 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Controlled Averaging for Federated Learning with Communication Compression
Aug 16, 2023



Communication compression, a technique aiming to reduce the information volume to be transmitted over the air, has gained great interests in Federated Learning (FL) for the potential of alleviating its communication overhead. However, communication compression brings forth new challenges in FL due to the interplay of compression-incurred information distortion and inherent characteristics of FL such as partial participation and data heterogeneity. Despite the recent development, the performance of compressed FL approaches has not been fully exploited. The existing approaches either cannot accommodate arbitrary data heterogeneity or partial participation, or require stringent conditions on compression. In this paper, we revisit the seminal stochastic controlled averaging method by proposing an equivalent but more efficient/simplified formulation with halved uplink communication costs. Building upon this implementation, we propose two compressed FL algorithms, SCALLION and SCAFCOM, to support unbiased and biased compression, respectively. Both the proposed methods outperform the existing compressed FL methods in terms of communication and computation complexities. Moreover, SCALLION and SCAFCOM accommodates arbitrary data heterogeneity and do not make any additional assumptions on compression errors. Experiments show that SCALLION and SCAFCOM can match the performance of corresponding full-precision FL approaches with substantially reduced uplink communication, and outperform recent compressed FL methods under the same communication budget.
CSPM: A Contrastive Spatiotemporal Preference Model for CTR Prediction in On-Demand Food Delivery Services
Aug 10, 2023



Click-through rate (CTR) prediction is a crucial task in the context of an online on-demand food delivery (OFD) platform for precisely estimating the probability of a user clicking on food items. Unlike universal e-commerce platforms such as Taobao and Amazon, user behaviors and interests on the OFD platform are more location and time-sensitive due to limited delivery ranges and regional commodity supplies. However, existing CTR prediction algorithms in OFD scenarios concentrate on capturing interest from historical behavior sequences, which fails to effectively model the complex spatiotemporal information within features, leading to poor performance. To address this challenge, this paper introduces the Contrastive Sres under different search states using three modules: contrastive spatiotemporal representation learning (CSRL), spatiotemporal preference extractor (StPE), and spatiotemporal information filter (StIF). CSRL utilizes a contrastive learning framework to generate a spatiotemporal activation representation (SAR) for the search action. StPE employs SAR to activate users' diverse preferences related to location and time from the historical behavior sequence field, using a multi-head attention mechanism. StIF incorporates SAR into a gating network to automatically capture important features with latent spatiotemporal effects. Extensive experiments conducted on two large-scale industrial datasets demonstrate the state-of-the-art performance of CSPM. Notably, CSPM has been successfully deployed in Alibaba's online OFD platform Ele.me, resulting in a significant 0.88% lift in CTR, which has substantial business implications.
Differentially Private One Permutation Hashing and Bin-wise Consistent Weighted Sampling
Jun 13, 2023



Minwise hashing (MinHash) is a standard algorithm widely used in the industry, for large-scale search and learning applications with the binary (0/1) Jaccard similarity. One common use of MinHash is for processing massive n-gram text representations so that practitioners do not have to materialize the original data (which would be prohibitive). Another popular use of MinHash is for building hash tables to enable sub-linear time approximate near neighbor (ANN) search. MinHash has also been used as a tool for building large-scale machine learning systems. The standard implementation of MinHash requires applying $K$ random permutations. In comparison, the method of one permutation hashing (OPH), is an efficient alternative of MinHash which splits the data vectors into $K$ bins and generates hash values within each bin. OPH is substantially more efficient and also more convenient to use. In this paper, we combine the differential privacy (DP) with OPH (as well as MinHash), to propose the DP-OPH framework with three variants: DP-OPH-fix, DP-OPH-re and DP-OPH-rand, depending on which densification strategy is adopted to deal with empty bins in OPH. A detailed roadmap to the algorithm design is presented along with the privacy analysis. An analytical comparison of our proposed DP-OPH methods with the DP minwise hashing (DP-MH) is provided to justify the advantage of DP-OPH. Experiments on similarity search confirm the merits of DP-OPH, and guide the choice of the proper variant in different practical scenarios. Our technique is also extended to bin-wise consistent weighted sampling (BCWS) to develop a new DP algorithm called DP-BCWS for non-binary data. Experiments on classification tasks demonstrate that DP-BCWS is able to achieve excellent utility at around $\epsilon = 5\sim 10$, where $\epsilon$ is the standard parameter in the language of $(\epsilon, \delta)$-DP.
