 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning achieves radiologist-level performance of tumor segmentation in breast MRI
Sep 21, 2020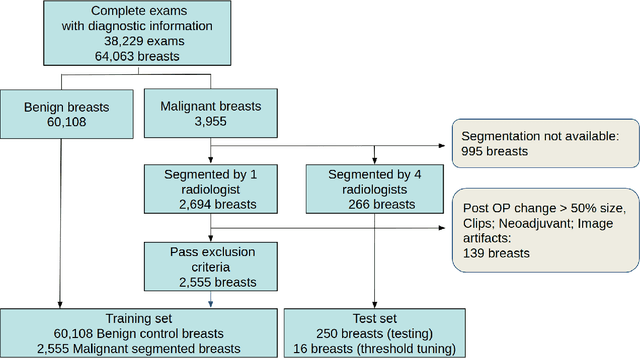
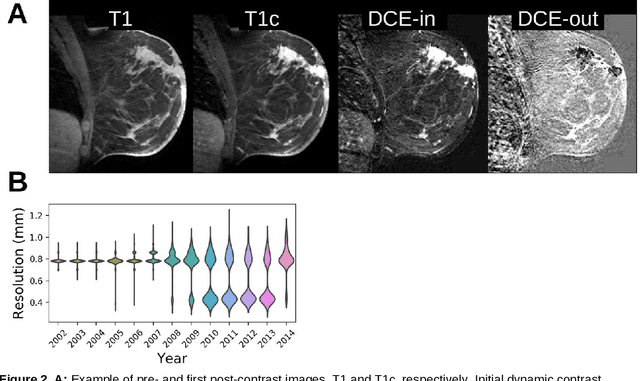
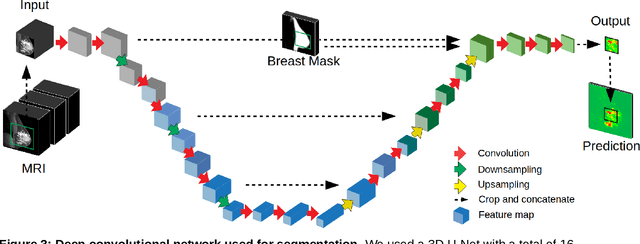
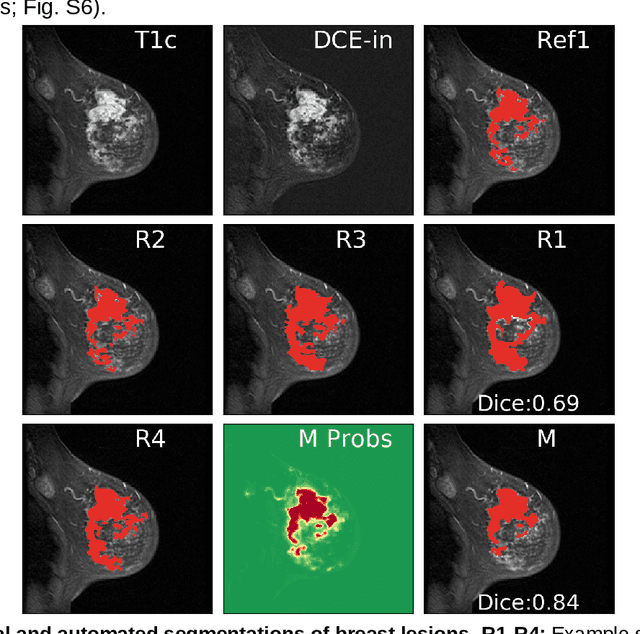
Purpose: The goal of this research was to develop a deep network architecture that achieves fully-automated radiologist-level segmentation of breast tumors in MRI. Materials and Methods: We leveraged 38,229 clinical MRI breast exams collected retrospectively from women aged 12-94 (mean age 54) who presented between 2002 and 2014 at a single clinical site. The training set for the network consisted of 2,555 malignant breasts that were segmented in 2D by experienced radiologists, as well as 60,108 benign breasts that served as negative controls. The test set consisted of 250 exams with tumors segmented independently by four radiologists. We selected among several 3D deep convolutional neural network architectures, input modalities and harmonization methods. The outcome measure was the Dice score for 2D segmentation, and was compared between the network and radiologists using the Wilcoxon signed-rank test and the TOST procedure. Results: The best-performing network on the training set was a volumetric U-Net with contrast enhancement dynamic as input and with intensity normalized for each exam. In the test set the median Dice score of this network was 0.77. The performance of the network was equivalent to that of the radiologists (TOST procedure with radiologist performance of 0.69-0.84 as equivalence bounds: p = 5e-10 and p = 2e-5, respectively; N = 250) and compares favorably with published state of the art (0.6-0.77). Conclusion: When trained on a dataset of over 60 thousand breasts, a volumetric U-Net performs as well as expert radiologists at segmenting malignant breast lesions in MRI.
