 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixels to Plans: Learning Non-Prehensile Manipulation by Imitating a Planner
Paper and Code
Apr 05, 2019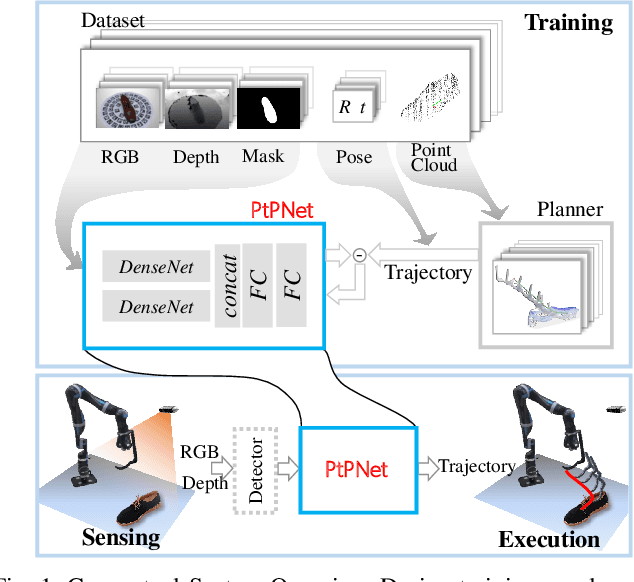
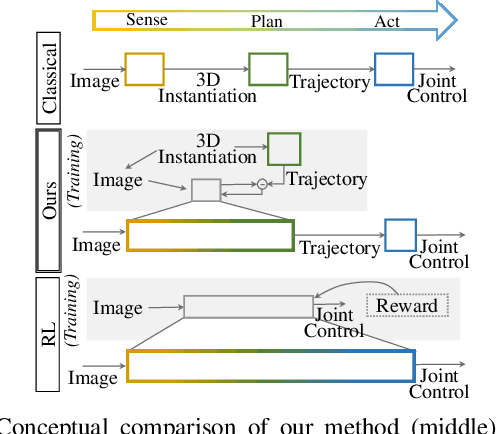
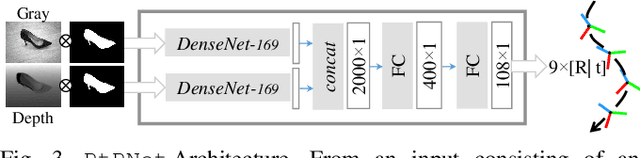
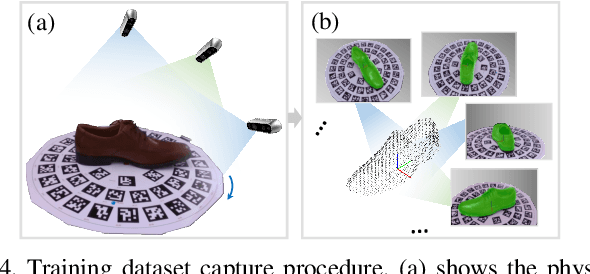
We present a novel method enabling robots to quickly learn to manipulate objects by leveraging a motion planner to generate "expert" training trajectories from a small amount of human-labeled data. In contrast to the traditional sense-plan-act cycle, we propose a deep learning architecture and training regimen called PtPNet that can estimate effective end-effector trajectories for manipulation directly from a single RGB-D image of an object. Additionally, we present a data collection and augmentation pipeline that enables the automatic generation of large numbers (millions) of training image and trajectory examples with almost no human labeling effort. We demonstrate our approach in a non-prehensile tool-based manipulation task, specifically picking up shoes with a hook. In hardware experiments, PtPNet generates motion plans (open-loop trajectories) that reliably (89% success over 189 trials) pick up four very different shoes from a range of positions and orientations, and reliably picks up a shoe it has never seen before. Compared with a traditional sense-plan-act paradigm, our system has the advantages of operating on sparse information (single RGB-D frame), producing high-quality trajectories much faster than the "expert" planner (300ms versus several seconds), and generalizing effectively to previously unseen shoes.