 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShaking Up VLMs: Comparing Transformers and Structured State Space Models for Vision & Language Modeling
Paper and Code
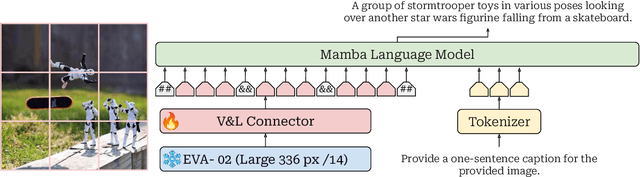
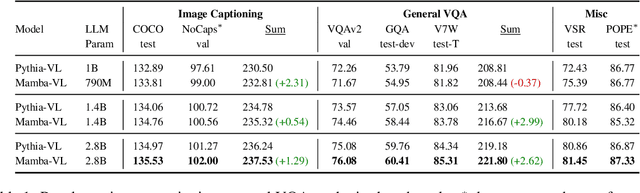
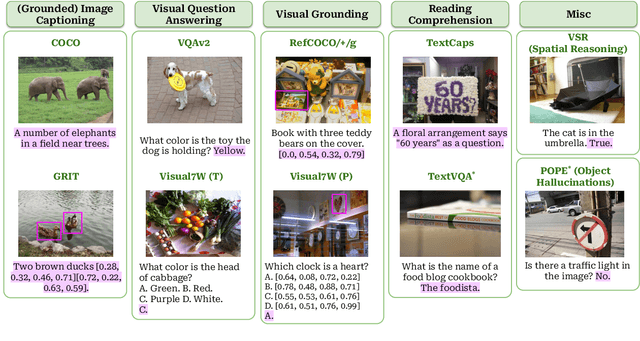
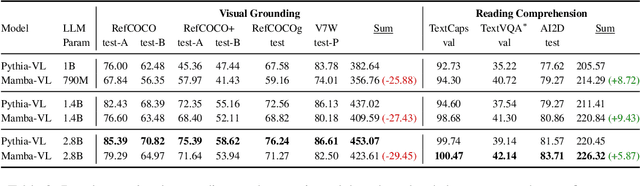
This study explores replacing Transformers in Visual Language Models (VLMs) with Mamba, a recent structured state space model (SSM) that demonstrates promising performance in sequence modeling. We test models up to 3B parameters under controlled conditions, showing that Mamba-based VLMs outperforms Transformers-based VLMs in captioning, question answering, and reading comprehension. However, we find that Transformers achieve greater performance in visual grounding and the performance gap widens with scale. We explore two hypotheses to explain this phenomenon: 1) the effect of task-agnostic visual encoding on the updates of the hidden states, and 2) the difficulty in performing visual grounding from the perspective of in-context multimodal retrieval. Our results indicate that a task-aware encoding yields minimal performance gains on grounding, however, Transformers significantly outperform Mamba at in-context multimodal retrieval. Overall, Mamba shows promising performance on tasks where the correct output relies on a summary of the image but struggles when retrieval of explicit information from the context is required.