 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Continuous Object Representation Networks for Novel View Synthesis
Paper and Code
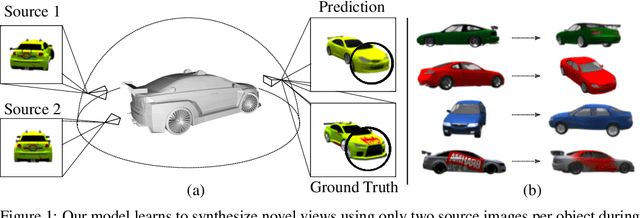
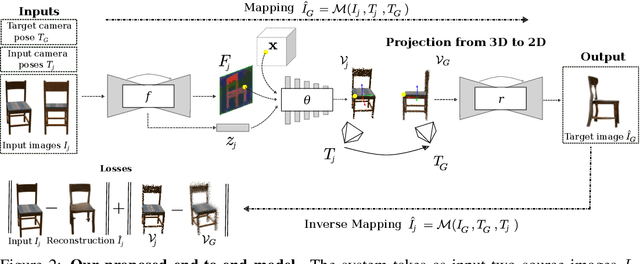


Novel View Synthesis (NVS) is concerned with the generation of novel views of a scene from one or more source images. NVS requires explicit reasoning about 3D object structure and unseen parts of the scene. As a result, current approaches rely on supervised training with either 3D models or multiple target images. We present Unsupervised Continuous Object Representation Networks (UniCORN), which encode the geometry and appearance of a 3D scene using a neural 3D representation. Our model is trained with only two source images per object, requiring no ground truth 3D models or target view supervision. Despite being unsupervised, UniCORN achieves comparable results to the state-of-the-art on challenging tasks, including novel view synthesis and single-view 3D reconstruction.