Building K-Anonymous User Cohorts with\\ Consecutive Consistent Weighted Sampling (CCWS)
Apr 26, 2023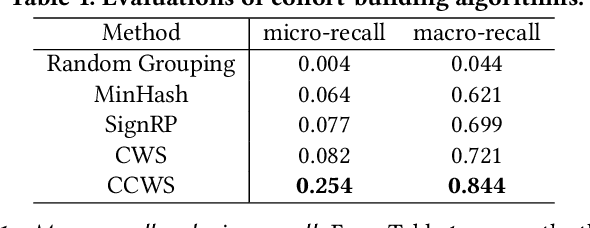
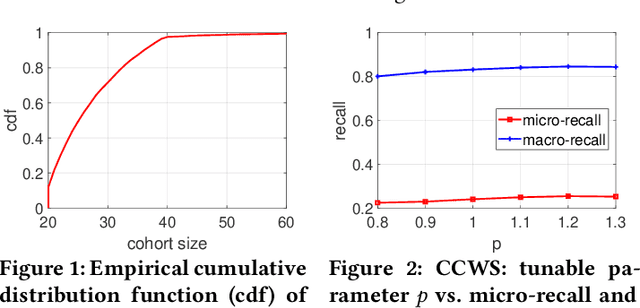
To retrieve personalized campaigns and creatives while protecting user privacy, digital advertising is shifting from member-based identity to cohort-based identity. Under such identity regime, an accurate and efficient cohort building algorithm is desired to group users with similar characteristics. In this paper, we propose a scalable $K$-anonymous cohort building algorithm called {\em consecutive consistent weighted sampling} (CCWS). The proposed method combines the spirit of the ($p$-powered) consistent weighted sampling and hierarchical clustering, so that the $K$-anonymity is ensured by enforcing a lower bound on the size of cohorts. Evaluations on a LinkedIn dataset consisting of $>70$M users and ads campaigns demonstrate that CCWS achieves substantial improvements over several hashing-based methods including sign random projections (SignRP), minwise hashing (MinHash), as well as the vanilla CWS.
OPORP: One Permutation + One Random Projection
Feb 07, 2023

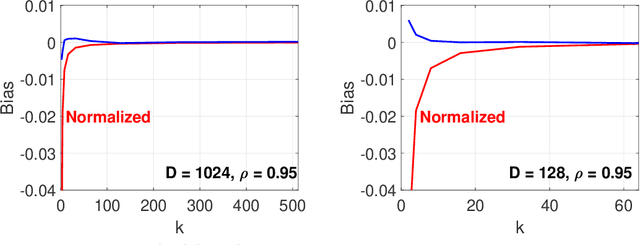

Consider two $D$-dimensional data vectors (e.g., embeddings): $u, v$. In many embedding-based retrieval (EBR) applications where the vectors are generated from trained models, $D=256\sim 1024$ are common. In this paper, OPORP (one permutation + one random projection) uses a variant of the ``count-sketch'' type of data structures for achieving data reduction/compression. With OPORP, we first apply a permutation on the data vectors. A random vector $r$ is generated i.i.d. with moments: $E(r_i) = 0, E(r_i^2)=1, E(r_i^3) =0, E(r_i^4)=s$. We multiply (as dot product) $r$ with all permuted data vectors. Then we break the $D$ columns into $k$ equal-length bins and aggregate (i.e., sum) the values in each bin to obtain $k$ samples from each data vector. One crucial step is to normalize the $k$ samples to the unit $l_2$ norm. We show that the estimation variance is essentially: $(s-1)A + \frac{D-k}{D-1}\frac{1}{k}\left[ (1-\rho^2)^2 -2A\right]$, where $A\geq 0$ is a function of the data ($u,v$). This formula reveals several key properties: (1) We need $s=1$. (2) The factor $\frac{D-k}{D-1}$ can be highly beneficial in reducing variances. (3) The term $\frac{1}{k}(1-\rho^2)^2$ is actually the asymptotic variance of the classical correlation estimator. We illustrate that by letting the $k$ in OPORP to be $k=1$ and repeat the procedure $m$ times, we exactly recover the work of ``very spars random projections'' (VSRP). This immediately leads to a normalized estimator for VSRP which substantially improves the original estimator of VSRP. In summary, with OPORP, the two key steps: (i) the normalization and (ii) the fixed-length binning scheme, have considerably improved the accuracy in estimating the cosine similarity, which is a routine (and crucial) task in modern embedding-based retrieval (EBR) applications.
