 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models (LLMs) Assisted Wireless Network Deployment in Urban Settings
May 22, 2024



The advent of Large Language Models (LLMs) has revolutionized language understanding and human-like text generation, drawing interest from many other fields with this question in mind: What else are the LLMs capable of? Despite their widespread adoption, ongoing research continues to explore new ways to integrate LLMs into diverse systems. This paper explores new techniques to harness the power of LLMs for 6G (6th Generation) wireless communication technologies, a domain where automation and intelligent systems are pivotal. The inherent adaptability of LLMs to domain-specific tasks positions them as prime candidates for enhancing wireless systems in the 6G landscape. We introduce a novel Reinforcement Learning (RL) based framework that leverages LLMs for network deployment in wireless communications. Our approach involves training an RL agent, utilizing LLMs as its core, in an urban setting to maximize coverage. The agent's objective is to navigate the complexities of urban environments and identify the network parameters for optimal area coverage. Additionally, we integrate LLMs with Convolutional Neural Networks (CNNs) to capitalize on their strengths while mitigating their limitations. The Deep Deterministic Policy Gradient (DDPG) algorithm is employed for training purposes. The results suggest that LLM-assisted models can outperform CNN-based models in some cases while performing at least as well in others.
Fast-FNet: Accelerating Transformer Encoder Models via Efficient Fourier Layers
Sep 26, 2022
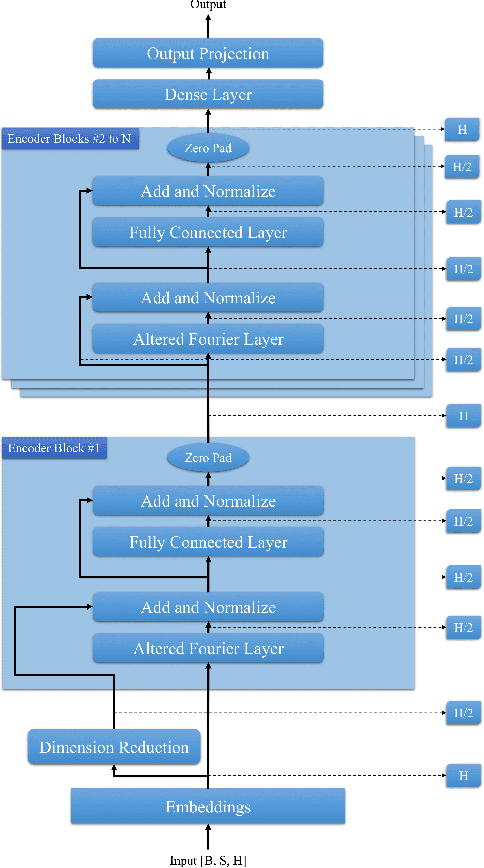
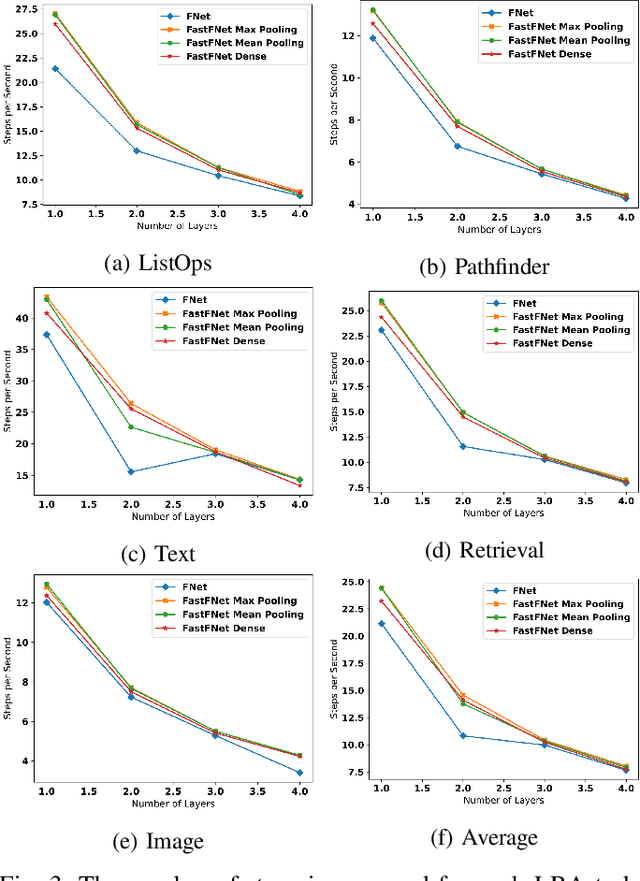
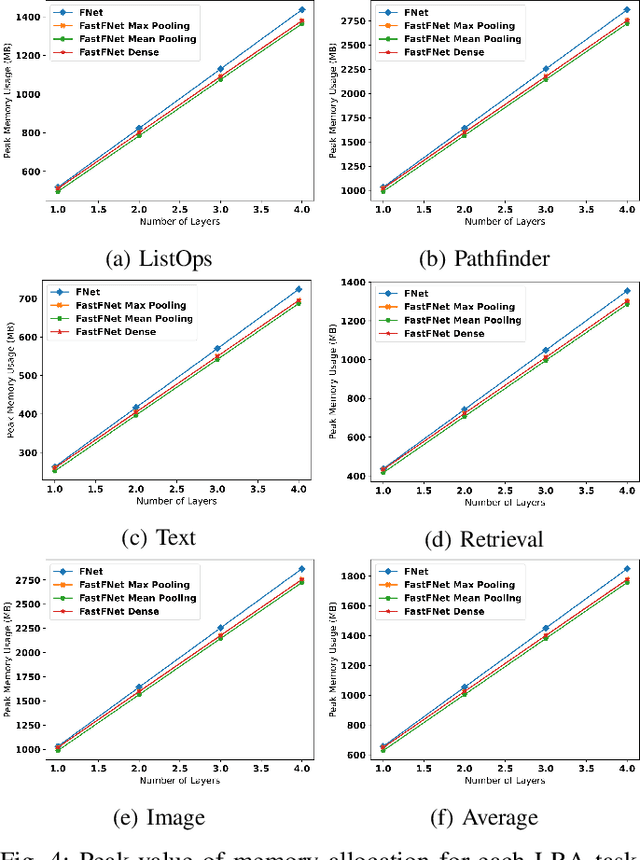
Transformer-based language models utilize the attention mechanism for substantial performance improvements in almost all natural language processing (NLP) tasks. Similar attention structures are also extensively studied in several other areas. Although the attention mechanism enhances the model performances significantly, its quadratic complexity prevents efficient processing of long sequences. Recent works focused on eliminating the disadvantages of computational inefficiency and showed that transformer-based models can still reach competitive results without the attention layer. A pioneering study proposed the FNet, which replaces the attention layer with the Fourier Transform (FT) in the transformer encoder architecture. FNet achieves competitive performances concerning the original transformer encoder model while accelerating training process by removing the computational burden of the attention mechanism. However, the FNet model ignores essential properties of the FT from the classical signal processing that can be leveraged to increase model efficiency further. We propose different methods to deploy FT efficiently in transformer encoder models. Our proposed architectures have smaller number of model parameters, shorter training times, less memory usage, and some additional performance improvements. We demonstrate these improvements through extensive experiments on common benchmarks.