 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Comparison of Text Summarization: A Multi-Dimensional Evaluation of Large Language Models
Apr 06, 2025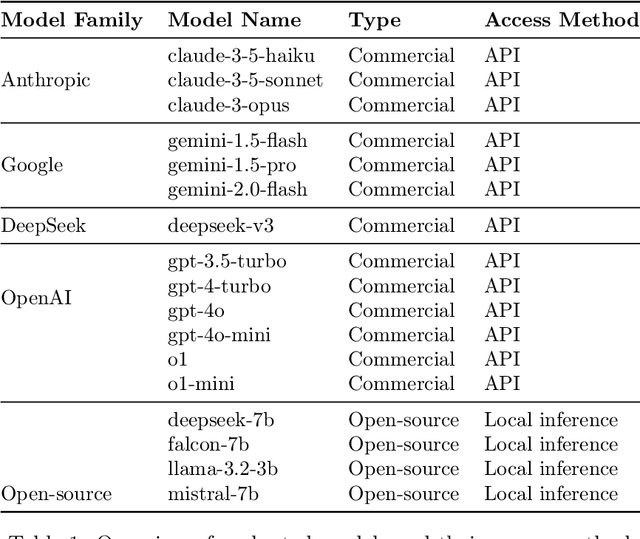
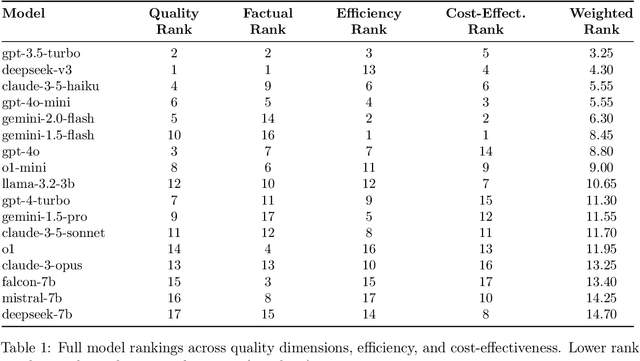
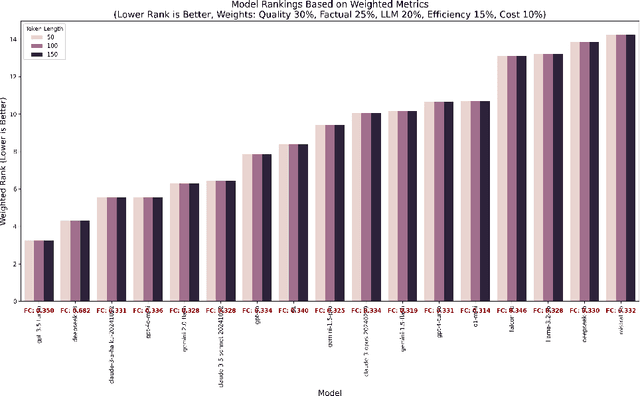
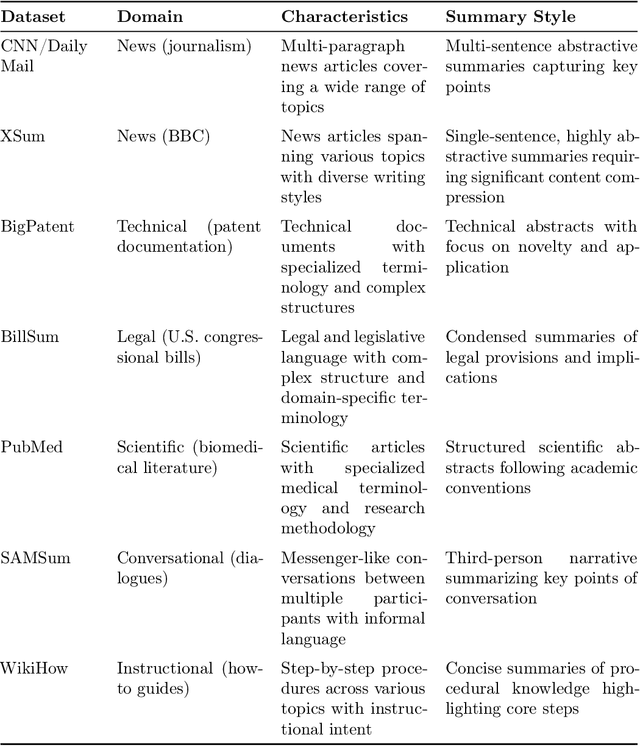
Text summarization is crucial for mitigating information overload across domains like journalism, medicine, and business. This research evaluates summarization performance across 17 large language models (OpenAI, Google, Anthropic, open-source) using a novel multi-dimensional framework. We assessed models on seven diverse datasets (BigPatent, BillSum, CNN/DailyMail, PubMed, SAMSum, WikiHow, XSum) at three output lengths (50, 100, 150 tokens) using metrics for factual consistency, semantic similarity, lexical overlap, and human-like quality, while also considering efficiency factors. Our findings reveal significant performance differences, with specific models excelling in factual accuracy (deepseek-v3), human-like quality (claude-3-5-sonnet), and processing efficiency/cost-effectiveness (gemini-1.5-flash, gemini-2.0-flash). Performance varies dramatically by dataset, with models struggling on technical domains but performing well on conversational content. We identified a critical tension between factual consistency (best at 50 tokens) and perceived quality (best at 150 tokens). Our analysis provides evidence-based recommendations for different use cases, from high-stakes applications requiring factual accuracy to resource-constrained environments needing