 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Classification using the Concept of Association Rule of Data Mining
Paper and Code
Sep 23, 2010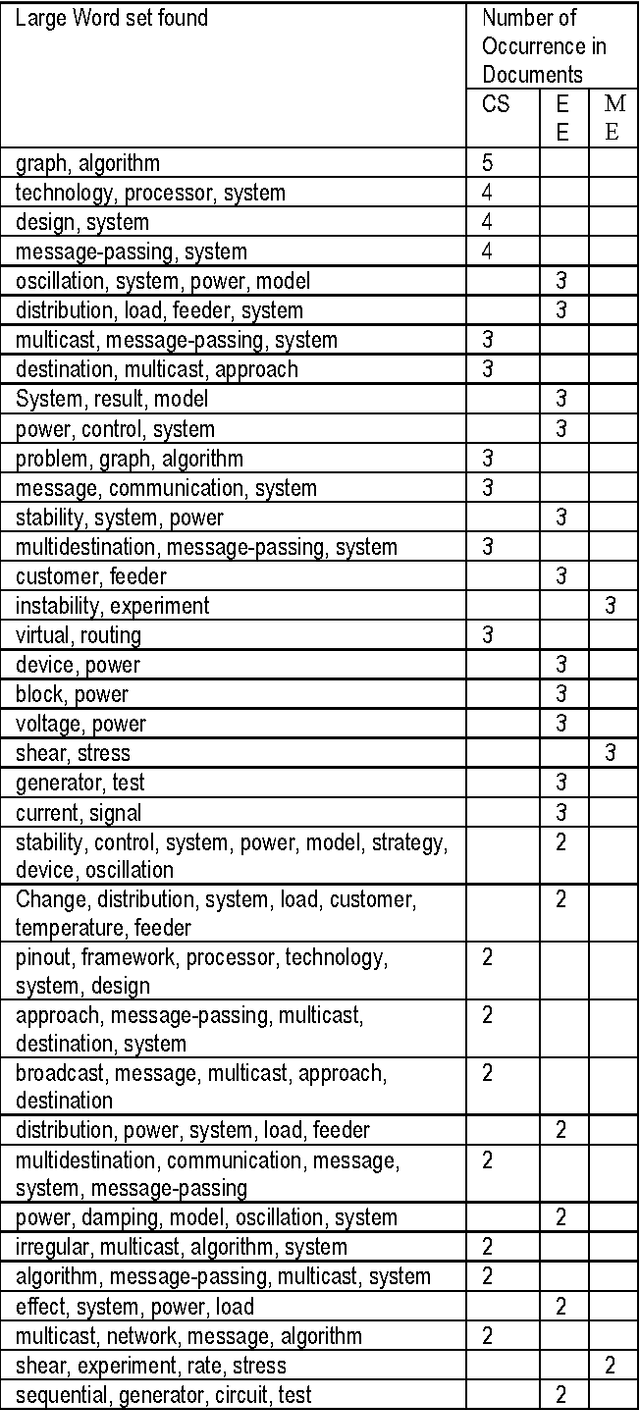
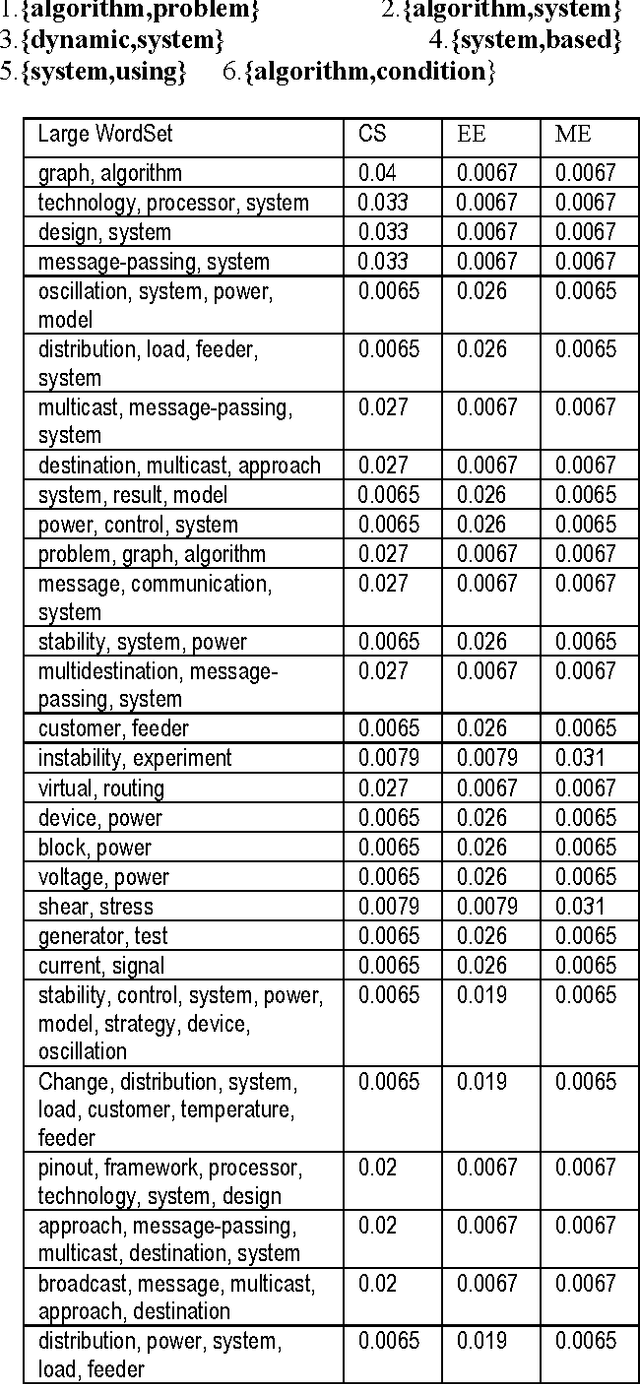
As the amount of online text increases, the demand for text classification to aid the analysis and management of text is increasing. Text is cheap, but information, in the form of knowing what classes a text belongs to, is expensive. Automatic classification of text can provide this information at low cost, but the classifiers themselves must be built with expensive human effort, or trained from texts which have themselves been manually classified. In this paper we will discuss a procedure of classifying text using the concept of association rule of data mining. Association rule mining technique has been used to derive feature set from pre-classified text documents. Naive Bayes classifier is then used on derived features for final classification.