 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Heterogeneous Effects of Software Patches in a Multiplayer Online Battle Arena Game
Oct 27, 2021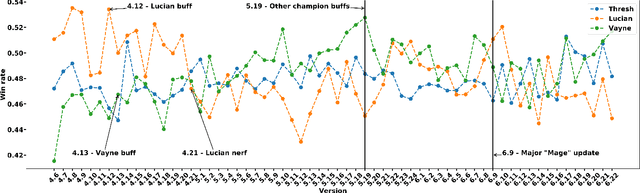
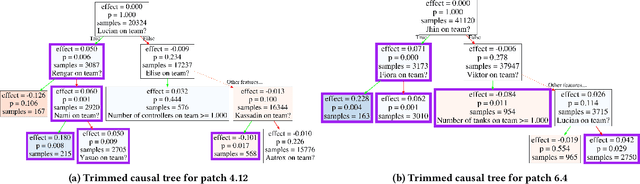

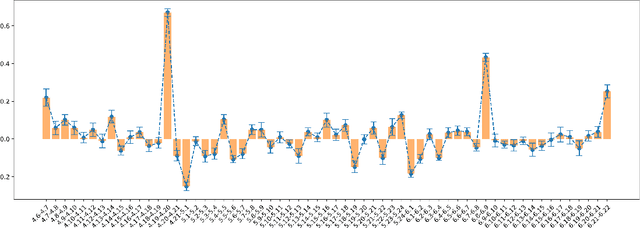
The popularity of online gaming has grown dramatically, driven in part by streaming and the billion-dollar e-sports industry. Online games regularly update their software to fix bugs, add functionality that improve the game's look and feel, and change the game mechanics to keep the games fun and challenging. An open question, however, is the impact of these changes on player performance and game balance, as well as how players adapt to these sudden changes. To address these questions, we use causal inference to measure the impact of software patches to League of Legends, a popular team-based multiplayer online game. We show that game patches have substantially different impacts on players depending on their skill level and whether they take breaks between games. We find that the gap between good and bad players increases after a patch, despite efforts to make gameplay more equal. Moreover, longer between-game breaks tend to improve player performance after patches. Overall, our results highlight the utility of causal inference, and specifically heterogeneous treatment effect estimation, as a tool to quantify the complex mechanisms of game balance and its interplay with players' performance.
* 9 pages, 11 figures
Inherent Trade-offs in the Fair Allocation of Treatments
Oct 30, 2020
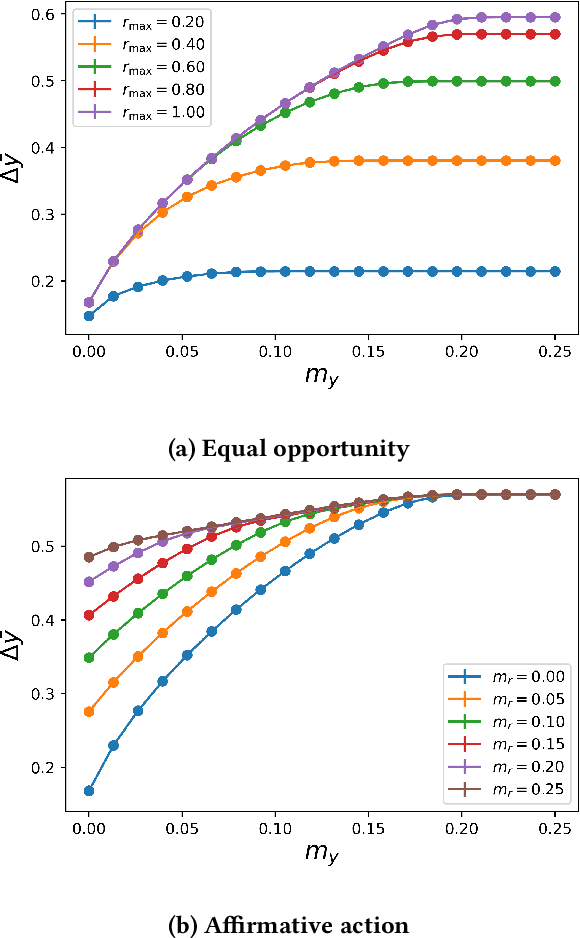
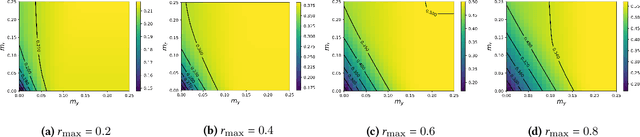
Explicit and implicit bias clouds human judgement, leading to discriminatory treatment of minority groups. A fundamental goal of algorithmic fairness is to avoid the pitfalls in human judgement by learning policies that improve the overall outcomes while providing fair treatment to protected classes. In this paper, we propose a causal framework that learns optimal intervention policies from data subject to fairness constraints. We define two measures of treatment bias and infer best treatment assignment that minimizes the bias while optimizing overall outcome. We demonstrate that there is a dilemma of balancing fairness and overall benefit; however, allowing preferential treatment to protected classes in certain circumstances (affirmative action) can dramatically improve the overall benefit while also preserving fairness. We apply our framework to data containing student outcomes on standardized tests and show how it can be used to design real-world policies that fairly improve student test scores. Our framework provides a principled way to learn fair treatment policies in real-world settings.
Learning Fair and Interpretable Representations via Linear Orthogonalization
Oct 28, 2019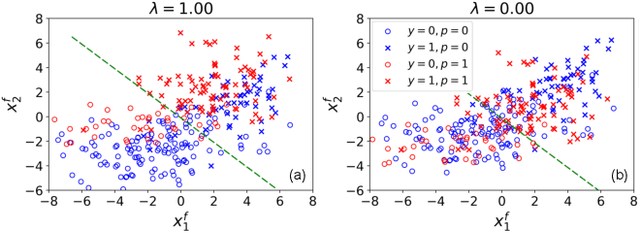

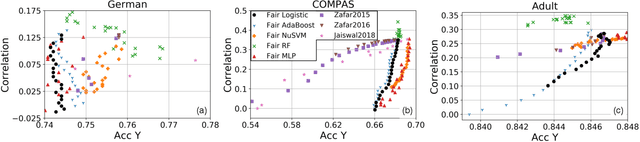

To reduce human error and prejudice, many high-stakes decisions have been turned over to machine algorithms. However, recent research suggests that this does not remove discrimination, and can perpetuate harmful stereotypes. While algorithms have been developed to improve fairness, they typically face at least one of three shortcomings: they are not interpretable, they lose significant accuracy compared to unbiased equivalents, or they are not transferable across models. To address these issues, we propose a geometric method that removes correlations between data and any number of protected variables. Further, we can control the strength of debiasing through an adjustable parameter to address the trade-off between model accuracy and fairness. The resulting features are interpretable and can be used with many popular models, such as linear regression, random forest and multilayer perceptrons. The resulting predictions are found to be more accurate and fair than several comparable fair AI algorithms across a variety of benchmark datasets. Our work shows that debiasing data is a simple and effective solution toward improving fairness.