 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Simplification of Legal Texts
Paper and Code
Sep 01, 2022
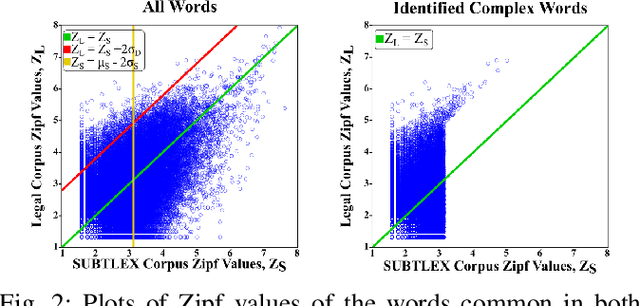
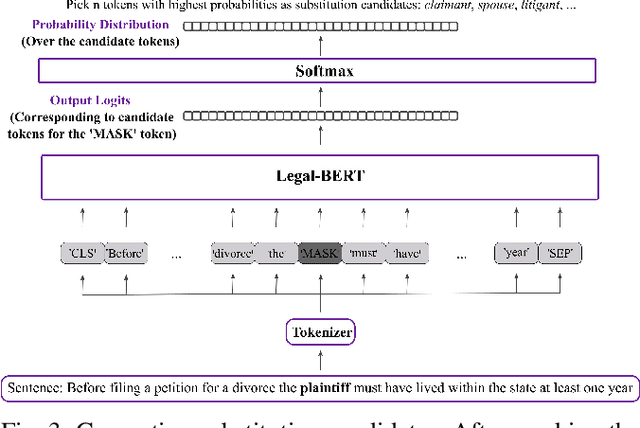

The processing of legal texts has been developing as an emerging field in natural language processing (NLP). Legal texts contain unique jargon and complex linguistic attributes in vocabulary, semantics, syntax, and morphology. Therefore, the development of text simplification (TS) methods specific to the legal domain is of paramount importance for facilitating comprehension of legal text by ordinary people and providing inputs to high-level models for mainstream legal NLP applications. While a recent study proposed a rule-based TS method for legal text, learning-based TS in the legal domain has not been considered previously. Here we introduce an unsupervised simplification method for legal texts (USLT). USLT performs domain-specific TS by replacing complex words and splitting long sentences. To this end, USLT detects complex words in a sentence, generates candidates via a masked-transformer model, and selects a candidate for substitution based on a rank score. Afterward, USLT recursively decomposes long sentences into a hierarchy of shorter core and context sentences while preserving semantic meaning. We demonstrate that USLT outperforms state-of-the-art domain-general TS methods in text simplicity while keeping the semantics intact.