 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Point-Based Framework for 3D Segmentation
Paper and Code
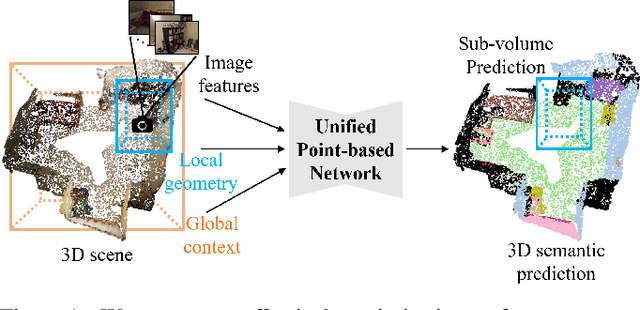

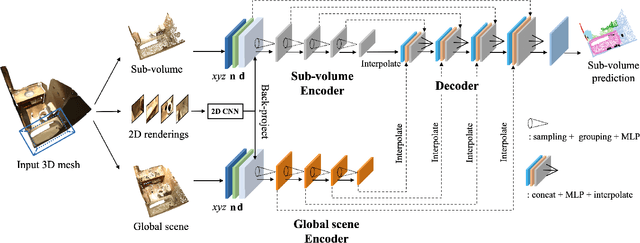
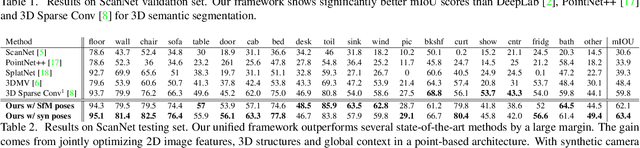
3D point cloud segmentation remains challenging for structureless and textureless regions. We present a new unified point-based framework for 3D point cloud segmentation that effectively optimizes pixel-level features, geometrical structures and global context priors of an entire scene. By back-projecting 2D image features into 3D coordinates, our network learns 2D textural appearance and 3D structural features in a unified framework. In addition, we investigate a global context prior to obtain a better prediction. We evaluate our framework on ScanNet online benchmark and show that our method outperforms several state-of-the-art approaches. We explore synthesizing camera poses in 3D reconstructed scenes for achieving higher performance. In-depth analysis on feature combinations and synthetic camera pose verify that features from different modalities benefit each other and dense camera pose sampling further improves the segmentation results.