 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence-to-sequence Automatic Speech Recognition with Word Embedding Regularization and Fused Decoding
Paper and Code
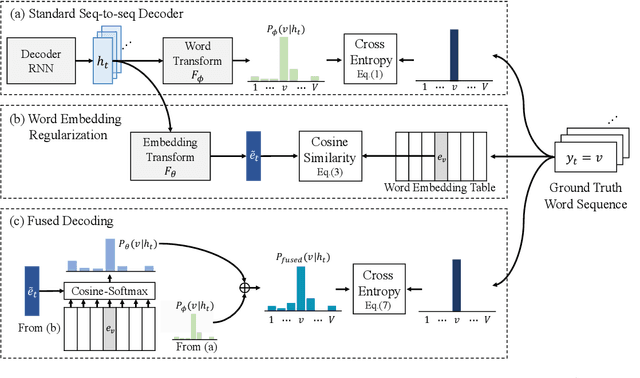

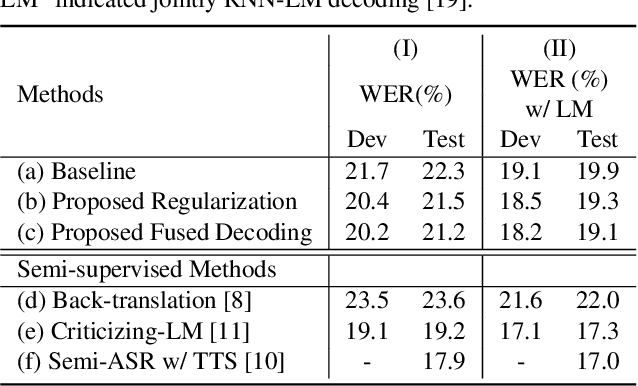
In this paper, we investigate the benefit that off-the-shelf word embedding can bring to the sequence-to-sequence (seq-to-seq) automatic speech recognition (ASR). We first introduced the word embedding regularization by maximizing the cosine similarity between a transformed decoder feature and the target word embedding. Based on the regularized decoder, we further proposed the fused decoding mechanism. This allows the decoder to consider the semantic consistency during decoding by absorbing the information carried by the transformed decoder feature, which is learned to be close to the target word embedding. Initial results on LibriSpeech demonstrated that pre-trained word embedding can significantly lower ASR recognition error with a negligible cost, and the choice of word embedding algorithms among Skip-gram, CBOW and BERT is important.