 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Millions of Tweets to Actionable Insights: Leveraging LLMs for User Profiling
May 09, 2025



Social media user profiling through content analysis is crucial for tasks like misinformation detection, engagement prediction, hate speech monitoring, and user behavior modeling. However, existing profiling techniques, including tweet summarization, attribute-based profiling, and latent representation learning, face significant limitations: they often lack transferability, produce non-interpretable features, require large labeled datasets, or rely on rigid predefined categories that limit adaptability. We introduce a novel large language model (LLM)-based approach that leverages domain-defining statements, which serve as key characteristics outlining the important pillars of a domain as foundations for profiling. Our two-stage method first employs semi-supervised filtering with a domain-specific knowledge base, then generates both abstractive (synthesized descriptions) and extractive (representative tweet selections) user profiles. By harnessing LLMs' inherent knowledge with minimal human validation, our approach is adaptable across domains while reducing the need for large labeled datasets. Our method generates interpretable natural language user profiles, condensing extensive user data into a scale that unlocks LLMs' reasoning and knowledge capabilities for downstream social network tasks. We contribute a Persian political Twitter (X) dataset and an LLM-based evaluation framework with human validation. Experimental results show our method significantly outperforms state-of-the-art LLM-based and traditional methods by 9.8%, demonstrating its effectiveness in creating flexible, adaptable, and interpretable user profiles.
Personality Analysis for Social Media Users using Arabic language and its Effect on Sentiment Analysis
Jul 08, 2024Social media is heading toward personalization more and more, where individuals reveal their beliefs, interests, habits, and activities, simply offering glimpses into their personality traits. This study, explores the correlation between the use of Arabic language on twitter, personality traits and its impact on sentiment analysis. We indicated the personality traits of users based on the information extracted from their profile activities, and the content of their tweets. Our analysis incorporated linguistic features, profile statistics (including gender, age, bio, etc.), as well as additional features like emoticons. To obtain personality data, we crawled the timelines and profiles of users who took the 16personalities test in Arabic on 16personalities.com. Our dataset comprised 3,250 users who shared their personality results on twitter. We implemented various machine learning techniques, to reveal personality traits and developed a dedicated model for this purpose, achieving a 74.86% accuracy rate with BERT, analysis of this dataset proved that linguistic features, profile features and derived model can be used to differentiate between different personality traits. Furthermore, our findings demonstrated that personality affect sentiment in social media. This research contributes to the ongoing efforts in developing robust understanding of the relation between human behaviour on social media and personality features for real-world applications, such as political discourse analysis, and public opinion tracking.
COfEE: A Comprehensive Ontology for Event Extraction from text, with an online annotation tool
Aug 01, 2021


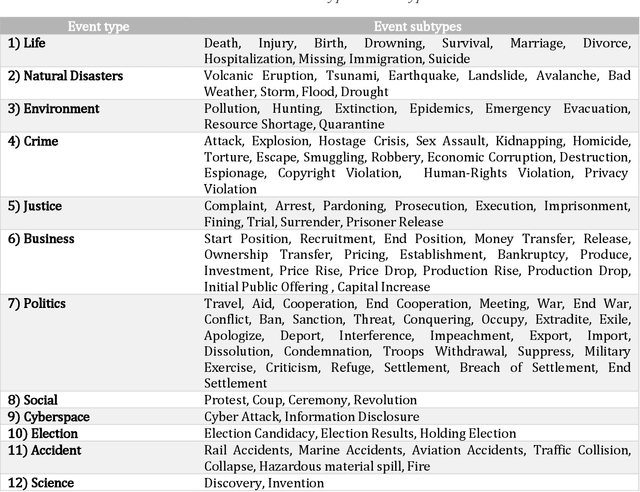
Data is published on the web over time in great volumes, but majority of the data is unstructured, making it hard to understand and difficult to interpret. Information Extraction (IE) methods extract structured information from unstructured data. One of the challenging IE tasks is Event Extraction (EE) which seeks to derive information about specific incidents and their actors from the text. EE is useful in many domains such as building a knowledge base, information retrieval, summarization and online monitoring systems. In the past decades, some event ontologies like ACE, CAMEO and ICEWS were developed to define event forms, actors and dimensions of events observed in the text. These event ontologies still have some shortcomings such as covering only a few topics like political events, having inflexible structure in defining argument roles, lack of analytical dimensions, and complexity in choosing event sub-types. To address these concerns, we propose an event ontology, namely COfEE, that incorporates both expert domain knowledge, previous ontologies and a data-driven approach for identifying events from text. COfEE consists of two hierarchy levels (event types and event sub-types) that include new categories relating to environmental issues, cyberspace, criminal activity and natural disasters which need to be monitored instantly. Also, dynamic roles according to each event sub-type are defined to capture various dimensions of events. In a follow-up experiment, the proposed ontology is evaluated on Wikipedia events, and it is shown to be general and comprehensive. Moreover, in order to facilitate the preparation of gold-standard data for event extraction, a language-independent online tool is presented based on COfEE.