Analysis of Error Feedback in Federated Non-Convex Optimization with Biased Compression
Nov 25, 2022



In federated learning (FL) systems, e.g., wireless networks, the communication cost between the clients and the central server can often be a bottleneck. To reduce the communication cost, the paradigm of communication compression has become a popular strategy in the literature. In this paper, we focus on biased gradient compression techniques in non-convex FL problems. In the classical setting of distributed learning, the method of error feedback (EF) is a common technique to remedy the downsides of biased gradient compression. In this work, we study a compressed FL scheme equipped with error feedback, named Fed-EF. We further propose two variants: Fed-EF-SGD and Fed-EF-AMS, depending on the choice of the global model optimizer. We provide a generic theoretical analysis, which shows that directly applying biased compression in FL leads to a non-vanishing bias in the convergence rate. The proposed Fed-EF is able to match the convergence rate of the full-precision FL counterparts under data heterogeneity with a linear speedup. Moreover, we develop a new analysis of the EF under partial client participation, which is an important scenario in FL. We prove that under partial participation, the convergence rate of Fed-EF exhibits an extra slow-down factor due to a so-called ``stale error compensation'' effect. A numerical study is conducted to justify the intuitive impact of stale error accumulation on the norm convergence of Fed-EF under partial participation. Finally, we also demonstrate that incorporating the two-way compression in Fed-EF does not change the convergence results. In