 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Driven Estimation of Heterogeneous Treatment Effects
Jan 16, 2023
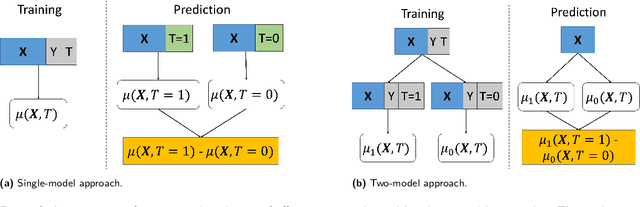
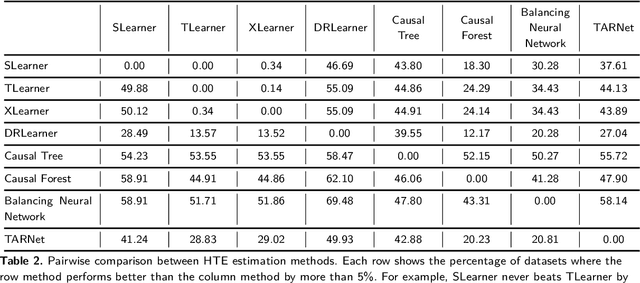
Estimating how a treatment affects different individuals, known as heterogeneous treatment effect estimation, is an important problem in empirical sciences. In the last few years, there has been a considerable interest in adapting machine learning algorithms to the problem of estimating heterogeneous effects from observational and experimental data. However, these algorithms often make strong assumptions about the observed features in the data and ignore the structure of the underlying causal model, which can lead to biased estimation. At the same time, the underlying causal mechanism is rarely known in real-world datasets, making it hard to take it into consideration. In this work, we provide a survey of state-of-the-art data-driven methods for heterogeneous treatment effect estimation using machine learning, broadly categorizing them as methods that focus on counterfactual prediction and methods that directly estimate the causal effect. We also provide an overview of a third category of methods which rely on structural causal models and learn the model structure from data. Our empirical evaluation under various underlying structural model mechanisms shows the advantages and deficiencies of existing estimators and of the metrics for measuring their performance.
Improving Data-driven Heterogeneous Treatment Effect Estimation Under Structure Uncertainty
Jun 25, 2022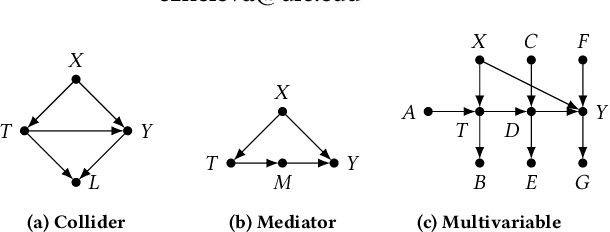
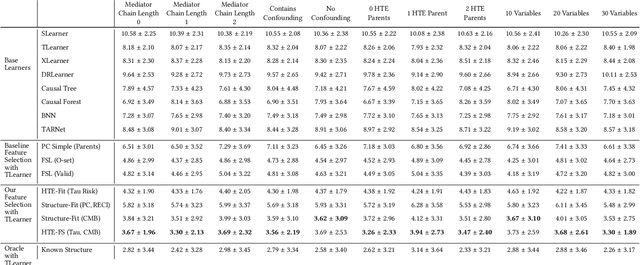
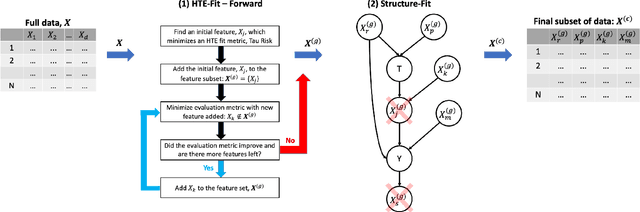
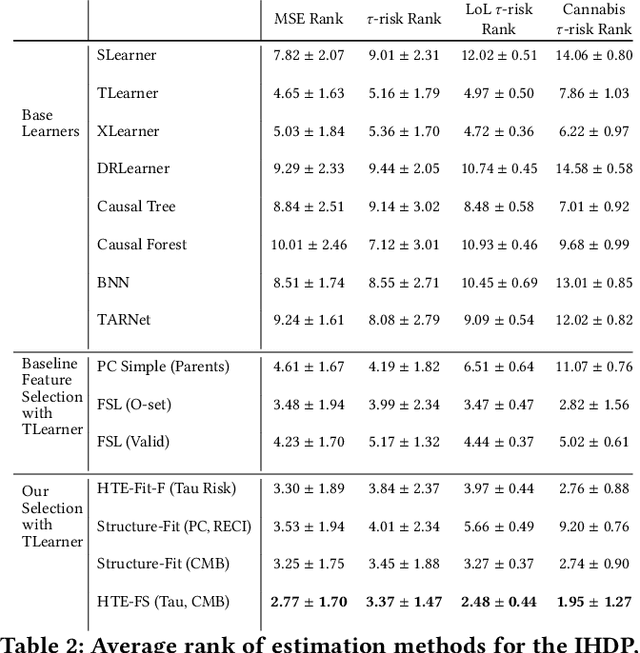
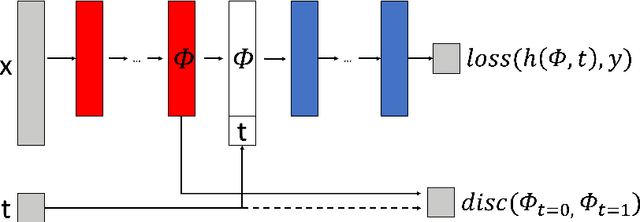
Estimating how a treatment affects units individually, known as heterogeneous treatment effect (HTE) estimation, is an essential part of decision-making and policy implementation. The accumulation of large amounts of data in many domains, such as healthcare and e-commerce, has led to increased interest in developing data-driven algorithms for estimating heterogeneous effects from observational and experimental data. However, these methods often make strong assumptions about