 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial-LLM: Modeling User Behavior at Scale using Language Models and Social Network Data
Dec 31, 2023The proliferation of social network data has unlocked unprecedented opportunities for extensive, data-driven exploration of human behavior. The structural intricacies of social networks offer insights into various computational social science issues, particularly concerning social influence and information diffusion. However, modeling large-scale social network data comes with computational challenges. Though large language models make it easier than ever to model textual content, any advanced network representation methods struggle with scalability and efficient deployment to out-of-sample users. In response, we introduce a novel approach tailored for modeling social network data in user detection tasks. This innovative method integrates localized social network interactions with the capabilities of large language models. Operating under the premise of social network homophily, which posits that socially connected users share similarities, our approach is designed to address these challenges. We conduct a thorough evaluation of our method across seven real-world social network datasets, spanning a diverse range of topics and detection tasks, showcasing its applicability to advance research in computational social science.
Retweet-BERT: Political Leaning Detection Using Language Features and Information Diffusion on Social Networks
Jul 18, 2022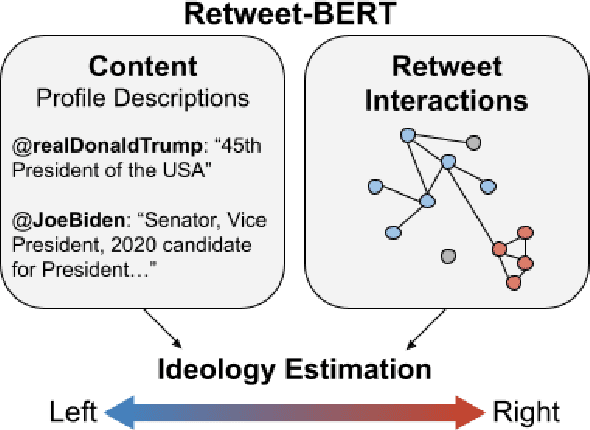
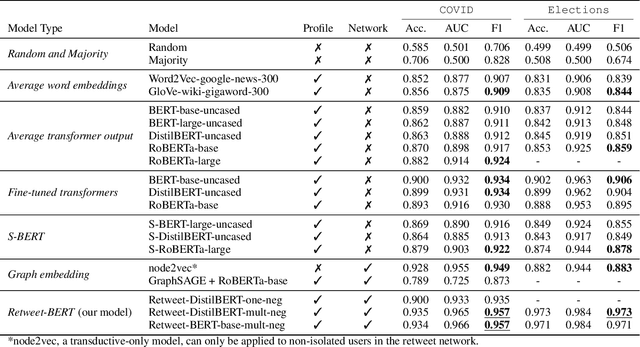
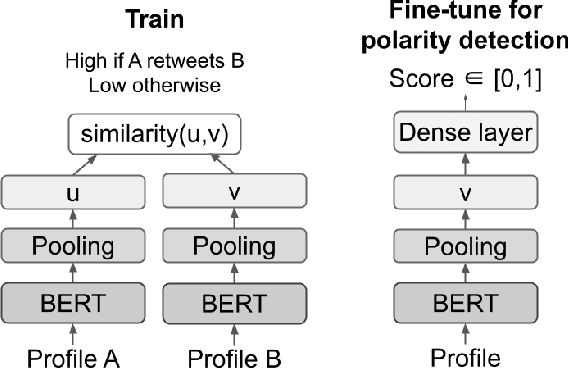