summary, our work conducts a thorough analysis of the error feedback in federated non-convex optimization. Our analysis with partial client participation also provides insights on a theoretical limitation of the error feedback mechanism, and possible directions for improvements.
$k$-Median Clustering via Metric Embedding: Towards Better Initialization with Differential Privacy
Jun 26, 2022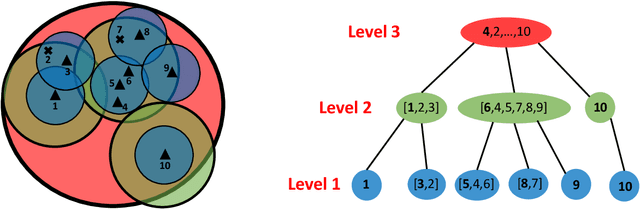
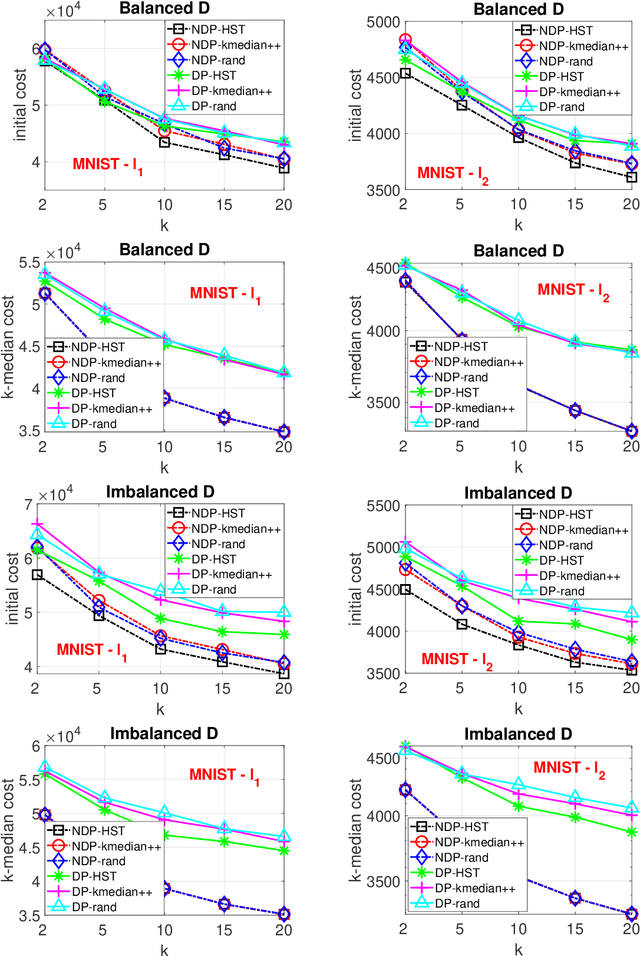
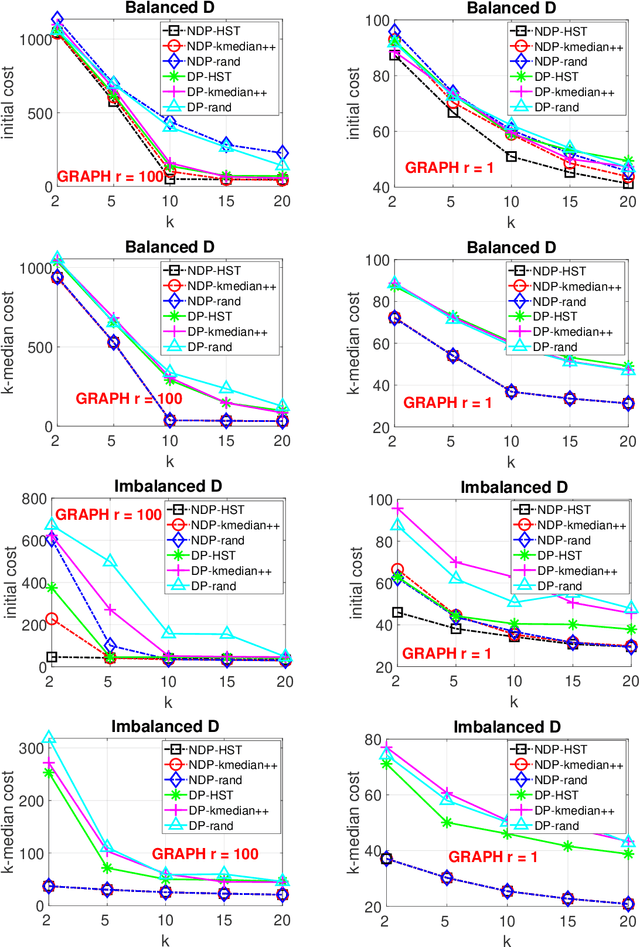
When designing clustering algorithms, the choice of initial centers is crucial for the quality of the learned clusters. In this paper, we develop a new initialization scheme, called HST initialization, for the $k$-median problem in the general metric space (e.g., discrete space induced by graphs), based on the construction of metric embedding tree structure of the data. From the tree, we propose a novel and efficient search algorithm, for good initial centers that can be used subsequently for the local search algorithm. Our proposed HST initialization can produce initial centers achieving lower errors than those from another popular initialization method, $k$-median++, with comparable efficiency. The HST initialization can also be extended to the setting of differential privacy (DP) to generate private initial centers. We show that the error from applying DP local search followed by our private HST initialization improves previous results on the approximation error, and approaches the lower bound within a small factor. Experiments justify the theory and demonstrate the effectiveness of our proposed method. Our approach can also be extended to the $k$-means problem.
