 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialMem: Unified 3D Memory with Metric Anchoring and Fast Retrieval
Jan 21, 2026We present SpatialMem, a memory-centric system that unifies 3D geometry, semantics, and language into a single, queryable representation. Starting from casually captured egocentric RGB video, SpatialMem reconstructs metrically scaled indoor environments, detects structural 3D anchors (walls, doors, windows) as the first-layer scaffold, and populates a hierarchical memory with open-vocabulary object nodes -- linking evidence patches, visual embeddings, and two-layer textual descriptions to 3D coordinates -- for compact storage and fast retrieval. This design enables interpretable reasoning over spatial relations (e.g., distance, direction, visibility) and supports downstream tasks such as language-guided navigation and object retrieval without specialized sensors. Experiments across three real-life indoor scenes demonstrate that SpatialMem maintains strong anchor-description-level navigation completion and hierarchical retrieval accuracy under increasing clutter and occlusion, offering an efficient and extensible framework for embodied spatial intelligence.
CULTURE3D: Cultural Landmarks and Terrain Dataset for 3D Applications
Jan 12, 2025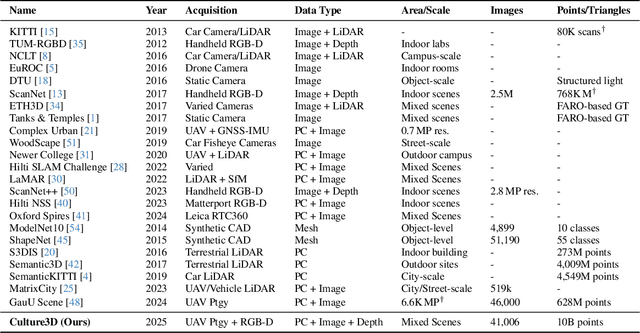
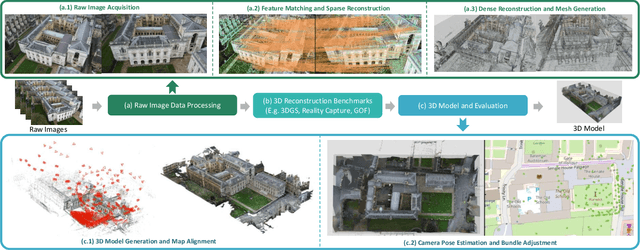
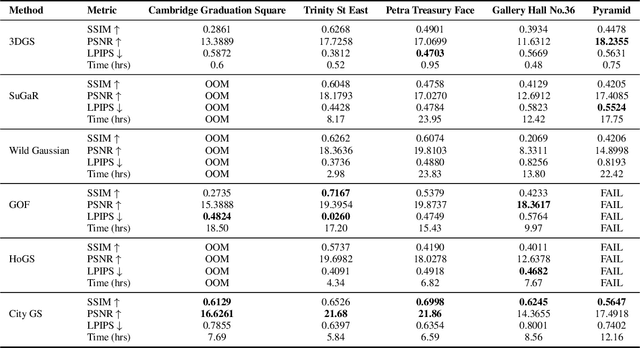

In this paper, we present a large-scale fine-grained dataset using high-resolution images captured from locations worldwide. Compared to existing datasets, our dataset offers a significantly larger size and includes a higher level of detail, making it uniquely suited for fine-grained 3D applications. Notably, our dataset is built using drone-captured aerial imagery, which provides a more accurate perspective for capturing real-world site layouts and architectural structures. By reconstructing environments with these detailed images, our dataset supports applications such as the COLMAP format for Gaussian Splatting and the Structure-from-Motion (SfM) method. It is compatible with widely-used techniques including SLAM, Multi-View Stereo, and Neural Radiance Fields (NeRF), enabling accurate 3D reconstructions and point clouds. This makes it a benchmark for reconstruction and segmentation tasks. The dataset enables seamless integration with multi-modal data, supporting a range of 3D applications, from architectural reconstruction to virtual tourism. Its flexibility promotes innovation, facilitating breakthroughs in 3D modeling and analysis.