the observed features and ignore the underlying causal model structure, which can lead to biased HTE estimation. At the same time, accounting for the causal structure of real-world data is rarely trivial since the causal mechanisms that gave rise to the data are typically unknown. To address this problem, we develop a feature selection method that considers each feature's value for HTE estimation and learns the relevant parts of the causal structure from data. We provide strong empirical evidence that our method improves existing data-driven HTE estimation methods under arbitrary underlying causal structures. Our results on synthetic, semi-synthetic, and real-world datasets show that our feature selection algorithm leads to lower HTE estimation error.
Heterogeneous Peer Effects in the Linear Threshold Model
Jan 27, 2022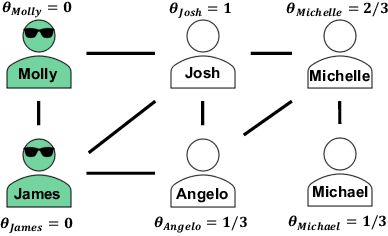
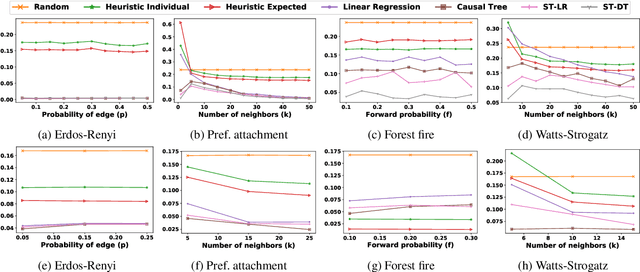
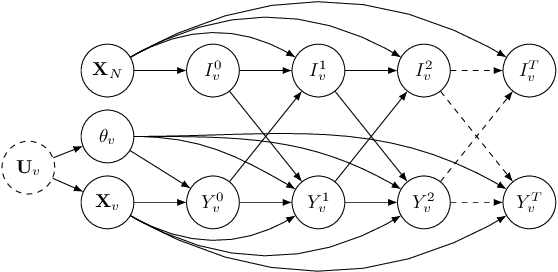
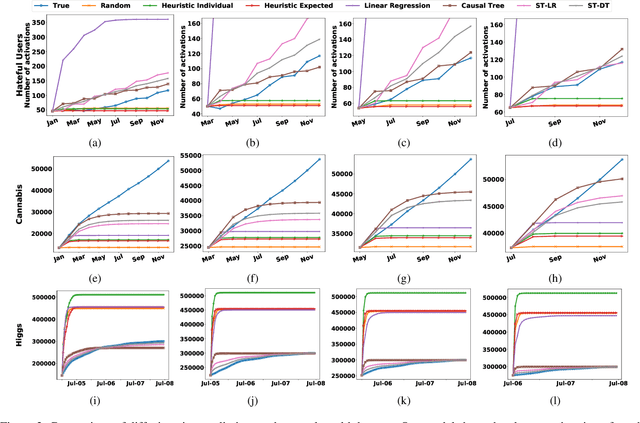
The Linear Threshold Model is a widely used model that describes how information diffuses through a social network. According to this model, an individual adopts an idea or product after the proportion of their neighbors who have adopted it reaches a certain threshold. Typical applications of the Linear Threshold Model assume that thresholds are either the same for all network nodes or randomly distributed, even though some people may be more susceptible to peer pressure than others. To address individual-level differences, we propose causal inference methods for estimating individual thresholds that can more accurately predict whether and when individuals will be affected by their peers. We introduce the concept of heterogeneous peer effects and develop a Structural Causal Model which corresponds to the Linear Threshold Model and supports heterogeneous peer effect identification and estimation. We develop two algorithms for individual threshold estimation, one based on causal trees and one based on causal meta-learners. Our experimental results on synthetic and real-world datasets show that our proposed models can better predict individual-level thresholds in the Linear Threshold Model and thus more precisely predict which nodes will get activated over time.
