 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPORP: One Permutation + One Random Projection
Paper and Code
Feb 07, 2023

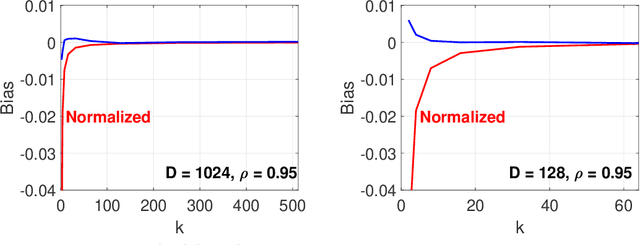

Consider two $D$-dimensional data vectors (e.g., embeddings): $u, v$. In many embedding-based retrieval (EBR) applications where the vectors are generated from trained models, $D=256\sim 1024$ are common. In this paper, OPORP (one permutation + one random projection) uses a variant of the ``count-sketch'' type of data structures for achieving data reduction/compression. With OPORP, we first apply a permutation on the data vectors. A random vector $r$ is generated i.i.d. with moments: $E(r_i) = 0, E(r_i^2)=1, E(r_i^3) =0, E(r_i^4)=s$. We multiply (as dot product) $r$ with all permuted data vectors. Then we break the $D$ columns into $k$ equal-length bins and aggregate (i.e., sum) the values in each bin to obtain $k$ samples from each data vector. One crucial step is to normalize the $k$ samples to the unit $l_2$ norm. We show that the estimation variance is essentially: $(s-1)A + \frac{D-k}{D-1}\frac{1}{k}\left[ (1-\rho^2)^2 -2A\right]$, where $A\geq 0$ is a function of the data ($u,v$). This formula reveals several key properties: (1) We need $s=1$. (2) The factor $\frac{D-k}{D-1}$ can be highly beneficial in reducing variances. (3) The term $\frac{1}{k}(1-\rho^2)^2$ is actually the asymptotic variance of the classical correlation estimator. We illustrate that by letting the $k$ in OPORP to be $k=1$ and repeat the procedure $m$ times, we exactly recover the work of ``very spars random projections'' (VSRP). This immediately leads to a normalized estimator for VSRP which substantially improves the original estimator of VSRP. In summary, with OPORP, the two key steps: (i) the normalization and (ii) the fixed-length binning scheme, have considerably improved the accuracy in estimating the cosine similarity, which is a routine (and crucial) task in modern embedding-based retrieval (EBR) applications.