Rebellion and Disobedience as Useful Tools in Human-Robot Interaction Research -- The Handheld Robotics Case
May 08, 2022

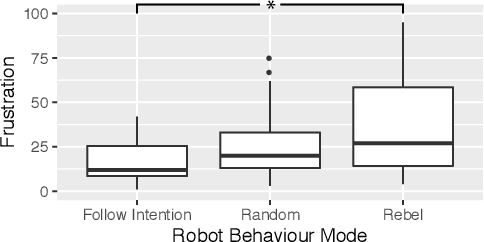
This position paper argues on the utility of rebellion and disobedience (RaD) in human-robot interaction (HRI). In general, we see two main opportunities in the use of controlled and well designed rebellion and disobedience: i) illuminate insight into the effectiveness of the collaboration (or lack of) and ii) prevent mistakes and correct user actions when in the user's own interest. Through the use of a close interaction modality, that of handheld robots, we discuss use cases for utility of rebellion and disobedience that can be applicable to other instances of HRI.
The Object at Hand: Automated Editing for Mixed Reality Video Guidance from Hand-Object Interactions
Sep 29, 2021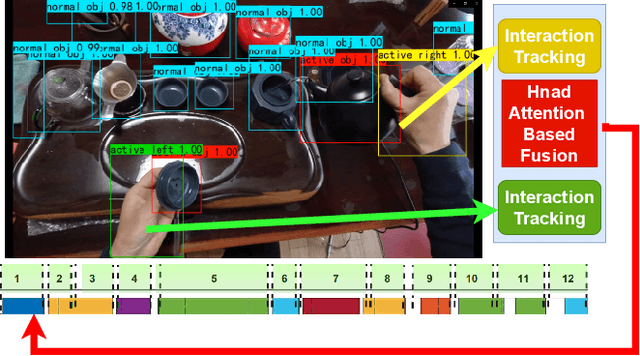

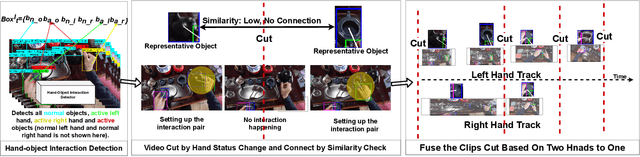
In this paper, we concern with the problem of how to automatically extract the steps that compose real-life hand activities. This is a key competence towards processing, monitoring and providing video guidance in Mixed Reality systems. We use egocentric vision to observe hand-object interactions in real-world tasks and automatically decompose a video into its constituent steps. Our approach combines hand-object interaction (HOI) detection, object similarity measurement and a finite state machine (FSM) representation to automatically edit videos into steps. We use a combination of Convolutional Neural Networks (CNNs) and the FSM to discover, edit cuts and merge segments while observing real hand activities. We evaluate quantitatively and qualitatively our algorithm on two datasets: the GTEA\cite{li2015delving}, and a new dataset we introduce for Chinese Tea making. Results show our method is able to segment hand-object interaction videos into key step segments with high levels of precision.
Egocentric Hand-object Interaction Detection and Application
Sep 29, 2021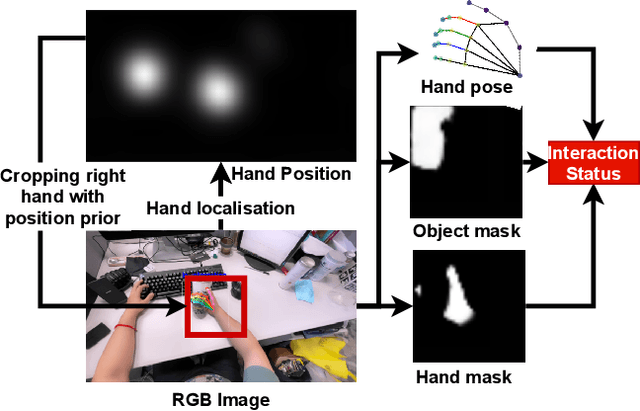
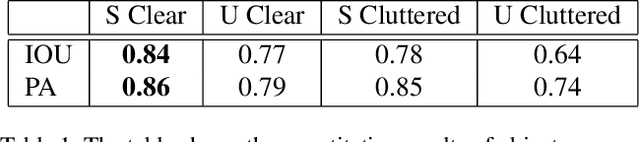

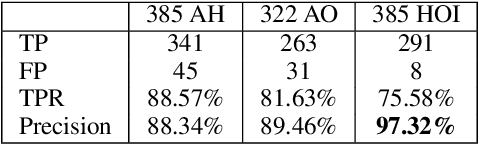
In this paper, we present a method to detect the hand-object interaction from an egocentric perspective. In contrast to massive data-driven discriminator based method like \cite{Shan20}, we propose a novel workflow that utilises the cues of hand and object. Specifically, we train networks predicting hand pose, hand mask and in-hand object mask to jointly predict the hand-object interaction status. We compare our method with the most recent work from Shan et al. \cite{Shan20} on selected images from EPIC-KITCHENS \cite{damen2018scaling} dataset and achieve $89\%$ accuracy on HOI (hand-object interaction) detection which is comparative to Shan's ($92\%$). However, for real-time performance, with the same machine, our method can run over $\textbf{30}$ FPS which is much efficient than Shan's ($\textbf{1}\sim\textbf{2}$ FPS). Furthermore, with our approach, we are able to segment script-less activities from where we extract the frames with the HOI status detection. We achieve $\textbf{68.2\%}$ and $\textbf{82.8\%}$ F1 score on GTEA \cite{fathi2011learning} and the UTGrasp \cite{cai2015scalable} dataset respectively which are all comparative to the SOTA methods.
