 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification of power quality events in the transmission grid: comparative evaluation of different machine learning models
Mar 17, 2025Automatic classification of electric power quality events with respect to their root causes is critical for electrical grid management. In this paper, we present comparative evaluation results of an extensive set of machine learning models for the classification of power quality events, based on their root causes. After extensive experiments using different machine learning libraries, it is observed that the best performing learning models turn out to be Cubic SVM and XGBoost. During error analysis, it is observed that the main source of performance degradation for both models is the classification of ABC faults as ABCG faults, or vice versa. Ultimately, the models achieving the best results will be integrated into the event classification module of a large-scale power quality and grid monitoring system for the Turkish electricity transmission system.
Computational Law: Datasets, Benchmarks, and Ontologies
Mar 06, 2025
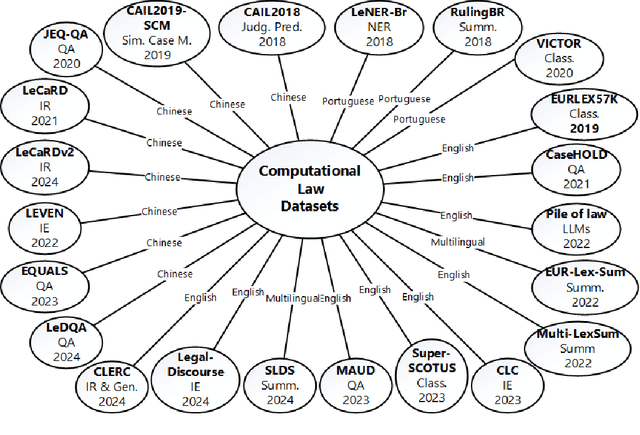
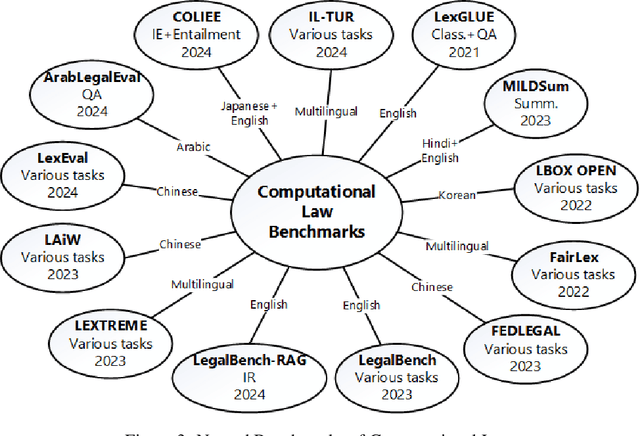
Recent developments in computer science and artificial intelligence have also contributed to the legal domain, as revealed by the number and range of related publications and applications. Machine and deep learning models require considerable amount of domain-specific data for training and comparison purposes, in order to attain high-performance in the legal domain. Additionally, semantic resources such as ontologies are valuable for building large-scale computational legal systems, in addition to ensuring interoperability of such systems. Considering these aspects, we present an up-to-date review of the literature on datasets, benchmarks, and ontologies proposed for computational law. We believe that this comprehensive and recent review will help researchers and practitioners when developing and testing approaches and systems for computational law.
Monitoring Energy Trends through Automatic Information Extraction
Jan 05, 2022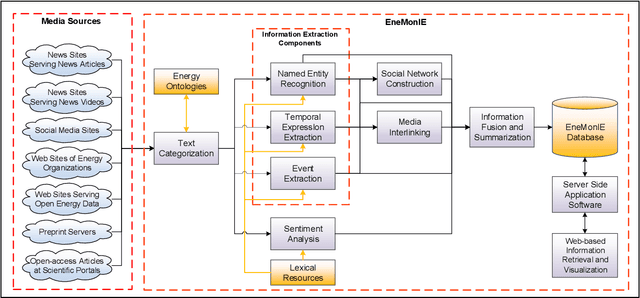
Energy research is of crucial public importance but the use of computer science technologies like automatic text processing and data management for the energy domain is still rare. Employing these technologies in the energy domain will be a significant contribution to the interdisciplinary topic of ``energy informatics", just like the related progress within the interdisciplinary area of ``bioinformatics". In this paper, we present the architecture of a Web-based semantic system called EneMonIE (Energy Monitoring through Information Extraction) for monitoring up-to-date energy trends through the use of automatic, continuous, and guided information extraction from diverse types of media available on the Web. The types of media handled by the system will include online news articles, social media texts, online news videos, and open-access scholarly papers and technical reports as well as various numeric energy data made publicly available by energy organizations. The system will utilize and contribute to the energy-related ontologies and its ultimate form will comprise components for (i) text categorization, (ii) named entity recognition, (iii) temporal expression extraction, (iv) event extraction, (v) social network construction, (vi) sentiment analysis, (vii) information fusion and summarization, (viii) media interlinking, and (ix) Web-based information retrieval and visualization. Wits its diverse data sources, automatic text processing capabilities, and presentation facilities open for public use; EneMonIE will be an important source of distilled and concise information for decision-makers including energy generation, transmission, and distribution system operators, energy research centres, related investors and entrepreneurs as well as for academicians, students, other individuals interested in the pace of energy events and technologies.
