 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatentNet: A Large-Scale Incomplete Multiview, Multimodal, Multilabel Industrial Goods Image Database
Jun 23, 2021
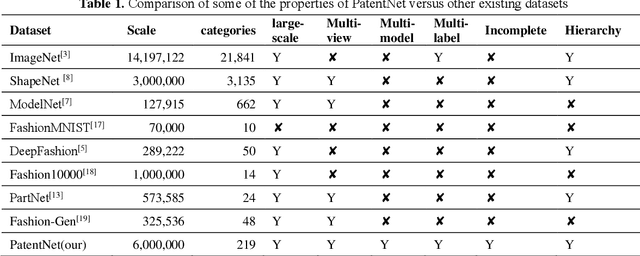
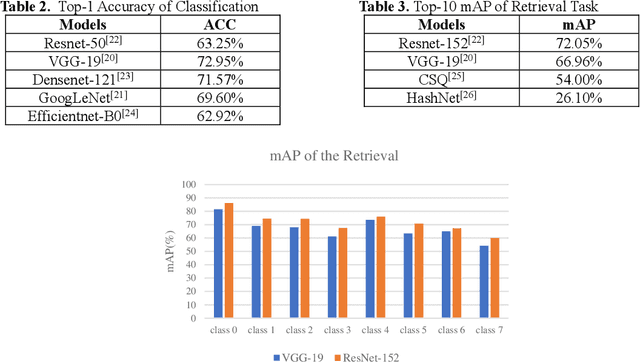

In deep learning area, large-scale image datasets bring a breakthrough in the success of object recognition and retrieval. Nowadays, as the embodiment of innovation, the diversity of the industrial goods is significantly larger, in which the incomplete multiview, multimodal and multilabel are different from the traditional dataset. In this paper, we introduce an industrial goods dataset, namely PatentNet, with numerous highly diverse, accurate and detailed annotations of industrial goods images, and corresponding texts. In PatentNet, the images and texts are sourced from design patent. Within over 6M images and corresponding texts of industrial goods labeled manually checked by professionals, PatentNet is the first ongoing industrial goods image database whose varieties are wider than industrial goods datasets used previously for benchmarking. PatentNet organizes millions of images into 32 classes and 219 subclasses based on the Locarno Classification Agreement. Through extensive experiments on image classification, image retrieval and incomplete multiview clustering, we demonstrate that our PatentNet is much more diverse, complex, and challenging, enjoying higher potentials than existing industrial image datasets. Furthermore, the characteristics of incomplete multiview, multimodal and multilabel in PatentNet are able to offer unparalleled opportunities in the artificial intelligence community and beyond.
A Review on Semi-Supervised Relation Extraction
Mar 12, 2021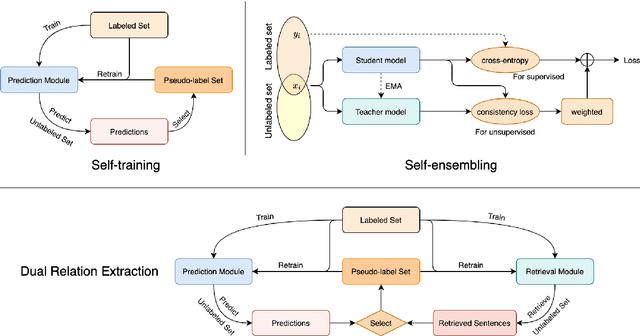

Relation extraction (RE) plays an important role in extracting knowledge from unstructured text but requires a large amount of labeled corpus. To reduce the expensive annotation efforts, semisupervised learning aims to leverage both labeled and unlabeled data. In this paper, we review and compare three typical methods in semi-supervised RE with deep learning or meta-learning: self-ensembling, which forces consistent under perturbations but may confront insufficient supervision; self-training, which iteratively generates pseudo labels and retrain itself with the enlarged labeled set; dual learning, which leverages a primal task and a dual task to give mutual feedback. Mean-teacher (Tarvainen and Valpola, 2017), LST (Li et al., 2019), and DualRE (Lin et al., 2019) are elaborated as the representatives to alleviate the weakness of these three methods, respectively.
Predicting the Behavior of Dealers in Over-The-Counter Corporate Bond Markets
Mar 12, 2021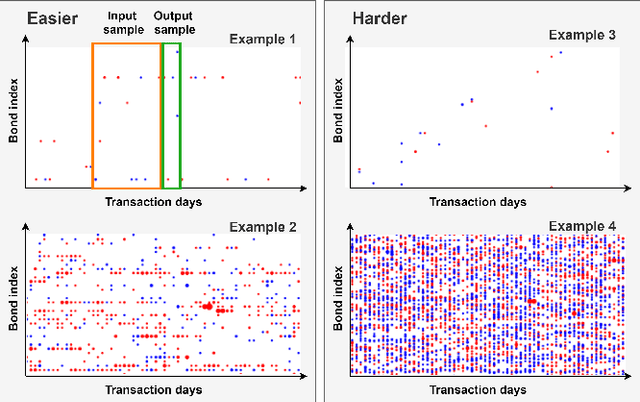
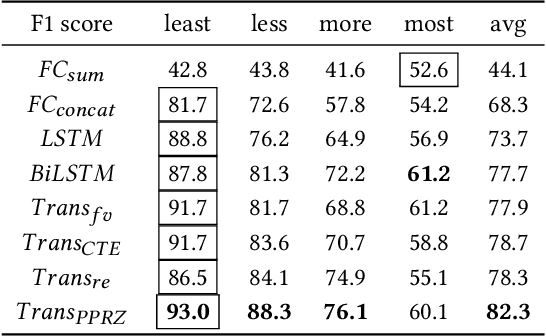

