broader data-scarce HEP tasks.
Quantum Rationale-Aware Graph Contrastive Learning for Jet Discrimination
Nov 03, 2024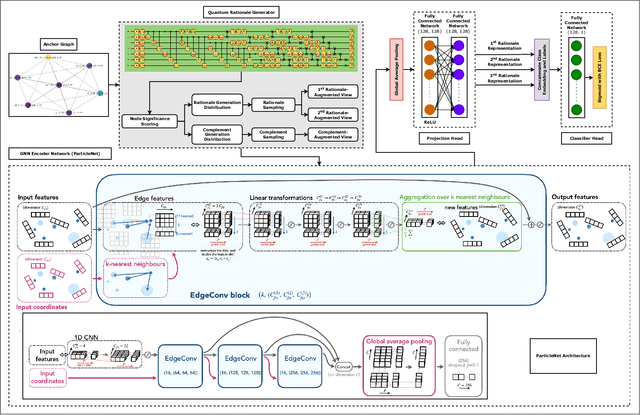
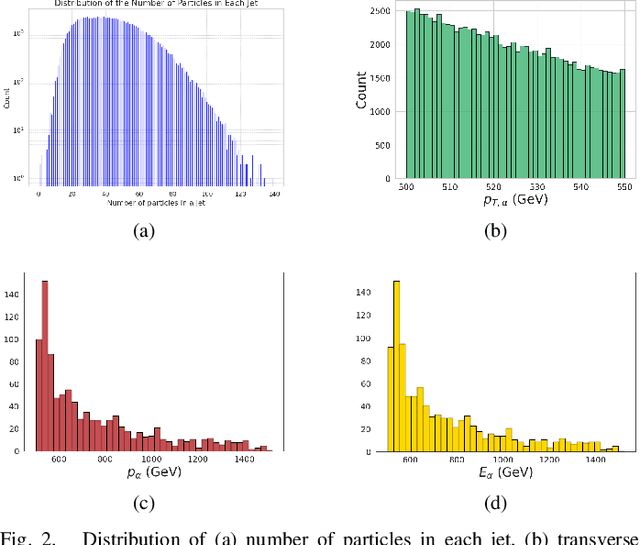
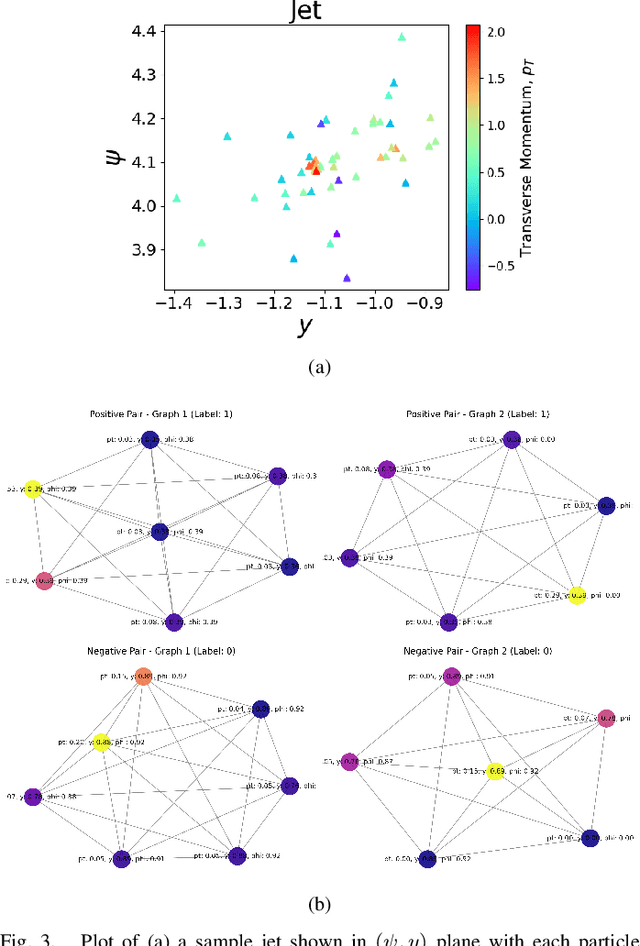
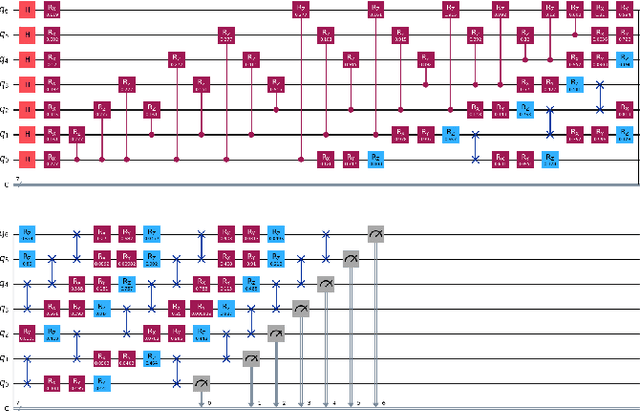
In high-energy physics, particle jet tagging plays a pivotal role in distinguishing quark from gluon jets using data from collider experiments. While graph-based deep learning methods have advanced this task beyond traditional feature-engineered approaches, the complex data structure and limited labeled samples present ongoing challenges. However, existing contrastive learning (CL) frameworks struggle to leverage rationale-aware augmentations effectively, often lacking supervision signals that guide the extraction of salient features and facing computational efficiency issues such as high parameter counts. In this study, we demonstrate that integrating a quantum rationale generator (QRG) within our proposed Quantum Rationale-aware Graph Contrastive Learning (QRGCL) framework significantly enhances jet discrimination performance, reducing reliance on labeled data and