 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStance Detection in Turkish Tweets
Paper and Code
Jun 21, 2017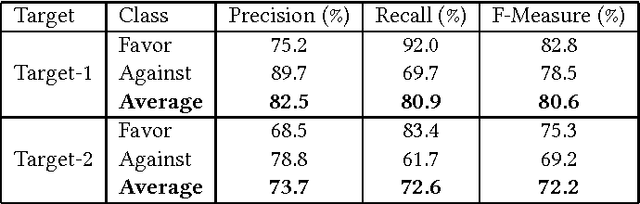
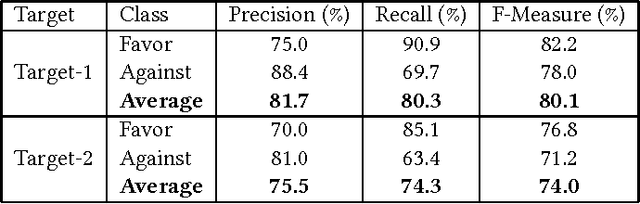
Stance detection is a classification problem in natural language processing where for a text and target pair, a class result from the set {Favor, Against, Neither} is expected. It is similar to the sentiment analysis problem but instead of the sentiment of the text author, the stance expressed for a particular target is investigated in stance detection. In this paper, we present a stance detection tweet data set for Turkish comprising stance annotations of these tweets for two popular sports clubs as targets. Additionally, we provide the evaluation results of SVM classifiers for each target on this data set, where the classifiers use unigram, bigram, and hashtag features. This study is significant as it presents one of the initial stance detection data sets proposed so far and the first one for Turkish language, to the best of our knowledge. The data set and the evaluation results of the corresponding SVM-based approaches will form plausible baselines for the comparison of future studies on stance detection.