efficient processing. This comprehensive approach enhances evaluation methodology by integrating quality metrics with operational considerations, incorporating trade-offs between accuracy, efficiency, and cost-effectiveness to guide model selection for specific applications.
Intracranial Hemorrhage Segmentation Using Deep Convolutional Model
Nov 15, 2019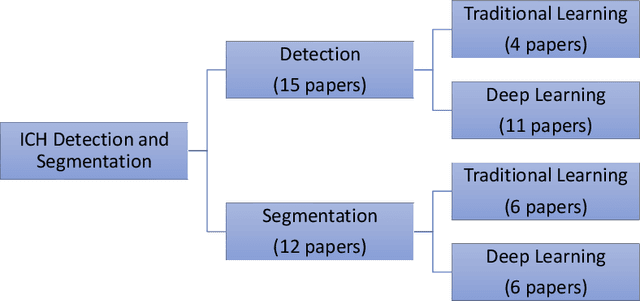
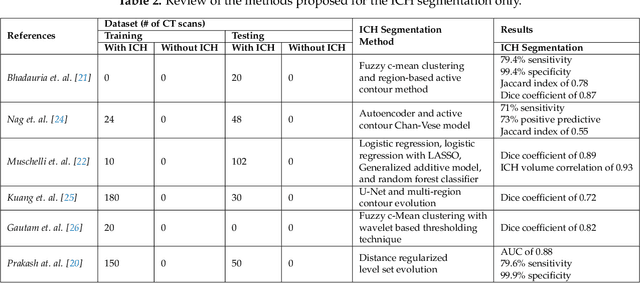
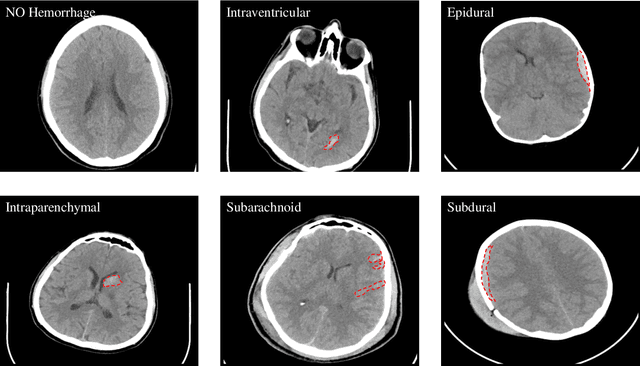
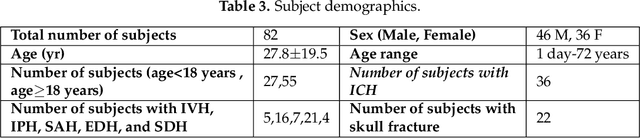
Traumatic brain injuries could cause intracranial hemorrhage (ICH). ICH could lead to disability or death if it is not accurately diagnosed and treated in a time-sensitive procedure. The current clinical protocol to diagnose ICH is examining Computerized Tomography (CT) scans by radiologists to detect ICH and localize its regions. However, this process relies heavily on the availability of an experienced radiologist. In this paper, we designed a study protocol to collect a dataset of 82 CT scans of subjects with traumatic brain injury. Later, the ICH regions were manually delineated in each slice by a consensus decision of two radiologists. Recently, fully convolutional networks (FCN) have shown to be successful in medical image segmentation. We developed a deep FCN, called U-Net, to segment the ICH regions from the CT scans in a fully automated manner. The method achieved a Dice coefficient of 0.31 for the ICH segmentation based on 5-fold cross-validation. The dataset is publicly available online at PhysioNet repository for future analysis and comparison.