Stance Quantification: Definition of the Problem
Dec 25, 2021Stance detection is commonly defined as the automatic process of determining the positions of text producers, towards a target. In this paper, we define a research problem closely related to stance detection, namely, stance quantification, for the first time. We define stance quantification on a pair including (1) a set of natural language text items and (2) a target. At the end of the stance quantification process, a triple is obtained which consists of the percentages of the number of text items classified as Favor, Against, Neither, respectively, towards the target in the input pair. Also defined in the current paper is a significant subproblem of the stance quantification problem, namely, multi-target stance quantification. We believe that stance quantification at the aggregate level can lead to fruitful results in many application settings, and furthermore, stance quantification might be the sole stance related analysis alternative in settings where privacy concerns prevent researchers from applying generic stance detection.
To What Extent are Name Variants Used as Named Entities in Turkish Tweets?
Dec 17, 2019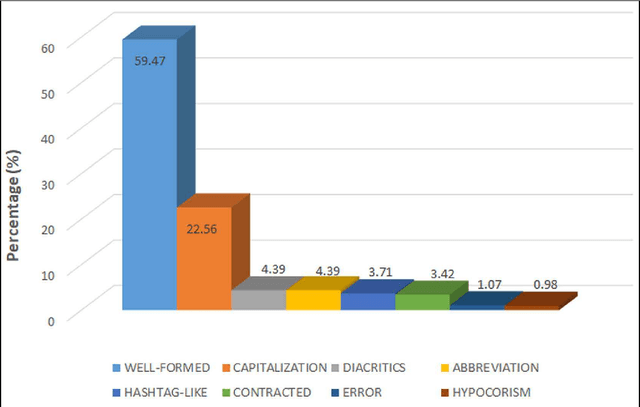
Social media texts differ from regular texts in various aspects. One of the main differences is the common use of informal name variants instead of well-formed named entities in social media compared to regular texts. These name variants may come in the form of abbreviations, nicknames, contractions, and hypocoristic uses, in addition to names distorted due to capitalization and writing errors. In this paper, we present an analysis of the named entities in a publicly-available tweet dataset in Turkish with respect to their being name variants belonging to different categories. We also provide finer-grained annotations of the named entities as well-formed names and different categories of name variants, where these annotations are made publicly-available. The analysis presented and the accompanying annotations will contribute to related research on the treatment of named entities in social media.
A Tweet Dataset Annotated for Named Entity Recognition and Stance Detection
Jan 16, 2019Annotated datasets in different domains are critical for many supervised learning-based solutions to related problems and for the evaluation of the proposed solutions. Topics in natural language processing (NLP) similarly require annotated datasets to be used for such purposes. In this paper, we target at two NLP problems, named entity recognition and stance detection, and present the details of a tweet dataset in Turkish annotated for named entity and stance information. Within the course of the current study, both the named entity and stance annotations of the included tweets are made publicly available, although previously the dataset has been publicly shared with stance annotations only. We believe that this dataset will be useful for uncovering the possible relationships between named entity recognition and stance detection in tweets.