Heterogeneous Effects of Software Patches in a Multiplayer Online Battle Arena Game
Oct 27, 2021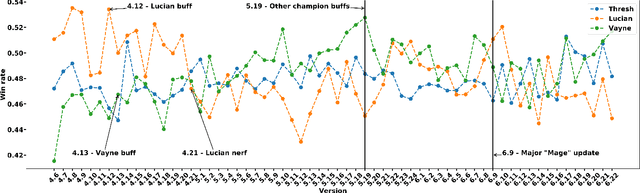
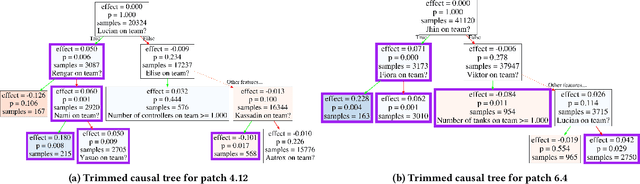

The popularity of online gaming has grown dramatically, driven in part by streaming and the billion-dollar e-sports industry. Online games regularly update their software to fix bugs, add functionality that improve the game's look and feel, and change the game mechanics to keep the games fun and challenging. An open question, however, is the impact of these changes on player performance and game balance, as well as how players adapt to these sudden changes. To address these questions, we use causal inference to measure the impact of software patches to League of Legends, a popular team-based multiplayer online game. We show that game patches have substantially different impacts on players depending on their skill level and whether they take breaks between games. We find that the gap between good and bad players increases after a patch, despite efforts to make gameplay more equal. Moreover, longer between-game breaks tend to improve player performance after patches. Overall, our results highlight the utility of causal inference, and specifically heterogeneous treatment effect estimation, as a tool to quantify the complex mechanisms of game balance and its interplay with players' performance.
* 9 pages, 11 figures
Learning Triggers for Heterogeneous Treatment Effects
Mar 09, 2019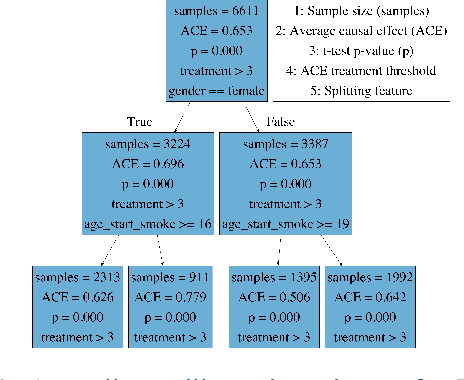
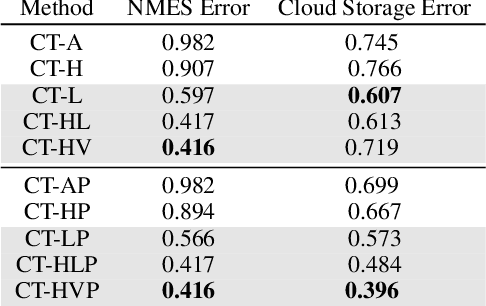
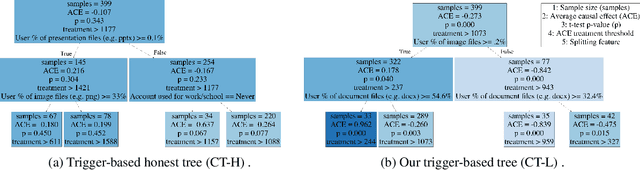
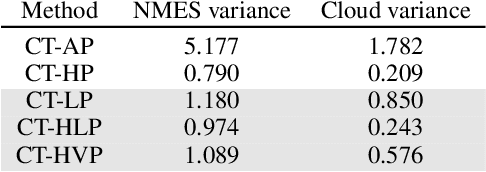
The causal effect of a treatment can vary from person to person based on their individual characteristics and predispositions. Mining for patterns of individual-level effect differences, a problem known as heterogeneous treatment effect estimation, has many important applications, from precision medicine to recommender systems. In this paper we define and study a variant of this problem in which an individual-level threshold in treatment needs to be reached, in order to trigger an effect. One of the main contributions of our work is that we do not only estimate heterogeneous treatment effects with fixed treatments but can also prescribe individualized treatments. We propose a tree-based learning method to find the heterogeneity in the treatment effects. Our experimental results on multiple datasets show that our approach can learn the triggers better than existing approaches.