 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgexVLM2Vec: Adapting LVLM-based embedding models to multilinguality using Self-Knowledge Distillation
Mar 12, 2025In the current literature, most embedding models are based on the encoder-only transformer architecture to extract a dense and meaningful representation of the given input, which can be a text, an image, and more. With the recent advances in language modeling thanks to the introduction of Large Language Models, the possibility of extracting embeddings from these large and extensively trained models has been explored. However, current studies focus on textual embeddings in English, which is also the main language on which these models have been trained. Furthermore, there are very few models that consider multimodal and multilingual input. In light of this, we propose an adaptation methodology for Large Vision-Language Models trained on English language data to improve their performance in extracting multilingual and multimodal embeddings. Finally, we design and introduce a benchmark to evaluate the effectiveness of multilingual and multimodal embedding models.
Exploring the Word Sense Disambiguation Capabilities of Large Language Models
Mar 11, 2025

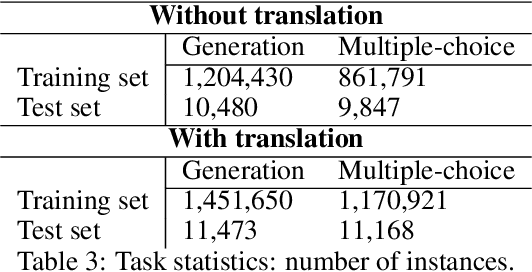
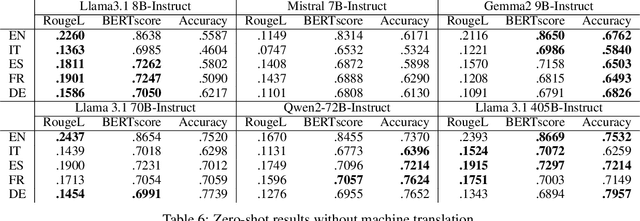
Word Sense Disambiguation (WSD) is a historical task in computational linguistics that has received much attention over the years. However, with the advent of Large Language Models (LLMs), interest in this task (in its classical definition) has decreased. In this study, we evaluate the performance of various LLMs on the WSD task. We extend a previous benchmark (XL-WSD) to re-design two subtasks suitable for LLM: 1) given a word in a sentence, the LLM must generate the correct definition; 2) given a word in a sentence and a set of predefined meanings, the LLM must select the correct one. The extended benchmark is built using the XL-WSD and BabelNet. The results indicate that LLMs perform well in zero-shot learning but cannot surpass current state-of-the-art methods. However, a fine-tuned model with a medium number of parameters outperforms all other models, including the state-of-the-art.
LLaMAntino: LLaMA 2 Models for Effective Text Generation in Italian Language
Dec 15, 2023


Large Language Models represent state-of-the-art linguistic models designed to equip computers with the ability to comprehend natural language. With its exceptional capacity to capture complex contextual relationships, the LLaMA (Large Language Model Meta AI) family represents a novel advancement in the field of natural language processing by releasing foundational models designed to improve the natural language understanding abilities of the transformer architecture thanks to their large amount of trainable parameters (7, 13, and 70 billion parameters). In many natural language understanding tasks, these models obtain the same performances as private company models such as OpenAI Chat-GPT with the advantage to make publicly available weights and code for research and commercial uses. In this work, we investigate the possibility of Language Adaptation for LLaMA models, explicitly focusing on addressing the challenge of Italian Language coverage. Adopting an open science approach, we explore various tuning approaches to ensure a high-quality text generated in Italian suitable for common tasks in this underrepresented language in the original models' datasets. We aim to release effective text generation models with strong linguistic properties for many tasks that seem challenging using multilingual or general-purpose LLMs. By leveraging an open science philosophy, this study contributes to Language Adaptation strategies for the Italian language by introducing the novel LLaMAntino family of Italian LLMs.