Joint Event Extraction along Shortest Dependency Paths using Graph Convolutional Networks
Mar 19, 2020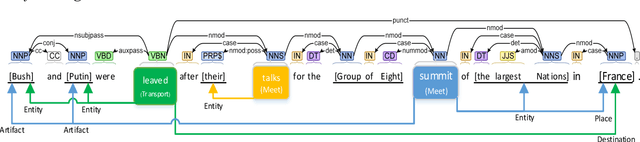

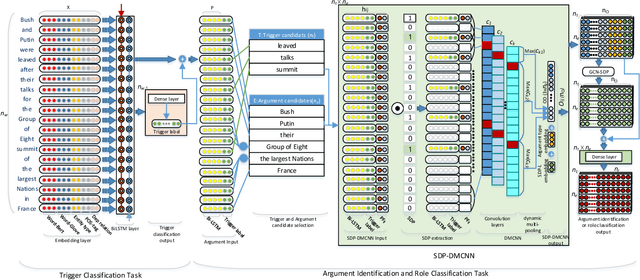
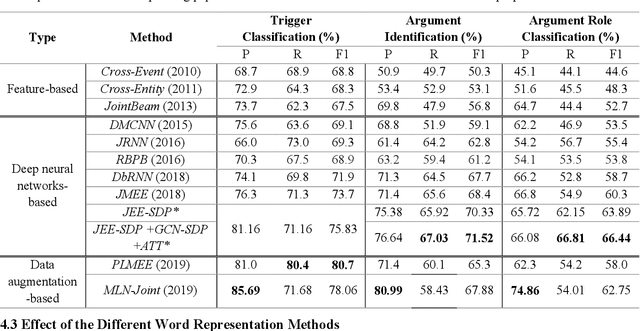
Event extraction (EE) is one of the core information extraction tasks, whose purpose is to automatically identify and extract information about incidents and their actors from texts. This may be beneficial to several domains such as knowledge bases, question answering, information retrieval and summarization tasks, to name a few. The problem of extracting event information from texts is longstanding and usually relies on elaborately designed lexical and syntactic features, which, however, take a large amount of human effort and lack generalization. More recently, deep neural network approaches have been adopted as a means to learn underlying features automatically. However, existing networks do not make full use of syntactic features, which play a fundamental role in capturing very long-range dependencies. Also, most approaches extract each argument of an event separately without considering associations between arguments which ultimately leads to low efficiency, especially in sentences with multiple events. To address the two above-referred problems, we propose a novel joint event extraction framework that aims to extract multiple event triggers and arguments simultaneously by introducing shortest dependency path (SDP) in the dependency graph. We do this by eliminating irrelevant words in the sentence, thus capturing long-range dependencies. Also, an attention-based graph convolutional network is proposed, to carry syntactically related information along the shortest paths between argument candidates that captures and aggregates the latent associations between arguments; a problem that has been overlooked by most of the literature. Our results show a substantial improvement over state-of-the-art methods.
DeepLink: A Novel Link Prediction Framework based on Deep Learning
Jul 27, 2018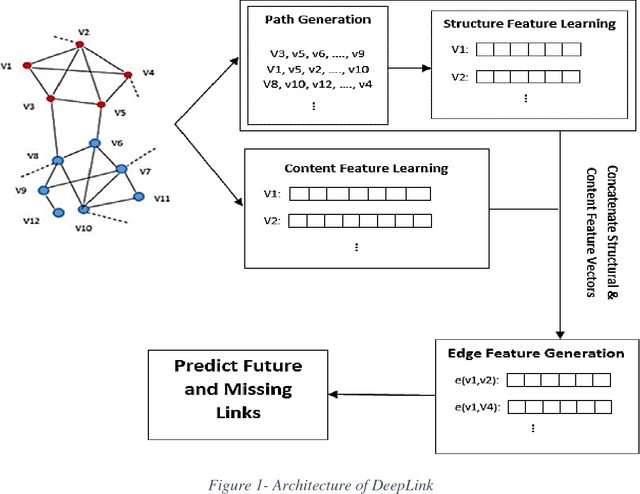

Recently, link prediction has attracted more attentions from various disciplines such as computer science, bioinformatics and economics. In this problem, unknown links between nodes are discovered based on numerous information such as network topology, profile information and user generated contents. Most of the previous researchers have focused on the structural features of the networks. While the recent researches indicate that contextual information can change the network topology. Although, there are number of valuable researches which combine structural and content information, but they face with the scalability issue due to feature engineering. Because, majority of the extracted features are obtained by a supervised or semi supervised algorithm. Moreover, the existing features are not general enough to indicate good performance on different networks with heterogeneous structures. Besides, most of the previous researches are presented for undirected and unweighted networks. In this paper, a novel link prediction framework called "DeepLink" is presented based on deep learning techniques. In contrast to the previous researches which fail to automatically extract best features for the link prediction, deep learning reduces the manual feature engineering. In this framework, both the structural and content information of the nodes are employed. The framework can use different structural feature vectors, which are prepared by various link prediction methods. It considers all proximity orders that are presented in a network during the structural feature learning. We have evaluated the performance of DeepLink on two real social network datasets including Telegram and irBlogs. On both datasets, the proposed framework outperforms several structural and hybrid approaches for link prediction problem.
