 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEB-NeRD: A Large-Scale Dataset for News Recommendation
Oct 04, 2024
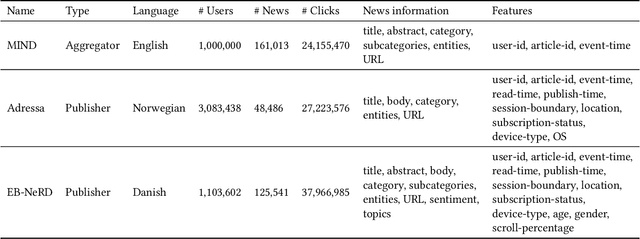

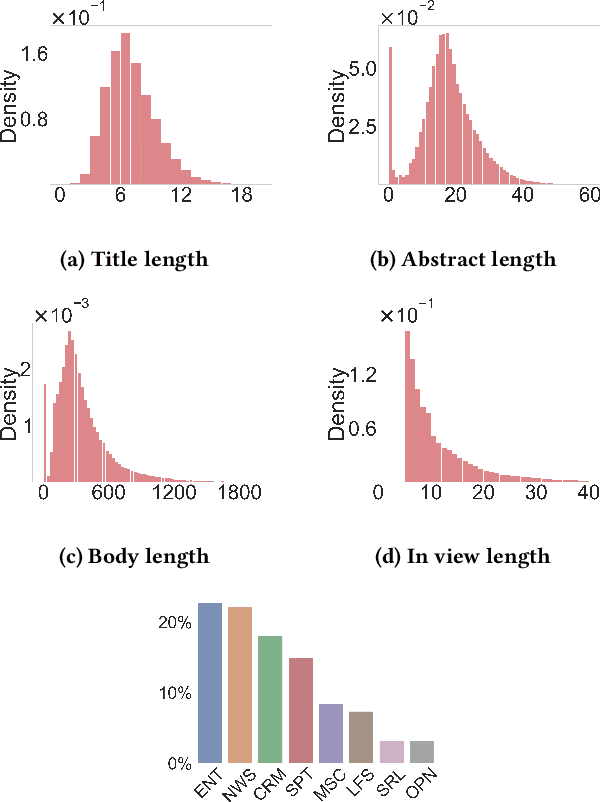
Personalized content recommendations have been pivotal to the content experience in digital media from video streaming to social networks. However, several domain specific challenges have held back adoption of recommender systems in news publishing. To address these challenges, we introduce the Ekstra Bladet News Recommendation Dataset (EB-NeRD). The dataset encompasses data from over a million unique users and more than 37 million impression logs from Ekstra Bladet. It also includes a collection of over 125,000 Danish news articles, complete with titles, abstracts, bodies, and metadata, such as categories. EB-NeRD served as the benchmark dataset for the RecSys '24 Challenge, where it was demonstrated how the dataset can be used to address both technical and normative challenges in designing effective and responsible recommender systems for news publishing. The dataset is available at: https://recsys.eb.dk.
RecSys Challenge 2024: Balancing Accuracy and Editorial Values in News Recommendations
Sep 30, 2024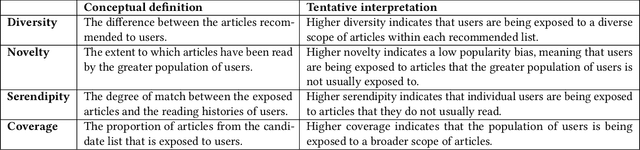
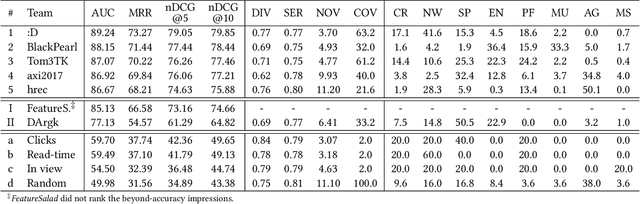
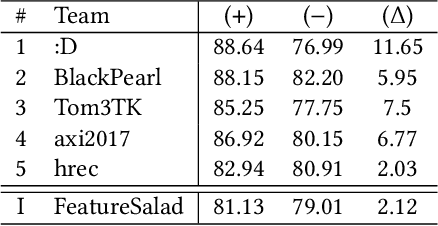
The RecSys Challenge 2024 aims to advance news recommendation by addressing both the technical and normative challenges inherent in designing effective and responsible recommender systems for news publishing. This paper describes the challenge, including its objectives, problem setting, and the dataset provided by the Danish news publishers Ekstra Bladet and JP/Politikens Media Group ("Ekstra Bladet"). The challenge explores the unique aspects of news recommendation, such as modeling user preferences based on behavior, accounting for the influence of the news agenda on user interests, and managing the rapid decay of news items. Additionally, the challenge embraces normative complexities, investigating the effects of recommender systems on news flow and their alignment with editorial values. We summarize the challenge setup, dataset characteristics, and evaluation metrics. Finally, we announce the winners and highlight their contributions. The dataset is available at: https://recsys.eb.dk.
Advanced Natural-based interaction for the ITAlian language: LLaMAntino-3-ANITA
May 11, 2024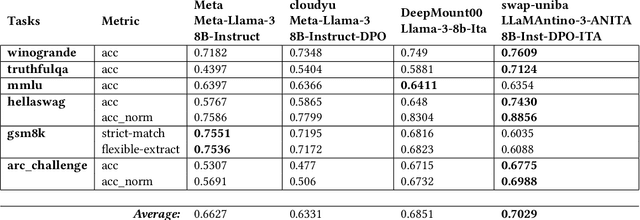