capturing discriminative features. Evaluated on the quark-gluon jet dataset, QRGCL achieves an AUC score of 77.53% while maintaining a compact architecture of only 45 QRG parameters, outperforming classical, quantum, and hybrid GCL and GNN benchmarks. These results highlight QRGCL's potential to advance jet tagging and other complex classification tasks in high-energy physics, where computational efficiency and feature extraction limitations persist.
KACQ-DCNN: Uncertainty-Aware Interpretable Kolmogorov-Arnold Classical-Quantum Dual-Channel Neural Network for Heart Disease Detection
Oct 09, 2024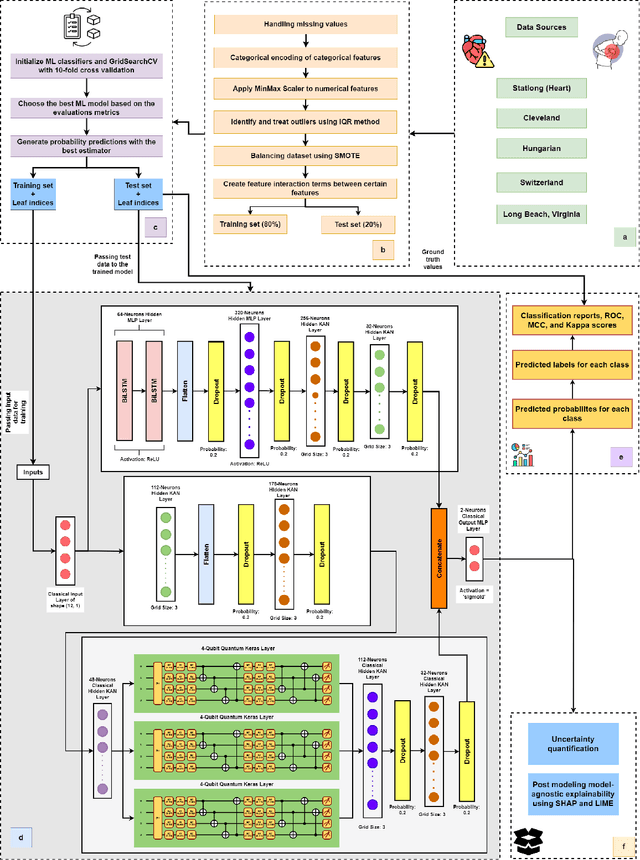

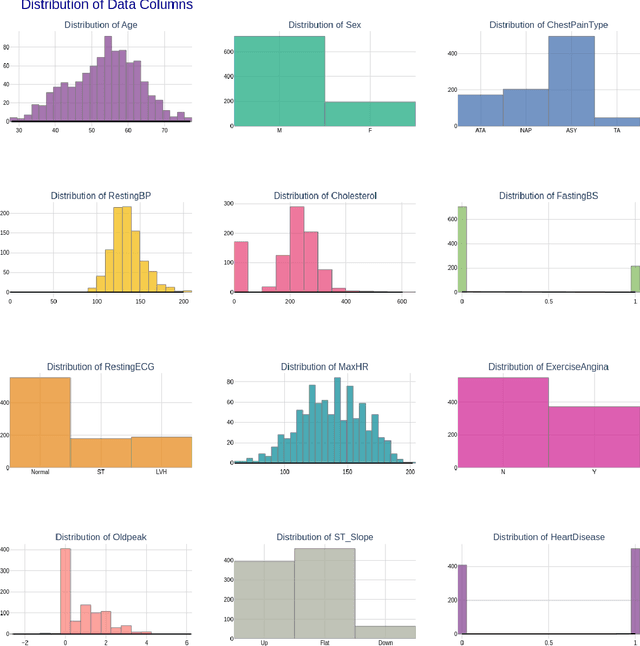

Heart failure remains a major global health challenge, contributing significantly to the 17.8 million annual deaths from cardiovascular disease, highlighting the need for improved diagnostic tools. Current heart disease prediction models based on classical machine learning face limitations, including poor handling of high-dimensional, imbalanced data, limited performance on small datasets, and a lack of uncertainty quantification, while also being difficult for healthcare professionals to interpret. To address these issues, we introduce KACQ-DCNN, a novel classical-quantum hybrid dual-channel neural network that replaces traditional multilayer perceptrons and convolutional layers with Kolmogorov-Arnold Networks (KANs). This approach enhances function approximation with learnable univariate activation functions, reducing model complexity and improving generalization. The KACQ-DCNN 4-qubit 1-layered model significantly outperforms 37 benchmark models across multiple metrics, achieving an accuracy of 92.03%, a macro-average precision, recall, and F1 score of 92.00%, and an ROC-AUC score of 94.77%. Ablation studies demonstrate the synergistic benefits of combining classical and quantum components with KAN. Additionally, explainability techniques like LIME and SHAP provide feature-level insights, improving model transparency, while uncertainty quantification via conformal prediction ensures robust probability estimates. These results suggest that KACQ-DCNN offers a promising path toward more accurate, interpretable, and reliable heart disease predictions, paving the way for advancements in cardiovascular healthcare.