On Distributed Adaptive Optimization with Gradient Compression
May 11, 2022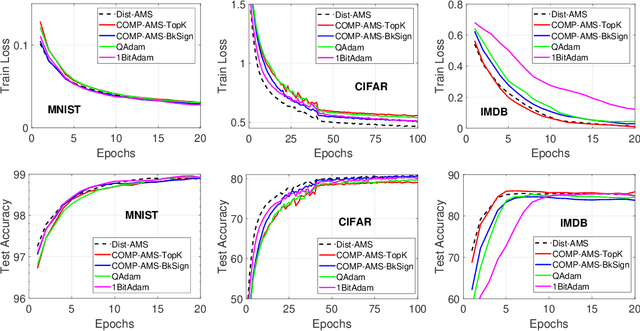

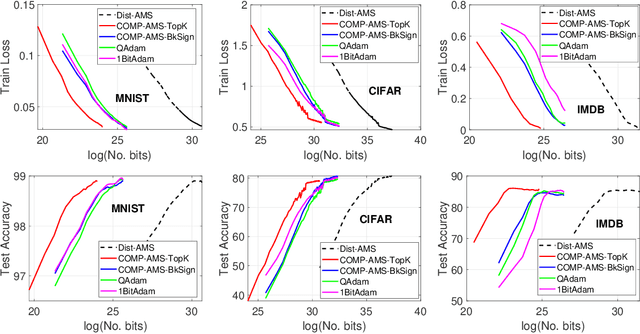
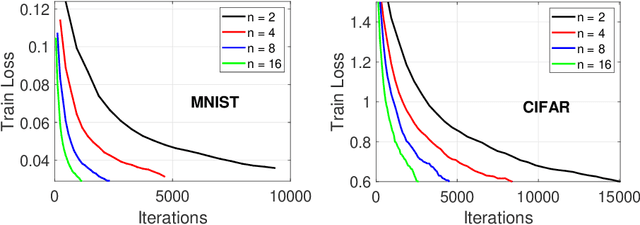
We study COMP-AMS, a distributed optimization framework based on gradient averaging and adaptive AMSGrad algorithm. Gradient compression with error feedback is applied to reduce the communication cost in the gradient transmission process. Our convergence analysis of COMP-AMS shows that such compressed gradient averaging strategy yields same convergence rate as standard AMSGrad, and also exhibits the linear speedup effect w.r.t. the number of local workers. Compared with recently proposed protocols on distributed adaptive methods, COMP-AMS is simple and convenient. Numerical experiments are conducted to justify the theoretical findings, and demonstrate that the proposed method can achieve same test accuracy as the full-gradient AMSGrad with substantial communication savings. With its simplicity and efficiency, COMP-AMS can serve as a useful distributed training framework for adaptive gradient methods.