In the pursuit of advancing natural language processing for the Italian language, we introduce a state-of-the-art Large Language Model (LLM) based on the novel Meta LLaMA-3 model: LLaMAntino-3-ANITA-8B-Inst-DPO-ITA. We fine-tuned the original 8B parameters instruction tuned model using the Supervised Fine-tuning (SFT) technique on the English and Italian language datasets in order to improve the original performance. Consequently, a Dynamic Preference Optimization (DPO) process has been used to align preferences, avoid dangerous and inappropriate answers, and limit biases and prejudices. Our model leverages the efficiency of QLoRA to fine-tune the model on a smaller portion of the original model weights and then adapt the model specifically for the Italian linguistic structure, achieving significant improvements in both performance and computational efficiency. Concurrently, DPO is employed to refine the model's output, ensuring that generated content aligns with quality answers. The synergy between SFT, QLoRA's parameter efficiency and DPO's user-centric optimization results in a robust LLM that excels in a variety of tasks, including but not limited to text completion, zero-shot classification, and contextual understanding. The model has been extensively evaluated over standard benchmarks for the Italian and English languages, showing outstanding results. The model is freely available over the HuggingFace hub and, examples of use can be found in our GitHub repository. https://huggingface.co/swap-uniba/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA
LLaMAntino: LLaMA 2 Models for Effective Text Generation in Italian Language
Dec 15, 2023


Large Language Models represent state-of-the-art linguistic models designed to equip computers with the ability to comprehend natural language. With its exceptional capacity to capture complex contextual relationships, the LLaMA (Large Language Model Meta AI) family represents a novel advancement in the field of natural language processing by releasing foundational models designed to improve the natural language understanding abilities of the transformer architecture thanks to their large amount of trainable parameters (7, 13, and 70 billion parameters). In many natural language understanding tasks, these models obtain the same performances as private company models such as OpenAI Chat-GPT with the advantage to make publicly available weights and code for research and commercial uses. In this work, we investigate the possibility of Language Adaptation for LLaMA models, explicitly focusing on addressing the challenge of Italian Language coverage. Adopting an open science approach, we explore various tuning approaches to ensure a high-quality text generated in Italian suitable for common tasks in this underrepresented language in the original models' datasets. We aim to release effective text generation models with strong linguistic properties for many tasks that seem challenging using multilingual or general-purpose LLMs. By leveraging an open science philosophy, this study contributes to Language Adaptation strategies for the Italian language by introducing the novel LLaMAntino family of Italian LLMs.
GM-CTSC at SemEval-2020 Task 1: Gaussian Mixtures Cross Temporal Similarity Clustering
May 20, 2020


This paper describes the system proposed for the SemEval-2020 Task 1: Unsupervised Lexical Semantic Change Detection. We focused our approach on the detection problem. Given the semantics of words captured by temporal word embeddings in different time periods, we investigate the use of unsupervised methods to detect when the target word has gained or loosed senses. To this end, we defined a new algorithm based on Gaussian Mixture Models to cluster the target similarities computed over the two periods. We compared the proposed approach with a number of similarity-based thresholds. We found that, although the performance of the detection methods varies across the word embedding algorithms, the combination of Gaussian Mixture with Temporal Referencing resulted in our best system.