Understanding Egocentric Hand-Object Interactions from Hand Pose Estimation
Sep 29, 2021
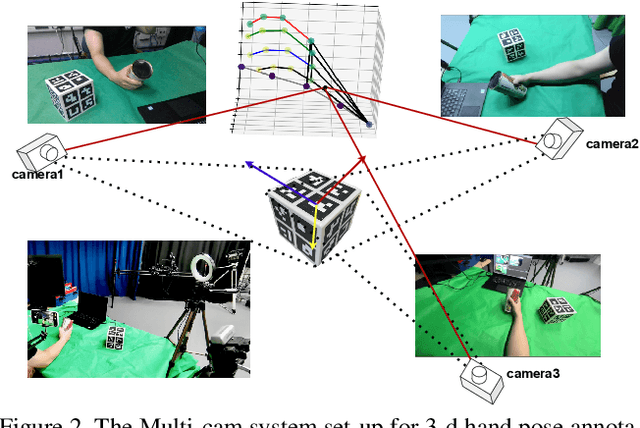
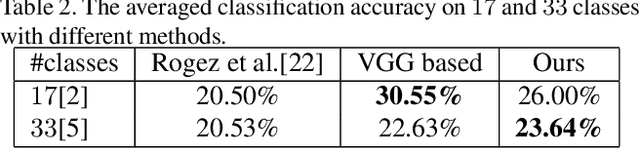
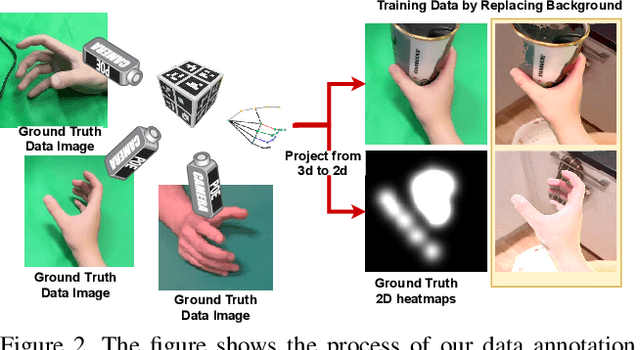
In this paper, we address the problem of estimating the hand pose from the egocentric view when the hand is interacting with objects. Specifically, we propose a method to label a dataset Ego-Siam which contains the egocentric images pair-wisely. We also use the collected pairwise data to train our encoder-decoder style network which has been proven efficient in. This could bring extra training efficiency and testing accuracy. Our network is lightweight and can be performed with over 30 FPS with an outdated GPU. We demonstrate that our method outperforms Mueller et al. which is the state of the art work dealing with egocentric hand-object interaction problems on the GANerated dataset. To show the ability to preserve the semantic information of our method, we also report the performance of grasp type classification on GUN-71 dataset and outperforms the benchmark by only using the predicted 3-d hand pose.