TriQXNet: Forecasting Dst Index from Solar Wind Data Using an Interpretable Parallel Classical-Quantum Framework with Uncertainty Quantification
Jul 10, 2024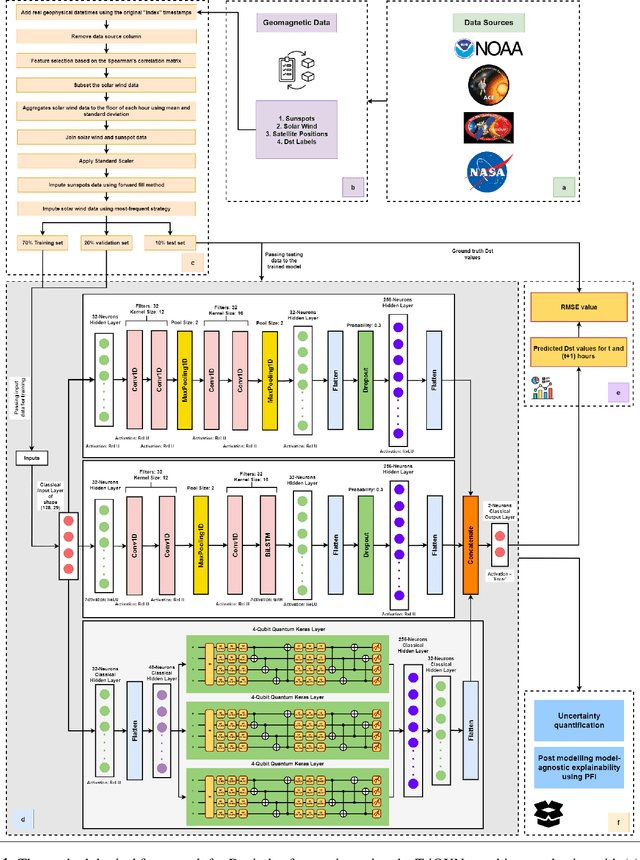
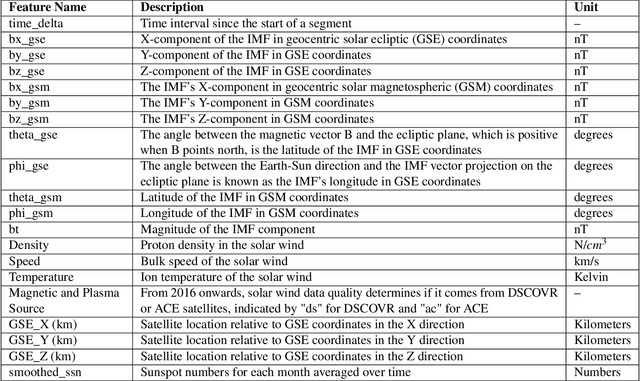
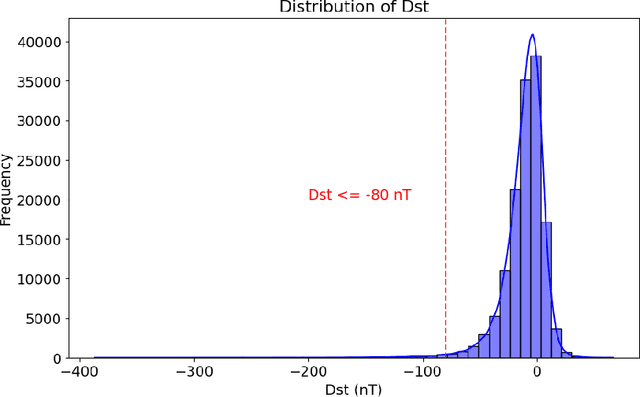

Geomagnetic storms, caused by solar wind energy transfer to Earth's magnetic field, can disrupt critical infrastructure like GPS, satellite communications, and power grids. The disturbance storm-time (Dst) index measures storm intensity. Despite advancements in empirical, physics-based, and machine-learning models using real-time solar wind data, accurately forecasting extreme geomagnetic events remains challenging due to noise and sensor failures. This research introduces TriQXNet, a novel hybrid classical-quantum neural network for Dst forecasting. Our model integrates classical and quantum computing, conformal prediction, and explainable AI (XAI) within a hybrid architecture. To ensure high-quality input data, we developed a comprehensive preprocessing pipeline that included feature selection, normalization, aggregation, and imputation. TriQXNet processes preprocessed solar wind data from NASA's ACE and NOAA's DSCOVR satellites, predicting the Dst index for the current hour and the next, providing vital advance notice to mitigate geomagnetic storm impacts. TriQXNet outperforms 13 state-of-the-art hybrid deep-learning models, achieving a root mean squared error of 9.27 nanoteslas (nT). Rigorous evaluation through 10-fold cross-validated paired t-tests confirmed its superior performance with 95% confidence. Conformal prediction techniques provide quantifiable uncertainty, which is essential for operational decisions, while XAI methods like ShapTime enhance interpretability. Comparative analysis shows TriQXNet's superior forecasting accuracy, setting a new level of expectations for geomagnetic storm prediction and highlighting the potential of classical-quantum hybrid models in space weather forecasting.