 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAB: An LLM-Inspired Sequence-First Click-Through Rate Prediction Modeling Paradigm
Feb 03, 2026Traditional Deep Learning Recommendation Models (DLRMs) face increasing bottlenecks in performance and efficiency, often struggling with generalization and long-sequence modeling. Inspired by the scaling success of Large Language Models (LLMs), we propose Generative Ranking for Ads at Baidu (GRAB), an end-to-end generative framework for Click-Through Rate (CTR) prediction. GRAB integrates a novel Causal Action-aware Multi-channel Attention (CamA) mechanism to effectively capture temporal dynamics and specific action signals within user behavior sequences. Full-scale online deployment demonstrates that GRAB significantly outperforms established DLRMs, delivering a 3.05% increase in revenue and a 3.49% rise in CTR. Furthermore, the model demonstrates desirable scaling behavior: its expressive power shows a monotonic and approximately linear improvement as longer interaction sequences are utilized.
Communication-Efficient TeraByte-Scale Model Training Framework for Online Advertising
Jan 05, 2022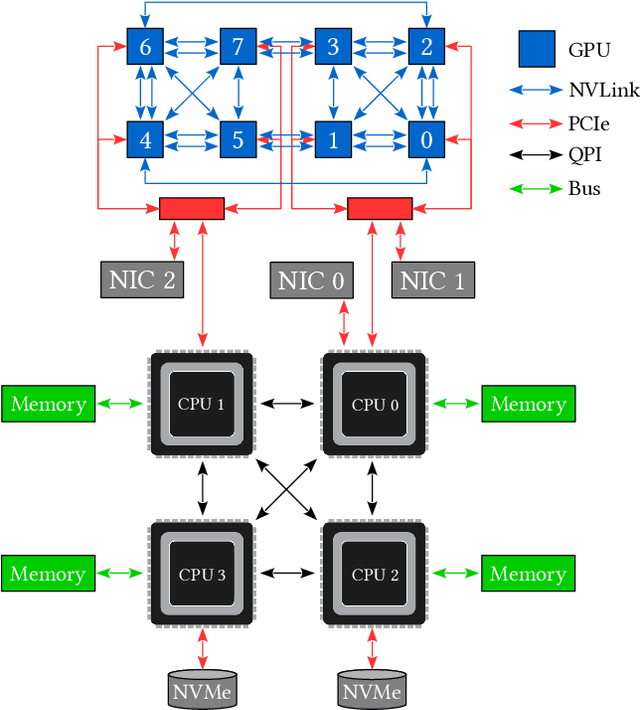
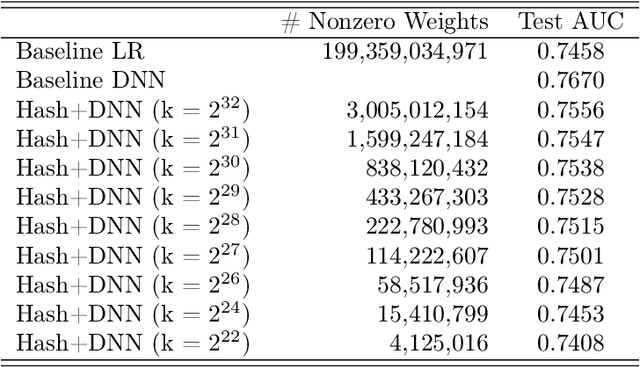
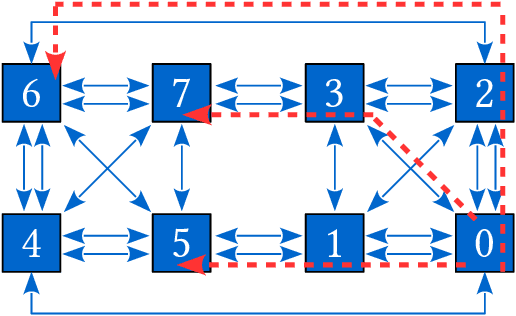
Click-Through Rate (CTR) prediction is a crucial component in the online advertising industry. In order to produce a personalized CTR prediction, an industry-level CTR prediction model commonly takes a high-dimensional (e.g., 100 or 1000 billions of features) sparse vector (that is encoded from query keywords, user portraits, etc.) as input. As a result, the model requires Terabyte scale parameters to embed the high-dimensional input. Hierarchical distributed GPU parameter server has been proposed to enable GPU with limited memory to train the massive network by leveraging CPU main memory and SSDs as secondary storage. We identify two major challenges in the existing GPU training framework for massive-scale ad models and propose a collection of optimizations to tackle these challenges: (a) the GPU, CPU, SSD rapidly communicate with each other during the training. The connections between GPUs and CPUs are non-uniform due to the hardware topology. The data communication route should be optimized according to the hardware topology; (b) GPUs in different computing nodes frequently communicates to synchronize parameters. We are required to optimize the communications so that the distributed system can become scalable. In this paper, we propose a hardware-aware training workflow that couples the hardware topology into the algorithm design. To reduce the extensive communication between computing nodes, we introduce a $k$-step model merging algorithm for the popular Adam optimizer and provide its convergence rate in non-convex optimization. To the best of our knowledge, this is the first application of $k$-step adaptive optimization method in industrial-level CTR model training. The numerical results on real-world data confirm that the optimized system design considerably reduces the training time of the massive model, with essentially no loss in accuracy.