Stance Detection on Tweets: An SVM-based Approach
Mar 23, 2018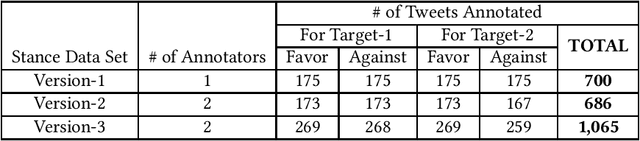
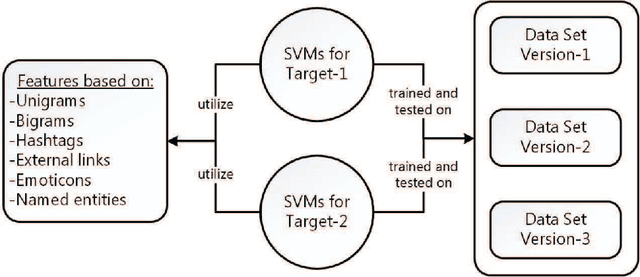

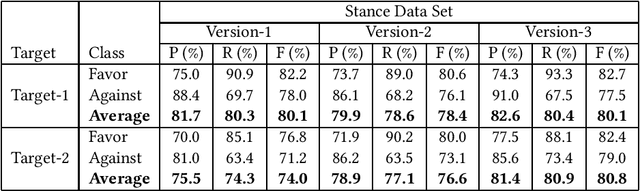
Stance detection is a subproblem of sentiment analysis where the stance of the author of a piece of natural language text for a particular target (either explicitly stated in the text or not) is explored. The stance output is usually given as Favor, Against, or Neither. In this paper, we target at stance detection on sports-related tweets and present the performance results of our SVM-based stance classifiers on such tweets. First, we describe three versions of our proprietary tweet data set annotated with stance information, all of which are made publicly available for research purposes. Next, we evaluate SVM classifiers using different feature sets for stance detection on this data set. The employed features are based on unigrams, bigrams, hashtags, external links, emoticons, and lastly, named entities. The results indicate that joint use of the features based on unigrams, hashtags, and named entities by SVM classifiers is a plausible approach for stance detection problem on sports-related tweets.
OntoWind: An Improved and Extended Wind Energy Ontology
Mar 07, 2018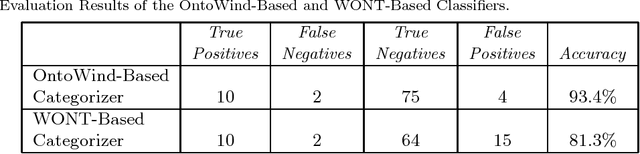
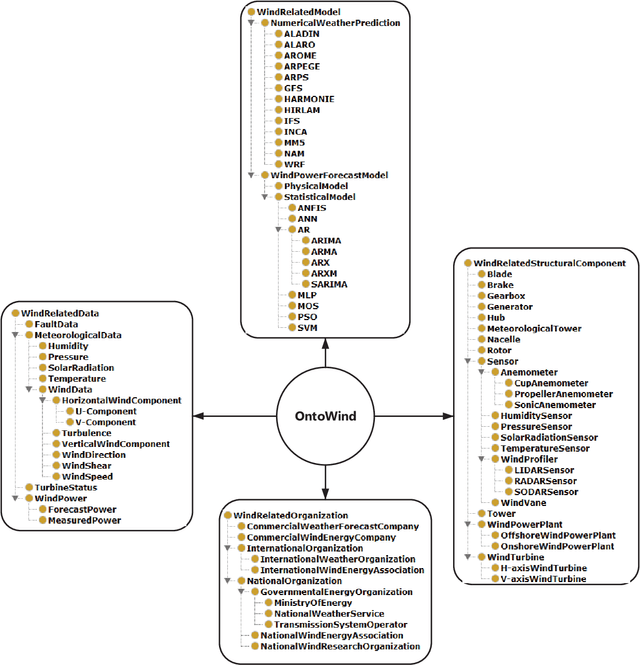
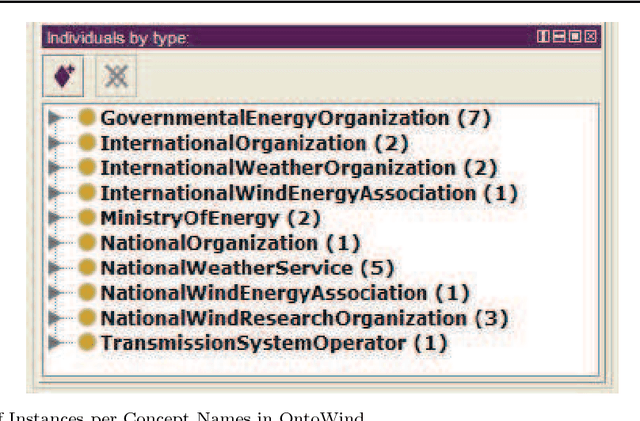
Ontologies are critical sources of semantic information for many application domains. Hence, there are ontologies proposed and utilized for domains such as medicine, chemical engineering, and electrical energy. In this paper, we present an improved and extended version of a wind energy ontology previously proposed. First, the ontology is restructured to increase its understandability and coverage. Secondly, it is enriched with new concepts, crisp/fuzzy attributes, and instances to increase its usability in semantic applications regarding wind energy. The ultimate ontology is utilized within a Web-based semantic portal application for wind energy, in order to showcase its contribution in a genuine application. Hence, the current study is a significant to wind and thereby renewable energy informatics, with the presented publicly-available wind energy ontology and the implemented proof-of-concept system.