Wearable-based Mediation State Detection in Individuals with Parkinson's Disease
Sep 19, 2018
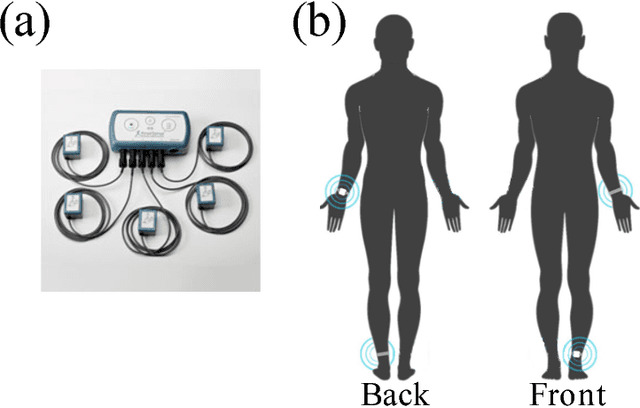
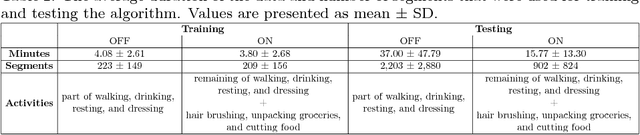
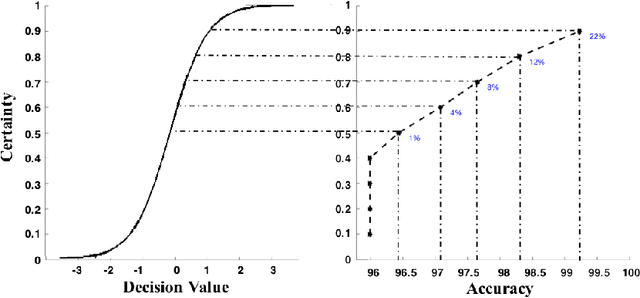
One of the most prevalent complaints of individuals with mid-stage and advanced Parkinson's disease (PD) is the fluctuating response to their medication (i.e., ON state with maximum benefit from medication and OFF state with no benefit from medication). In order to address these motor fluctuations, the patients go through periodic clinical examination where the treating physician reviews the patients' self-report about duration in different medication states and optimize therapy accordingly. Unfortunately, the patients' self-report can be unreliable and suffer from recall bias. There is a need to a technology-based system that can provide objective measures about the duration in different medication states that can be used by the treating physician to successfully adjust the therapy. In this paper, we developed a medication state detection algorithm to detect medication states using two wearable motion sensors. A series of significant features are extracted from the motion data and used in a classifier that is based on a support vector machine with fuzzy labeling. The developed algorithm is evaluated using a dataset with 19 PD subjects and a total duration of 1,052.24 minutes (17.54 hours). The algorithm resulted in an average classification accuracy of 90.5%, sensitivity of 94.2%, and specificity of 85.4%.