Reach Out and Help: Assisted Remote Collaboration through a Handheld Robot
Oct 04, 2019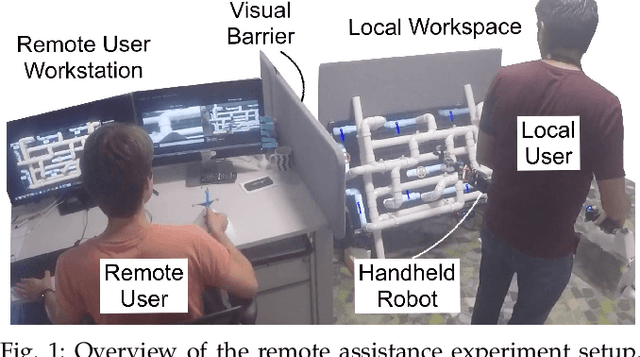

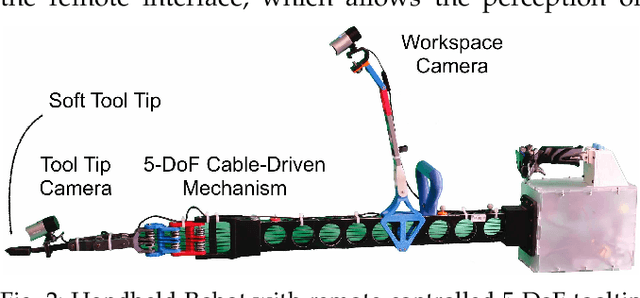

We explore a remote collaboration setup, which involves three parties: a local worker, a remote helper and a handheld robot carried by the local worker. We propose a system that allows a remote user to assist the local user through diagnosis, guidance and physical interaction as a novel aspect with the handheld robot providing task knowledge and enhanced motion and accuracy capabilities. Through experimental studies, we assess the proposed system in two different configurations: with and without the robot's assistance in terms of object interactions and task knowledge. We show that the handheld robot can mediate the helper's instructions and remote object interactions while the robot's semi-autonomous features improve task performance by 24%, reduce the workload for the remote user and decrease required communication bandwidth between both users. This study is a first attempt to evaluate how this new type of collaborative robot works in a remote assistance scenario, a setup that we believe is important to leverage current robot constraints and existing communication technologies.
Rebellion and Obedience: The Effects of Intention Prediction in Cooperative Handheld Robots
Mar 19, 2019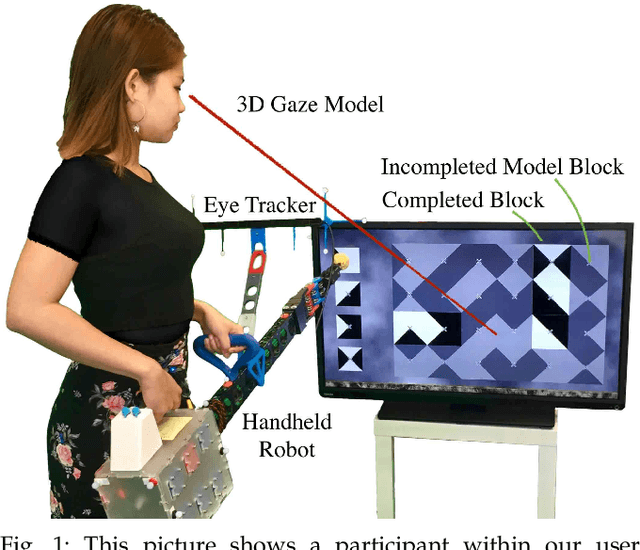
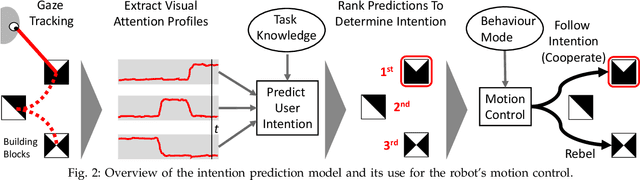
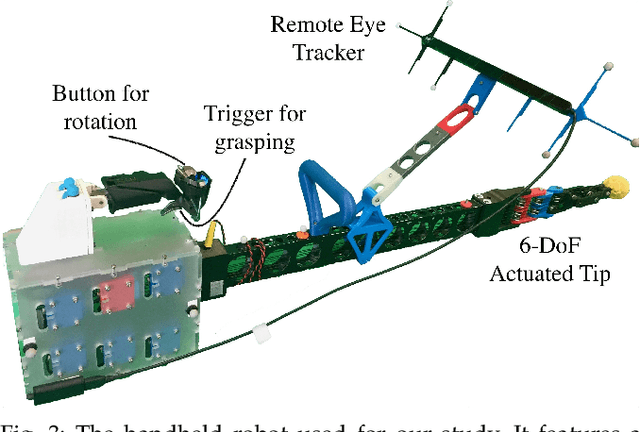

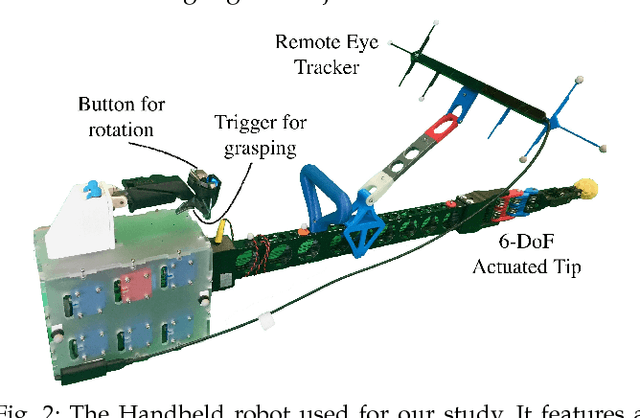