Communication-Efficient TeraByte-Scale Model Training Framework for Online Advertising
Jan 05, 2022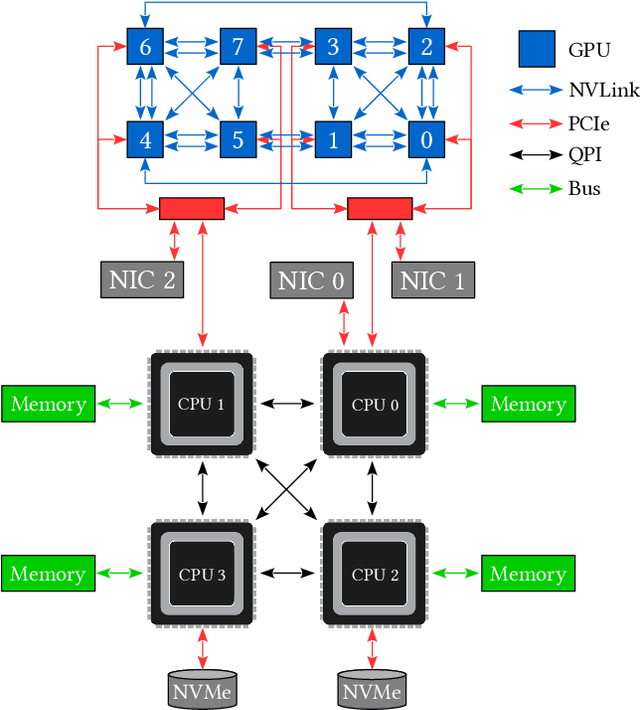
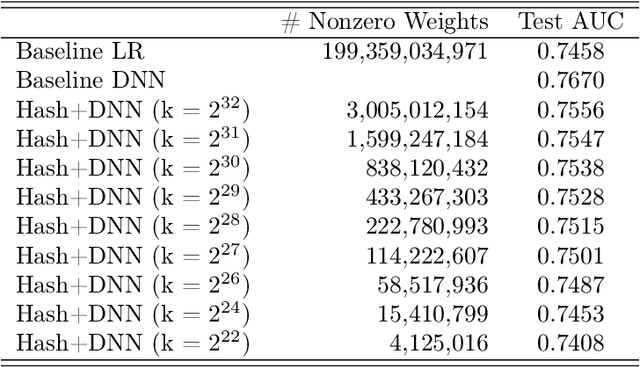
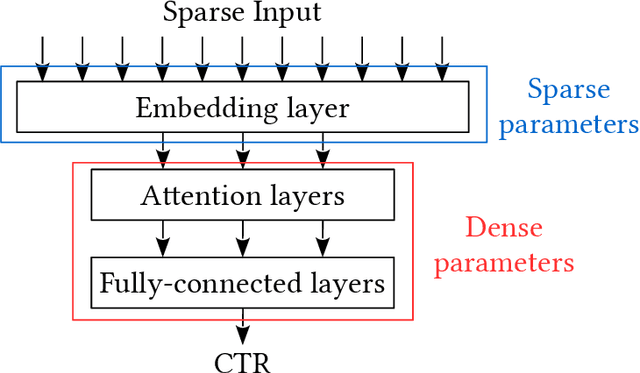
Click-Through Rate (CTR) prediction is a crucial component in the online advertising industry. In order to produce a personalized CTR prediction, an industry-level CTR prediction model commonly takes a high-dimensional (e.g., 100 or 1000 billions of features) sparse vector (that is encoded from query keywords, user portraits, etc.) as input. As a result, the model requires Terabyte scale parameters to embed the high-dimensional input. Hierarchical distributed GPU parameter server has been proposed to enable GPU with limited memory to train the massive network by leveraging CPU main memory and SSDs as secondary storage. We identify two major challenges in the existing GPU training framework for massive-scale ad models and propose a collection of optimizations to tackle these challenges: (a) the GPU, CPU, SSD rapidly communicate with each other during the training. The connections between GPUs and CPUs are non-uniform due to the hardware topology. The data communication route should be optimized according to the hardware topology; (b) GPUs in different computing nodes frequently communicates to synchronize parameters. We are required to optimize the communications so that the distributed system can become scalable. In this paper, we propose a hardware-aware training workflow that couples the hardware topology into the algorithm design. To reduce the extensive communication between computing nodes, we introduce a $k$-step model merging algorithm for the popular Adam optimizer and provide its convergence rate in non-convex optimization. To the best of our knowledge, this is the first application of $k$-step adaptive optimization method in industrial-level CTR model training. The numerical results on real-world data confirm that the optimized system design considerably reduces the training time of the massive model, with essentially no loss in accuracy.