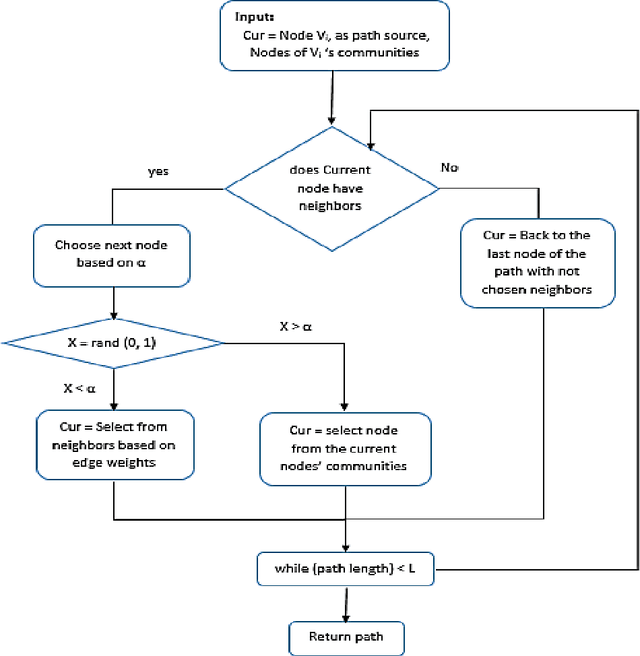
Community Aware Random Walk for Network Embedding
Feb 19, 2018
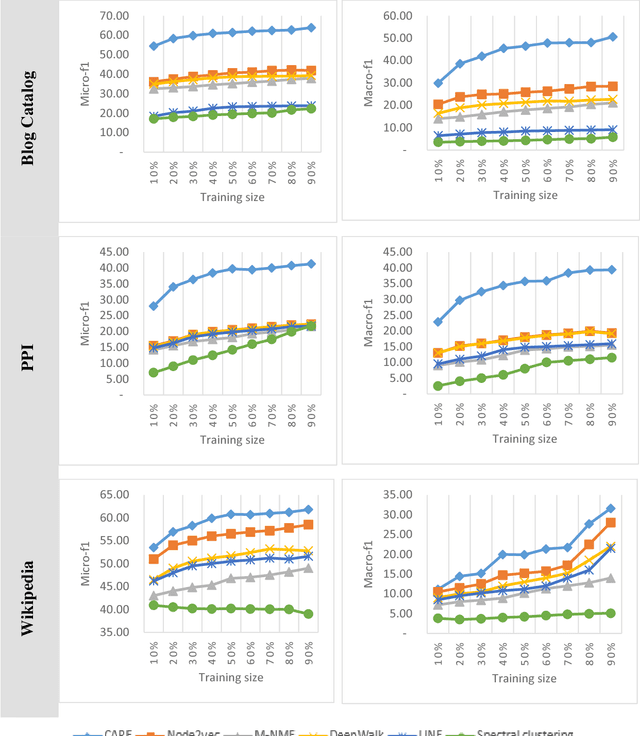
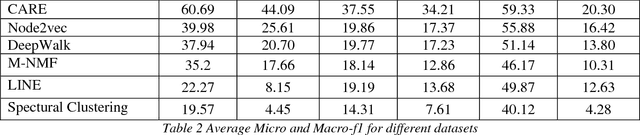
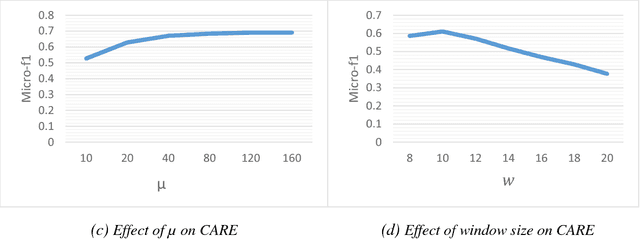
Social network analysis provides meaningful information about behavior of network members that can be used for diverse applications such as classification, link prediction. However, network analysis is computationally expensive because of feature learning for different applications. In recent years, many researches have focused on feature learning methods in social networks. Network embedding represents the network in a lower dimensional representation space with the same properties which presents a compressed representation of the network. In this paper, we introduce a novel algorithm named "CARE" for network embedding that can be used for different types of networks including weighted, directed and complex. Current methods try to preserve local neighborhood information of nodes, whereas the proposed method utilizes local neighborhood and community information of network nodes to cover both local and global structure of social networks. CARE builds customized paths, which are consisted of local and global structure of network nodes, as a basis for network embedding and uses the Skip-gram model to learn representation vector of nodes. Subsequently, stochastic gradient descent is applied to optimize our objective function and learn the final representation of nodes. Our method can be scalable when new nodes are appended to network without information loss. Parallelize generation of customized random walks is also used for speeding up CARE. We evaluate the performance of CARE on multi label classification and link prediction tasks. Experimental results on various networks indicate that the proposed method outperforms others in both Micro and Macro-f1 measures for different size of training data.
* 17 pages, 3 figures, 4 Tables