Estimating the political leanings of social media users is a challenging and ever more pressing problem given the increase in social media consumption. We introduce Retweet-BERT, a simple and scalable model to estimate the political leanings of Twitter users. Retweet-BERT leverages the retweet network structure and the language used in users' profile descriptions. Our assumptions stem from patterns of networks and linguistics homophily among people who share similar ideologies. Retweet-BERT demonstrates competitive performance against other state-of-the-art baselines, achieving 96%-97% macro-F1 on two recent Twitter datasets (a COVID-19 dataset and a 2020 United States presidential elections dataset). We also perform manual validation to validate the performance of Retweet-BERT on users not in the training data. Finally, in a case study of COVID-19, we illustrate the presence of political echo chambers on Twitter and show that it exists primarily among right-leaning users. Our code is open-sourced and our data is publicly available.
* 11 pages, 3 figures, 4 tables. arXiv admin note: text overlap with arXiv:2103.10979
Zero-shot meta-learning for small-scale data from human subjects
Mar 29, 2022
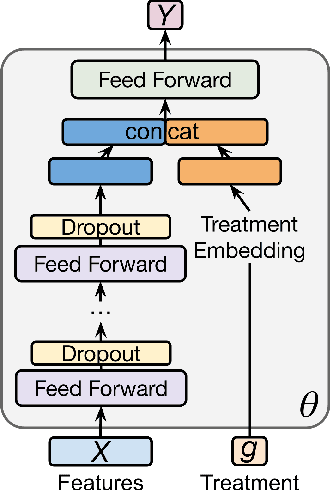
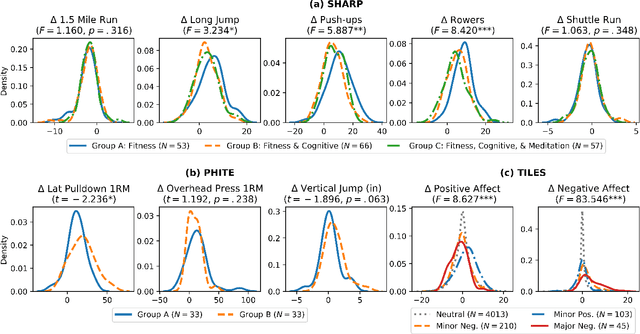
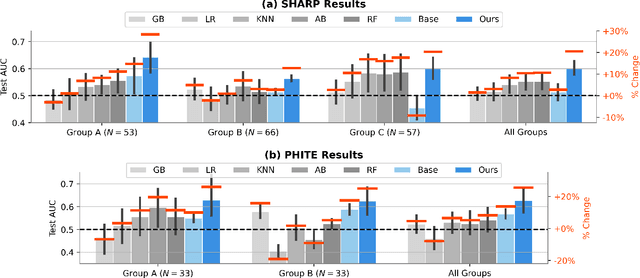
While developments in machine learning led to impressive performance gains on big data, many human subjects data are, in actuality, small and sparsely labeled. Existing methods applied to such data often do not easily generalize to out-of-sample subjects. Instead, models must make predictions on test data that may be drawn from a different distribution, a problem known as \textit{zero-shot learning}. To address this challenge, we develop an end-to-end framework using a meta-learning approach, which enables the model to rapidly adapt to a new prediction task with limited training data for out-of-sample test data. We use three real-world small-scale human subjects datasets (two randomized control studies and one observational study), for which we predict treatment outcomes for held-out treatment groups. Our model learns the latent treatment effects of each intervention and, by design, can naturally handle multi-task predictions. We show that our model performs the best holistically for each held-out group and especially when the test group is distinctly different from the training group. Our model has implications for improved generalization of small-size human studies to the wider population.
Heterogeneous Effects of Software Patches in a Multiplayer Online Battle Arena Game
Oct 27, 2021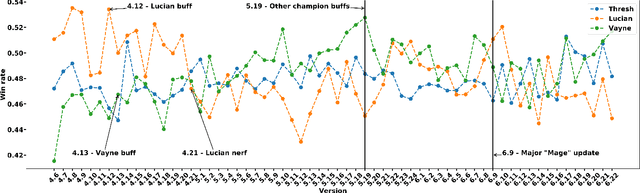
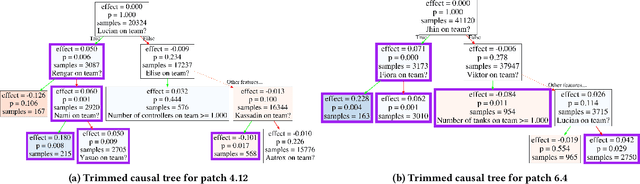

The popularity of online gaming has grown dramatically, driven in part by streaming and the billion-dollar e-sports industry. Online games regularly update their software to fix bugs, add functionality that improve the game's look and feel, and change the game mechanics to keep the games fun and challenging. An open question, however, is the impact of these changes on player performance and game balance, as well as how players adapt to these sudden changes. To address these questions, we use causal inference to measure the impact of software patches to League of Legends, a popular team-based multiplayer online game. We show that game patches have substantially different impacts on players depending on their skill level and whether they take breaks between games. We find that the gap between good and bad players increases after a patch, despite efforts to make gameplay more equal. Moreover, longer between-game breaks tend to improve player performance after patches. Overall, our results highlight the utility of causal inference, and specifically heterogeneous treatment effect estimation, as a tool to quantify the complex mechanisms of game balance and its interplay with players' performance.
* 9 pages, 11 figures
Individualized Context-Aware Tensor Factorization for Online Games Predictions
Feb 22, 2021

Individual behavior and decisions are substantially influenced by their contexts, such as location, environment, and time. Changes along these dimensions can be readily observed in Multiplayer Online Battle Arena games (MOBA), where players face different in-game settings for each match and are subject to frequent game patches. Existing methods utilizing contextual information generalize the effect of a context over the entire population, but contextual information tailored to each individual can be more effective. To achieve this, we present the Neural Individualized Context-aware Embeddings (NICE) model for predicting user performance and game outcomes. Our proposed method identifies individual behavioral differences in different contexts by learning latent representations of users and contexts through non-negative tensor factorization. Using a dataset from the MOBA game League of Legends, we demonstrate that our model substantially improves the prediction of winning outcome, individual user performance, and user engagement.