Within this work, we explore intention inference for user actions in the context of a handheld robot setup. Handheld robots share the shape and properties of handheld tools while being able to process task information and aid manipulation. Here, we propose an intention prediction model to enhance cooperative task solving. The model derives intention from the user's gaze pattern which is captured using a robot-mounted remote eye tracker. The proposed model yields real-time capabilities and reliable accuracy up to 1.5s prior to predicted actions being executed. We assess the model in an assisted pick and place task and show how the robot's intention obedience or rebellion affects the cooperation with the robot.
Towards Intention Prediction for Handheld Robots: a Case of Simulated Block Copying
Oct 15, 2018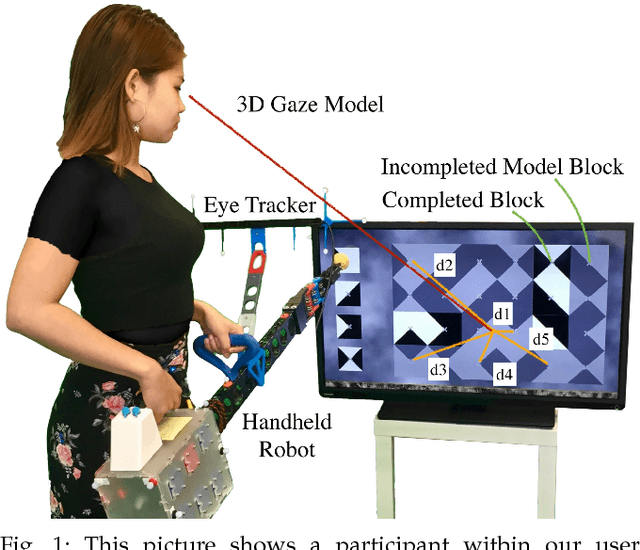
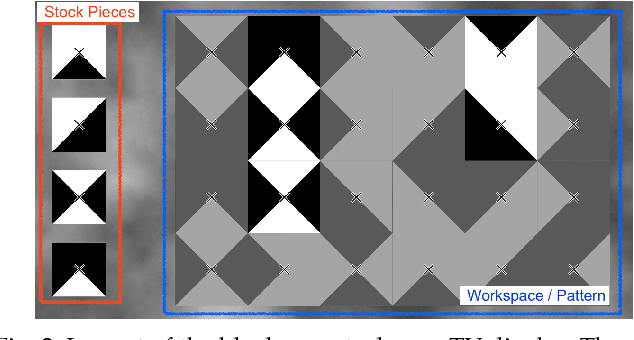
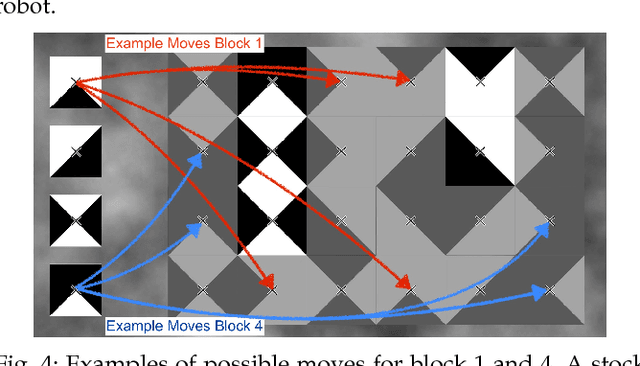
Within this work, we explore intention inference for user actions in the context of a handheld robot setup. Handheld robots share the shape and properties of handheld tools while being able to process task information and aid manipulation. Here, we propose an intention prediction model to enhance cooperative task solving. Within a block copy task, we collect eye gaze data using a robot-mounted remote eye tracker which is used to create a profile of visual attention for task-relevant objects in the workspace scene. These profiles are used to make predictions about user actions i.e. which block will be picked up next and where it will be placed. Our results show that our proposed model can predict user actions well in advance with an accuracy of 87.94% (500ms prior) for picking and 93.25% (1500 ms prior) for placing actions.
