 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOfEE: A Comprehensive Ontology for Event Extraction from text, with an online annotation tool
Paper and Code



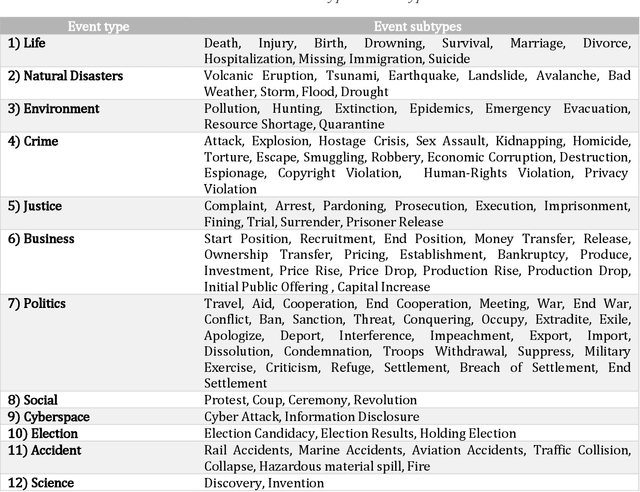
Data is published on the web over time in great volumes, but majority of the data is unstructured, making it hard to understand and difficult to interpret. Information Extraction (IE) methods extract structured information from unstructured data. One of the challenging IE tasks is Event Extraction (EE) which seeks to derive information about specific incidents and their actors from the text. EE is useful in many domains such as building a knowledge base, information retrieval, summarization and online monitoring systems. In the past decades, some event ontologies like ACE, CAMEO and ICEWS were developed to define event forms, actors and dimensions of events observed in the text. These event ontologies still have some shortcomings such as covering only a few topics like political events, having inflexible structure in defining argument roles, lack of analytical dimensions, and complexity in choosing event sub-types. To address these concerns, we propose an event ontology, namely COfEE, that incorporates both expert domain knowledge, previous ontologies and a data-driven approach for identifying events from text. COfEE consists of two hierarchy levels (event types and event sub-types) that include new categories relating to environmental issues, cyberspace, criminal activity and natural disasters which need to be monitored instantly. Also, dynamic roles according to each event sub-type are defined to capture various dimensions of events. In a follow-up experiment, the proposed ontology is evaluated on Wikipedia events, and it is shown to be general and comprehensive. Moreover, in order to facilitate the preparation of gold-standard data for event extraction, a language-independent online tool is presented based on COfEE.