 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResViT: Residual vision transformers for multi-modal medical image synthesis
Paper and Code
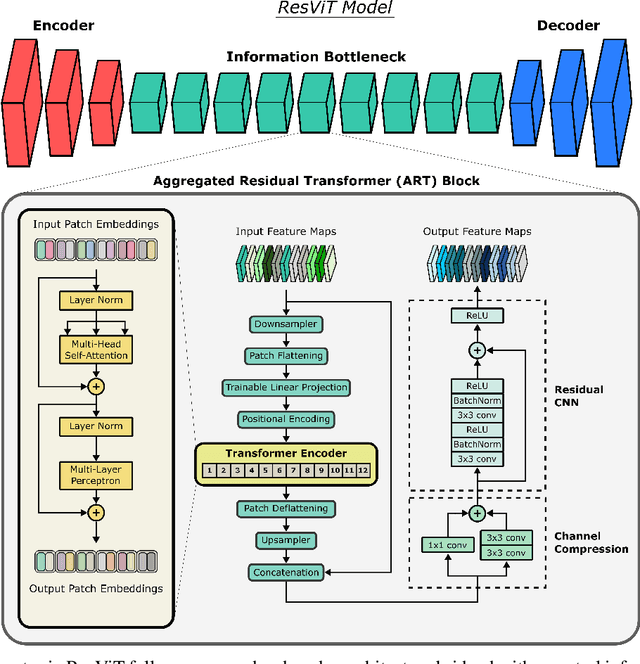
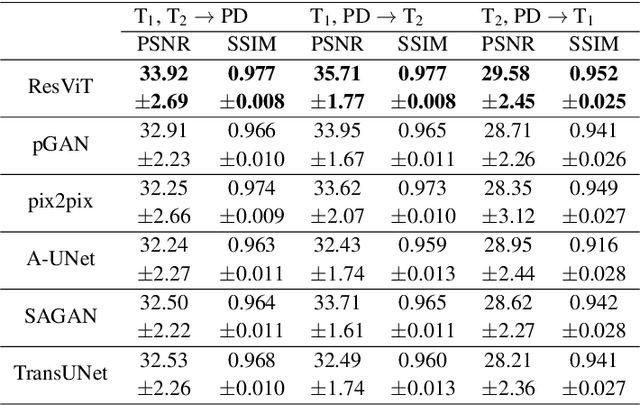
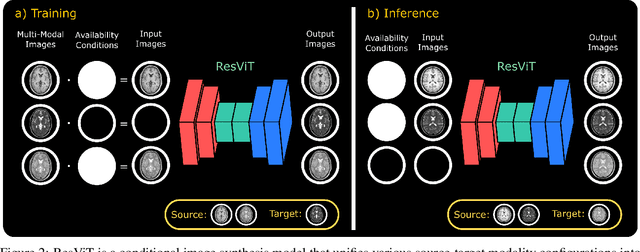
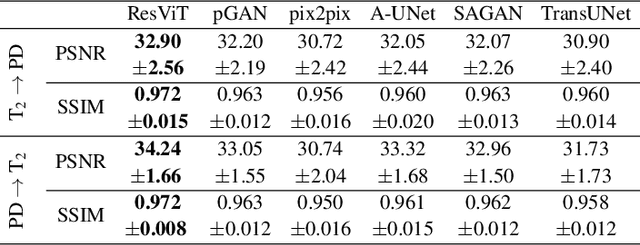
Multi-modal imaging is a key healthcare technology in the diagnosis and management of disease, but it is often underutilized due to costs associated with multiple separate scans. This limitation yields the need for synthesis of unacquired modalities from the subset of available modalities. In recent years, generative adversarial network (GAN) models with superior depiction of structural details have been established as state-of-the-art in numerous medical image synthesis tasks. However, GANs are characteristically based on convolutional neural network (CNN) backbones that perform local processing with compact filters. This inductive bias, in turn, compromises learning of long-range spatial dependencies. While attention maps incorporated in GANs can multiplicatively modulate CNN features to emphasize critical image regions, their capture of global context is mostly implicit. Here, we propose a novel generative adversarial approach for medical image synthesis, ResViT, to combine local precision of convolution operators with contextual sensitivity of vision transformers. Based on an encoder-decoder architecture, ResViT employs a central bottleneck comprising novel aggregated residual transformer (ART) blocks that synergistically combine convolutional and transformer modules. Comprehensive demonstrations are performed for synthesizing missing sequences in multi-contrast MRI and CT images from MRI. Our results indicate the superiority of ResViT against competing methods in terms of qualitative observations and quantitative metrics.