I Can See Your Aim: Estimating User Attention From Gaze For Handheld Robot Collaboration
Oct 15, 2018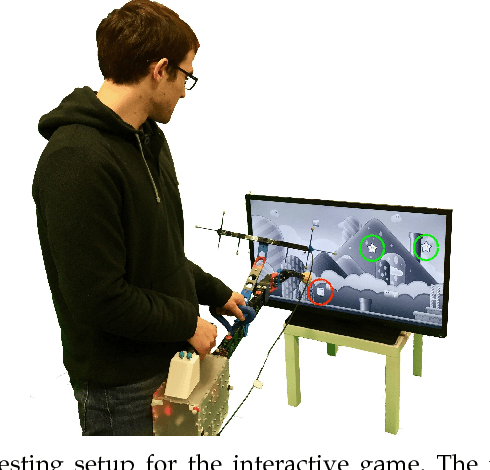
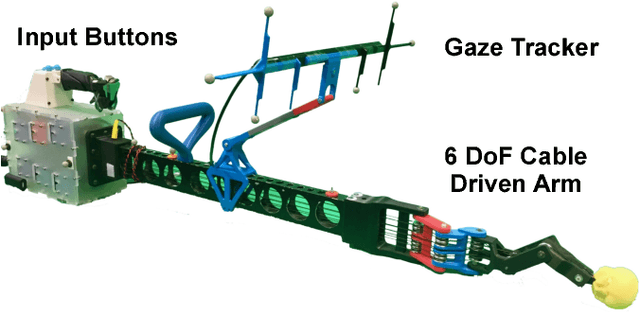
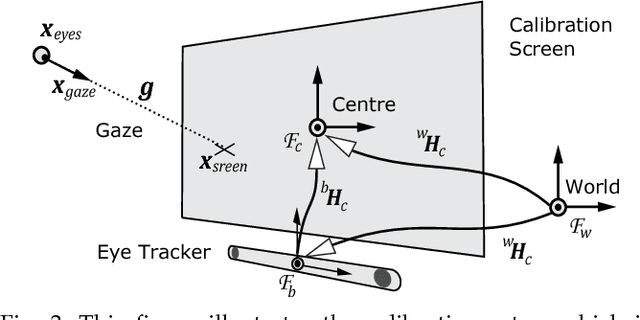
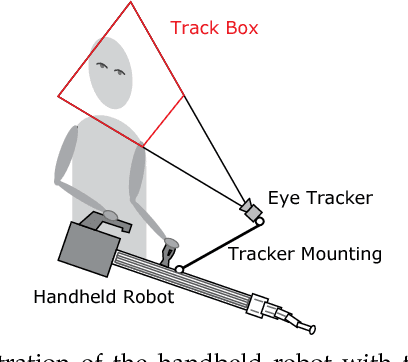
This paper explores the estimation of user attention in the setting of a cooperative handheld robot: a robot designed to behave as a handheld tool but that has levels of task knowledge. We use a tool-mounted gaze tracking system, which, after modelling via a pilot study, we use as a proxy for estimating the attention of the user. This information is then used for cooperation with users in a task of selecting and engaging with objects on a dynamic screen. Via a video game setup, we test various degrees of robot autonomy from fully autonomous, where the robot knows what it has to do and acts, to no autonomy where the user is in full control of the task. Our results measure performance and subjective metrics and show how the attention model benefits the interaction and preference of users.