 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Comparison of Text Summarization: A Multi-Dimensional Evaluation of Large Language Models
Paper and Code
Apr 06, 2025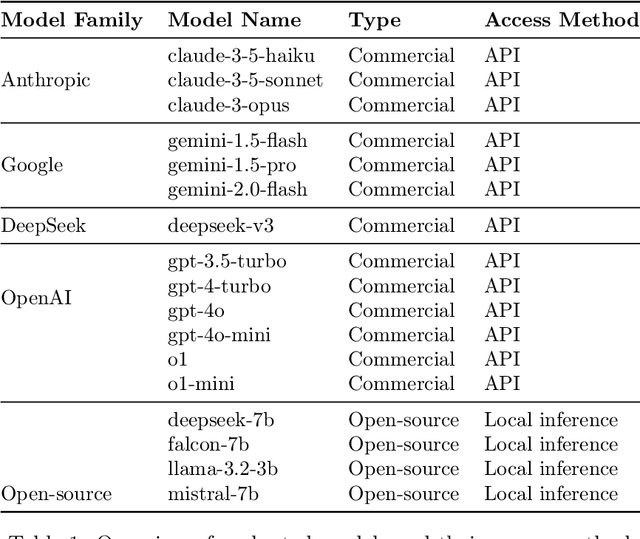
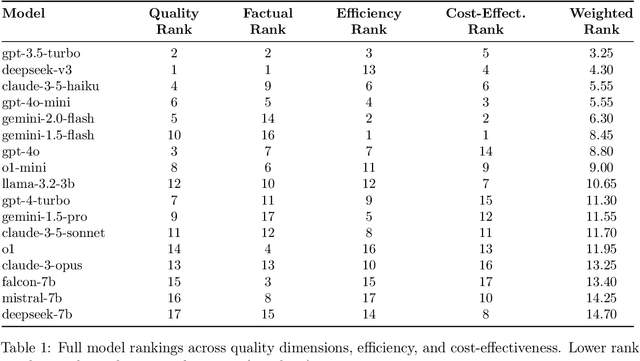
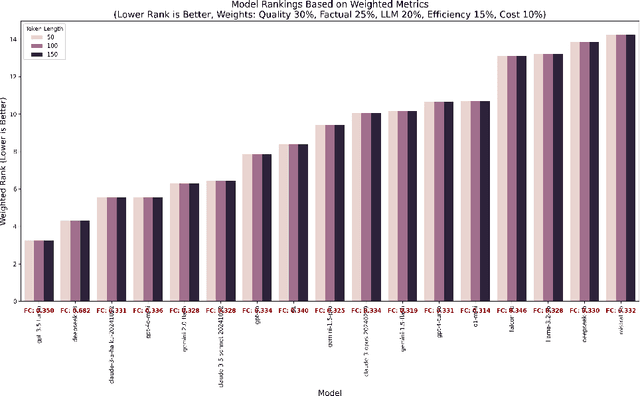
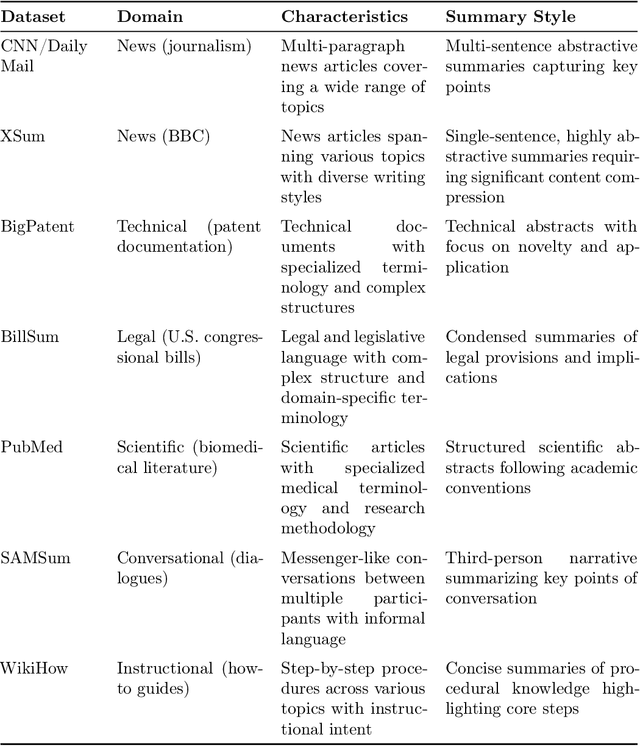
Text summarization is crucial for mitigating information overload across domains like journalism, medicine, and business. This research evaluates summarization performance across 17 large language models (OpenAI, Google, Anthropic, open-source) using a novel multi-dimensional framework. We assessed models on seven diverse datasets (BigPatent, BillSum, CNN/DailyMail, PubMed, SAMSum, WikiHow, XSum) at three output lengths (50, 100, 150 tokens) using metrics for factual consistency, semantic similarity, lexical overlap, and human-like quality, while also considering efficiency factors. Our findings reveal significant performance differences, with specific models excelling in factual accuracy (deepseek-v3), human-like quality (claude-3-5-sonnet), and processing efficiency/cost-effectiveness (gemini-1.5-flash, gemini-2.0-flash). Performance varies dramatically by dataset, with models struggling on technical domains but performing well on conversational content. We identified a critical tension between factual consistency (best at 50 tokens) and perceived quality (best at 150 tokens). Our analysis provides evidence-based recommendations for different use cases, from high-stakes applications requiring factual accuracy to resource-constrained environments needing efficient processing. This comprehensive approach enhances evaluation methodology by integrating quality metrics with operational considerations, incorporating trade-offs between accuracy, efficiency, and cost-effectiveness to guide model selection for specific applications.