 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Lists of Names for Named Entity Identification of Financial Institutions from Unstructured Documents
Paper and Code
Jun 07, 2016
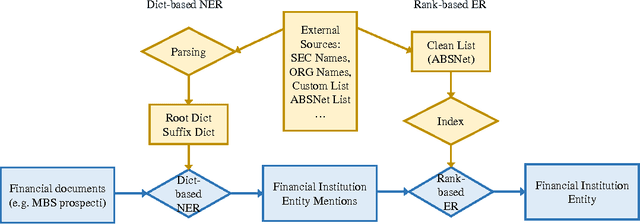
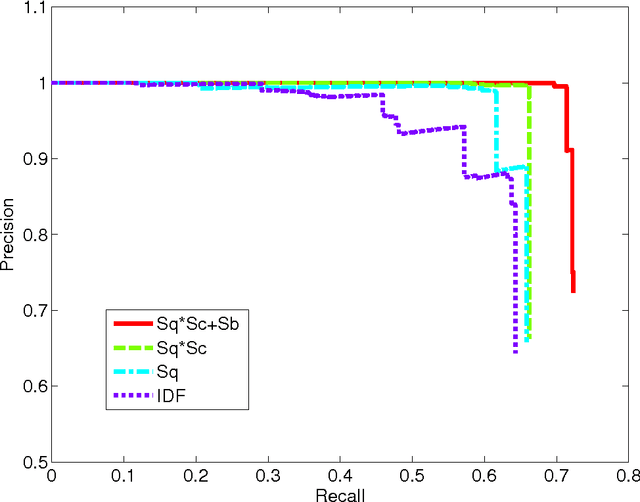
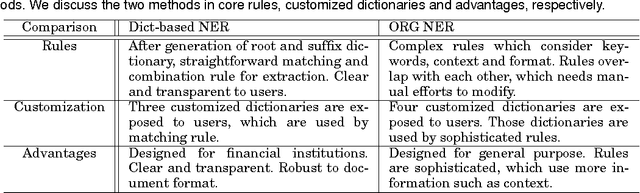
There is a wealth of information about financial systems that is embedded in document collections. In this paper, we focus on a specialized text extraction task for this domain. The objective is to extract mentions of names of financial institutions, or FI names, from financial prospectus documents, and to identify the corresponding real world entities, e.g., by matching against a corpus of such entities. The tasks are Named Entity Recognition (NER) and Entity Resolution (ER); both are well studied in the literature. Our contribution is to develop a rule-based approach that will exploit lists of FI names for both tasks; our solution is labeled Dict-based NER and Rank-based ER. Since the FI names are typically represented by a root, and a suffix that modifies the root, we use these lists of FI names to create specialized root and suffix dictionaries. To evaluate the effectiveness of our specialized solution for extracting FI names, we compare Dict-based NER with a general purpose rule-based NER solution, ORG NER. Our evaluation highlights the benefits and limitations of specialized versus general purpose approaches, and presents additional suggestions for tuning and customization for FI name extraction. To our knowledge, our proposed solutions, Dict-based NER and Rank-based ER, and the root and suffix dictionaries, are the first attempt to exploit specialized knowledge, i.e., lists of FI names, for rule-based NER and ER.