Assessment of Amazon Comprehend Medical: Medication Information Extraction
Feb 02, 2020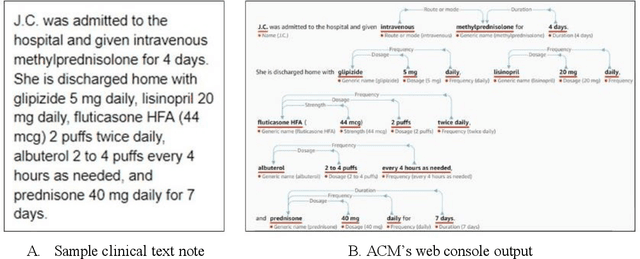
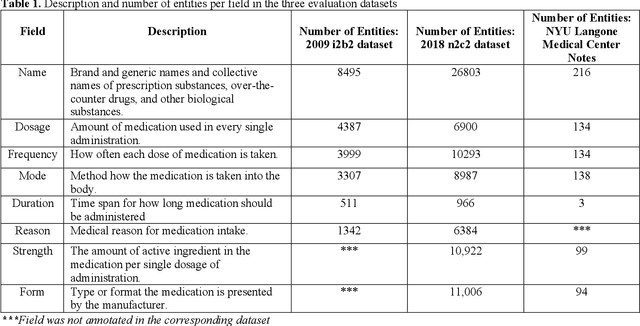

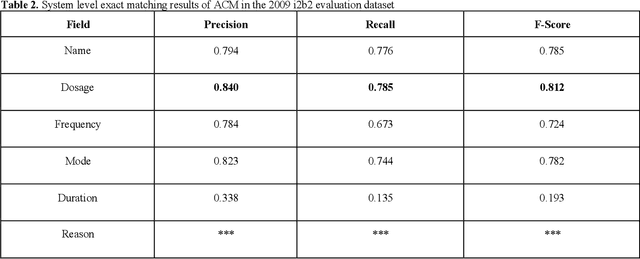
In November 27, 2018, Amazon Web Services (AWS) released Amazon Comprehend Medical (ACM), a deep learning based system that automatically extracts clinical concepts (which include anatomy, medical conditions, protected health information (PH)I, test names, treatment names, and medical procedures, and medications) from clinical text notes. Uptake and trust in any new data product relies on independent validation across benchmark datasets and tools to establish and confirm expected quality of results. This work focuses on the medication extraction task, and particularly, ACM was evaluated using the official test sets from the 2009 i2b2 Medication Extraction Challenge and 2018 n2c2 Track 2: Adverse Drug Events and Medication Extraction in EHRs. Overall, ACM achieved F-scores of 0.768 and 0.828. These scores ranked the lowest when compared to the three best systems in the respective challenges. To further establish the generalizability of its medication extraction performance, a set of random internal clinical text notes from NYU Langone Medical Center were also included in this work. And in this corpus, ACM garnered an F-score of 0.753.