 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Framework for Evaluating the Effectiveness and Enhancing the Transparency of Explainable AI Methods in Real-World Applications
Paper and Code
Dec 05, 2024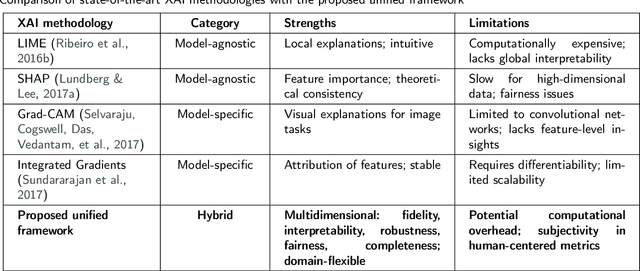
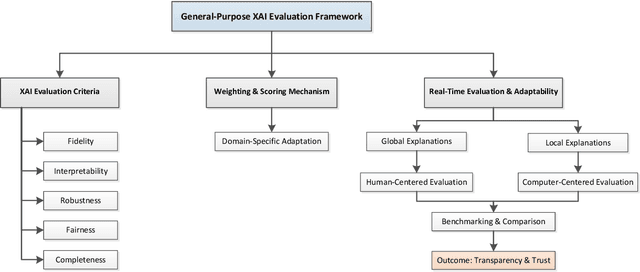
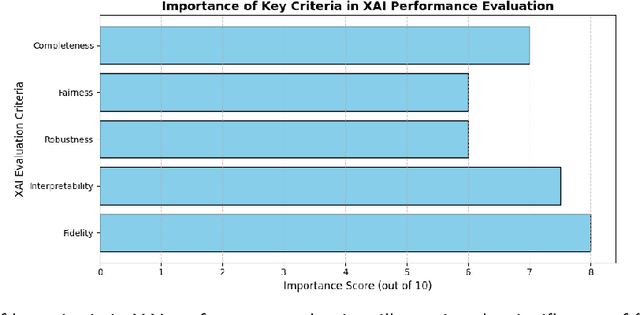
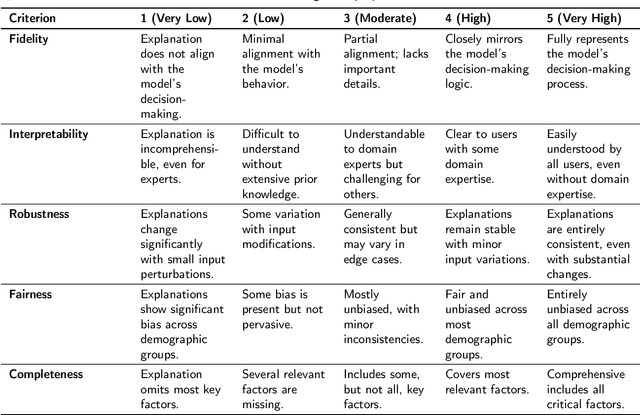
The rapid advancement of deep learning has resulted in substantial advancements in AI-driven applications; however, the "black box" characteristic of these models frequently constrains their interpretability, transparency, and reliability. Explainable artificial intelligence (XAI) seeks to elucidate AI decision-making processes, guaranteeing that explanations faithfully represent the model's rationale and correspond with human comprehension. Despite comprehensive research in XAI, a significant gap persists in standardized procedures for assessing the efficacy and transparency of XAI techniques across many real-world applications. This study presents a unified XAI evaluation framework incorporating extensive quantitative and qualitative criteria to systematically evaluate the correctness, interpretability, robustness, fairness, and completeness of explanations generated by AI models. The framework prioritizes user-centric and domain-specific adaptations, hence improving the usability and reliability of AI models in essential domains. To address deficiencies in existing evaluation processes, we suggest defined benchmarks and a systematic evaluation pipeline that includes data loading, explanation development, and thorough method assessment. The suggested framework's relevance and variety are evidenced by case studies in healthcare, finance, agriculture, and autonomous systems. These provide a solid basis for the equitable and dependable assessment of XAI methodologies. This paradigm enhances XAI research by offering a systematic, flexible, and pragmatic method to guarantee transparency and accountability in AI systems across many real-world contexts.