Joint Named Entity Recognition and Stance Detection in Tweets
Jul 30, 2017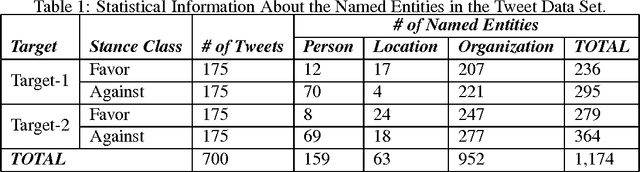
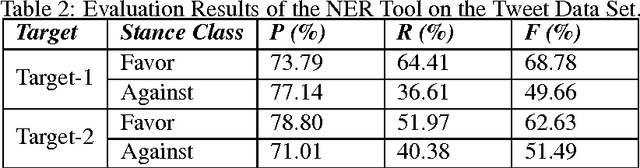
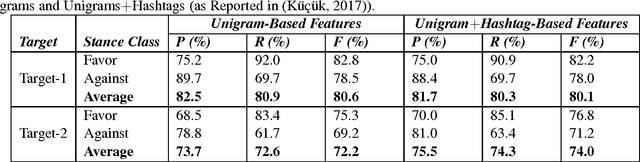
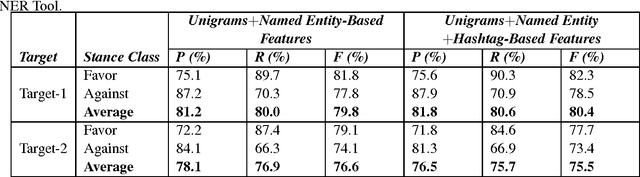
Named entity recognition (NER) is a well-established task of information extraction which has been studied for decades. More recently, studies reporting NER experiments on social media texts have emerged. On the other hand, stance detection is a considerably new research topic usually considered within the scope of sentiment analysis. Stance detection studies are mostly applied to texts of online debates where the stance of the text owner for a particular target, either explicitly or implicitly mentioned in text, is explored. In this study, we investigate the possible contribution of named entities to the stance detection task in tweets. We report the evaluation results of NER experiments as well as that of the subsequent stance detection experiments using named entities, on a publicly-available stance-annotated data set of tweets. Our results indicate that named entities obtained with a high-performance NER system can contribute to stance detection performance on tweets.
Stance Detection in Turkish Tweets
Jun 21, 2017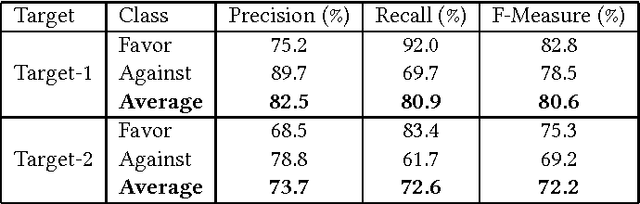
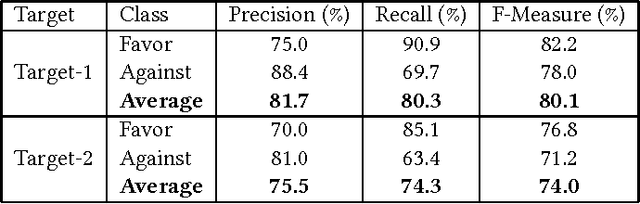
Stance detection is a classification problem in natural language processing where for a text and target pair, a class result from the set {Favor, Against, Neither} is expected. It is similar to the sentiment analysis problem but instead of the sentiment of the text author, the stance expressed for a particular target is investigated in stance detection. In this paper, we present a stance detection tweet data set for Turkish comprising stance annotations of these tweets for two popular sports clubs as targets. Additionally, we provide the evaluation results of SVM classifiers for each target on this data set, where the classifiers use unigram, bigram, and hashtag features. This study is significant as it presents one of the initial stance detection data sets proposed so far and the first one for Turkish language, to the best of our knowledge. The data set and the evaluation results of the corresponding SVM-based approaches will form plausible baselines for the comparison of future studies on stance detection.