 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Law: Datasets, Benchmarks, and Ontologies
Paper and Code
Mar 06, 2025
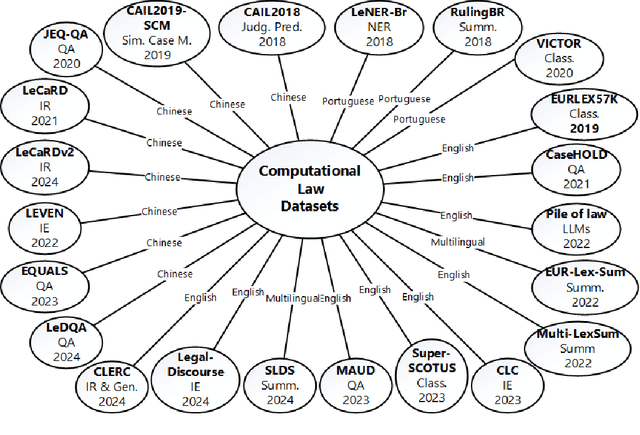
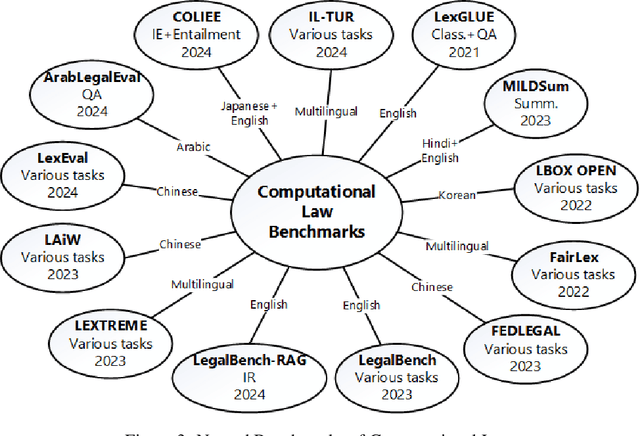
Recent developments in computer science and artificial intelligence have also contributed to the legal domain, as revealed by the number and range of related publications and applications. Machine and deep learning models require considerable amount of domain-specific data for training and comparison purposes, in order to attain high-performance in the legal domain. Additionally, semantic resources such as ontologies are valuable for building large-scale computational legal systems, in addition to ensuring interoperability of such systems. Considering these aspects, we present an up-to-date review of the literature on datasets, benchmarks, and ontologies proposed for computational law. We believe that this comprehensive and recent review will help researchers and practitioners when developing and testing approaches and systems for computational law.