Trading in Over-The-Counter (OTC) markets is facilitated by broker-dealers, in comparison to public exchanges, e.g., the New York Stock Exchange (NYSE). Dealers play an important role in stabilizing prices and providing liquidity in OTC markets. We apply machine learning methods to model and predict the trading behavior of OTC dealers for US corporate bonds. We create sequences of daily historical transaction reports for each dealer over a vocabulary of US corporate bonds. Using this history of dealer activity, we predict the future trading decisions of the dealer. We consider a range of neural network-based prediction models. We propose an extension, the Pointwise-Product ReZero (PPRZ) Transformer model, and demonstrate the improved performance of our model. We show that individual history provides the best predictive model for the most active dealers. For less active dealers, a collective model provides improved performance. Further, clustering dealers based on their similarity can improve performance. Finally, prediction accuracy varies based on the activity level of both the bond and the dealer.
Bilingual Dictionary-based Language Model Pretraining for Neural Machine Translation
Mar 12, 2021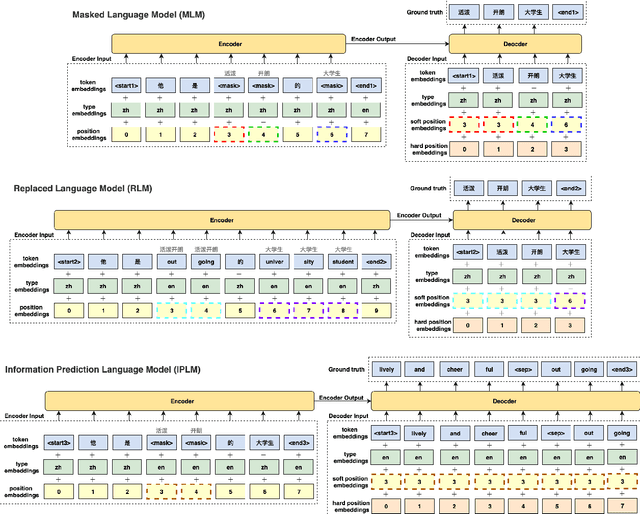
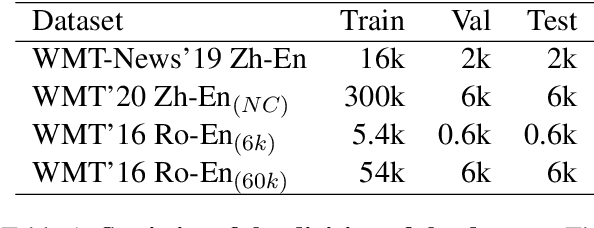

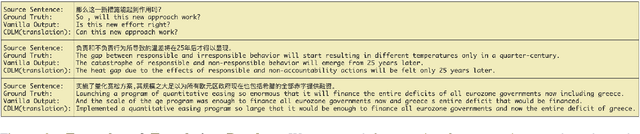
Recent studies have demonstrated a perceivable improvement on the performance of neural machine translation by applying cross-lingual language model pretraining (Lample and Conneau, 2019), especially the Translation Language Modeling (TLM). To alleviate the need for expensive parallel corpora by TLM, in this work, we incorporate the translation information from dictionaries into the pretraining process and propose a novel Bilingual Dictionary-based Language Model (BDLM). We evaluate our BDLM in Chinese, English, and Romanian. For Chinese-English, we obtained a 55.0 BLEU on WMT-News19 (Tiedemann, 2012) and a 24.3 BLEU on WMT20 news-commentary, outperforming the Vanilla Transformer (Vaswani et al., 2017) by more than 8.4 BLEU and 2.3 BLEU, respectively. According to our results, the BDLM also has advantages on convergence speed and predicting rare words. The increase in BLEU for WMT16 Romanian-English also shows its effectiveness in low-resources language translation.