C-OPH: Improving the Accuracy of One Permutation Hashing with Circulant Permutations
Nov 18, 2021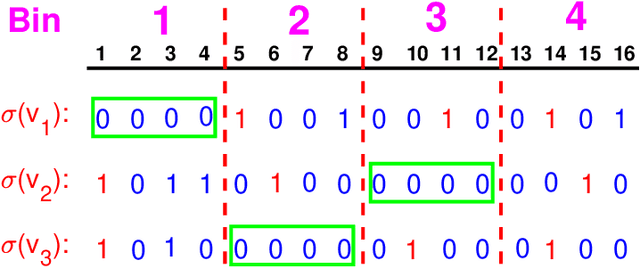
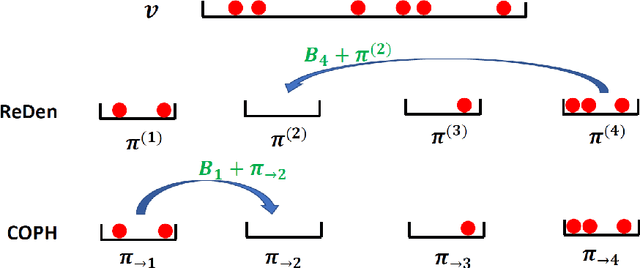
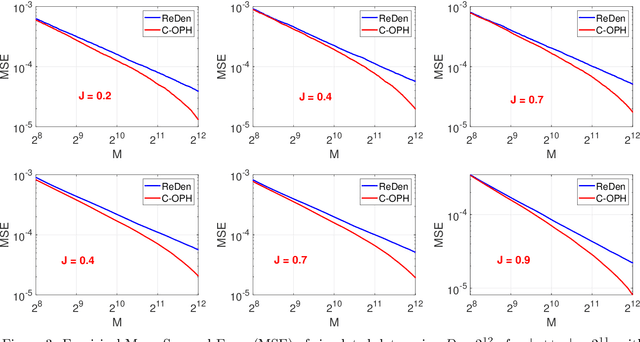
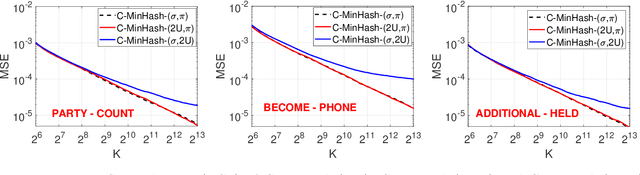
Minwise hashing (MinHash) is a classical method for efficiently estimating the Jaccrad similarity in massive binary (0/1) data. To generate $K$ hash values for each data vector, the standard theory of MinHash requires $K$ independent permutations. Interestingly, the recent work on "circulant MinHash" (C-MinHash) has shown that merely two permutations are needed. The first permutation breaks the structure of the data and the second permutation is re-used $K$ time in a circulant manner. Surprisingly, the estimation accuracy of C-MinHash is proved to be strictly smaller than that of the original MinHash. The more recent work further demonstrates that practically only one permutation is needed. Note that C-MinHash is different from the well-known work on "One Permutation Hashing (OPH)" published in NIPS'12. OPH and its variants using different "densification" schemes are popular alternatives to the standard MinHash. The densification step is necessary in order to deal with empty bins which exist in One Permutation Hashing. In this paper, we propose to incorporate the essential ideas of C-MinHash to improve the accuracy of One Permutation Hashing. Basically, we develop a new densification method for OPH, which achieves the smallest estimation variance compared to all existing densification schemes for OPH. Our proposed method is named C-OPH (Circulant OPH). After the initial permutation (which breaks the existing structure of the data), C-OPH only needs a "shorter" permutation of length $D/K$ (instead of $D$), where $D$ is the original data dimension and $K$ is the total number of bins in OPH. This short permutation is re-used in $K$ bins in a circulant shifting manner. It can be shown that the estimation variance of the Jaccard similarity is strictly smaller than that of the existing (densified) OPH methods.