 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvanced Natural-based interaction for the ITAlian language: LLaMAntino-3-ANITA
Paper and Code
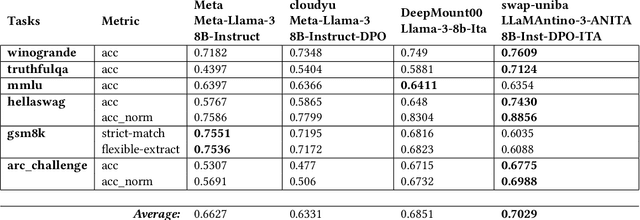

In the pursuit of advancing natural language processing for the Italian language, we introduce a state-of-the-art Large Language Model (LLM) based on the novel Meta LLaMA-3 model: LLaMAntino-3-ANITA-8B-Inst-DPO-ITA. We fine-tuned the original 8B parameters instruction tuned model using the Supervised Fine-tuning (SFT) technique on the English and Italian language datasets in order to improve the original performance. Consequently, a Dynamic Preference Optimization (DPO) process has been used to align preferences, avoid dangerous and inappropriate answers, and limit biases and prejudices. Our model leverages the efficiency of QLoRA to fine-tune the model on a smaller portion of the original model weights and then adapt the model specifically for the Italian linguistic structure, achieving significant improvements in both performance and computational efficiency. Concurrently, DPO is employed to refine the model's output, ensuring that generated content aligns with quality answers. The synergy between SFT, QLoRA's parameter efficiency and DPO's user-centric optimization results in a robust LLM that excels in a variety of tasks, including but not limited to text completion, zero-shot classification, and contextual understanding. The model has been extensively evaluated over standard benchmarks for the Italian and English languages, showing outstanding results. The model is freely available over the HuggingFace hub and, examples of use can be found in our GitHub repository. https://huggingface.co/swap-uniba/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA