 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepMatch: Quantifying Cross-Instance Similarities in Representation Space
Paper and Code
Oct 12, 2024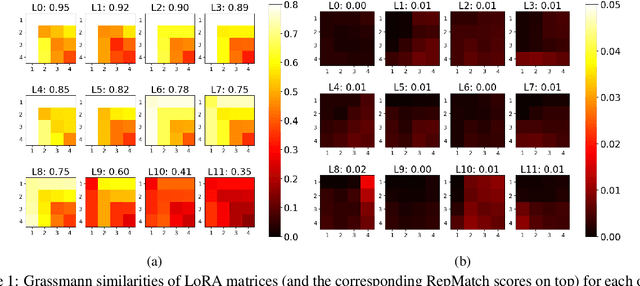

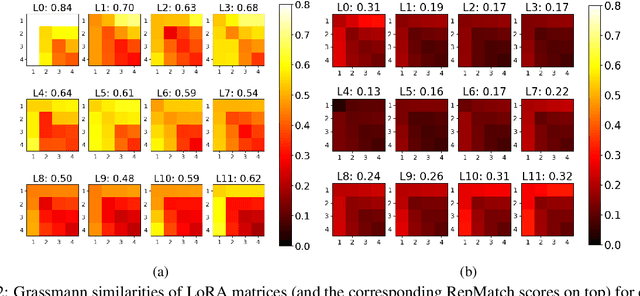
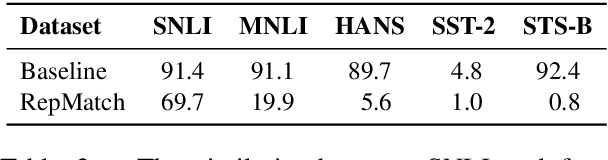
Advances in dataset analysis techniques have enabled more sophisticated approaches to analyzing and characterizing training data instances, often categorizing data based on attributes such as ``difficulty''. In this work, we introduce RepMatch, a novel method that characterizes data through the lens of similarity. RepMatch quantifies the similarity between subsets of training instances by comparing the knowledge encoded in models trained on them, overcoming the limitations of existing analysis methods that focus solely on individual instances and are restricted to within-dataset analysis. Our framework allows for a broader evaluation, enabling similarity comparisons across arbitrary subsets of instances, supporting both dataset-to-dataset and instance-to-dataset analyses. We validate the effectiveness of RepMatch across multiple NLP tasks, datasets, and models. Through extensive experimentation, we demonstrate that RepMatch can effectively compare datasets, identify more representative subsets of a dataset (that lead to better performance than randomly selected subsets of equivalent size), and uncover heuristics underlying the construction of some challenge datasets.