 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariable-Rate Learned Image Compression with Multi-Objective Optimization and Quantization-Reconstruction Offsets
Feb 29, 2024Achieving successful variable bitrate compression with computationally simple algorithms from a single end-to-end learned image or video compression model remains a challenge. Many approaches have been proposed, including conditional auto-encoders, channel-adaptive gains for the latent tensor or uniformly quantizing all elements of the latent tensor. This paper follows the traditional approach to vary a single quantization step size to perform uniform quantization of all latent tensor elements. However, three modifications are proposed to improve the variable rate compression performance. First, multi objective optimization is used for (post) training. Second, a quantization-reconstruction offset is introduced into the quantization operation. Third, variable rate quantization is used also for the hyper latent. All these modifications can be made on a pre-trained single-rate compression model by performing post training. The algorithms are implemented into three well-known image compression models and the achieved variable rate compression results indicate negligible or minimal compression performance loss compared to training multiple models. (Codes will be shared at https://github.com/InterDigitalInc/CompressAI)
Learned Disentangled Latent Representations for Scalable Image Coding for Humans and Machines
Jan 10, 2023



As an increasing amount of image and video content will be analyzed by machines, there is demand for a new codec paradigm that is capable of compressing visual input primarily for the purpose of computer vision inference, while secondarily supporting input reconstruction. In this work, we propose a learned compression architecture that can be used to build such a codec. We introduce a novel variational formulation that explicitly takes feature data relevant to the desired inference task as input at the encoder side. As such, our learned scalable image codec encodes and transmits two disentangled latent representations for object detection and input reconstruction. We note that compared to relevant benchmarks, our proposed scheme yields a more compact latent representation that is specialized for the inference task. Our experiments show that our proposed system achieves a bit rate savings of 40.6% on the primary object detection task compared to the current state-of-the-art, albeit with some degradation in performance for the secondary input reconstruction task.
Frequency-aware Learned Image Compression for Quality Scalability
Jan 03, 2023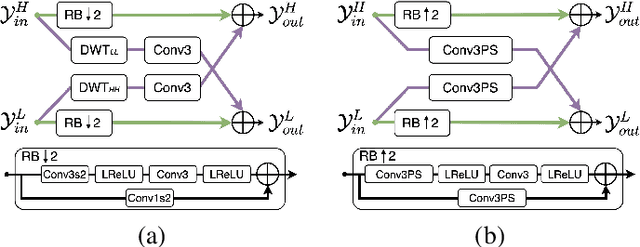
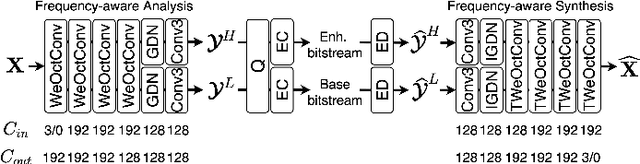

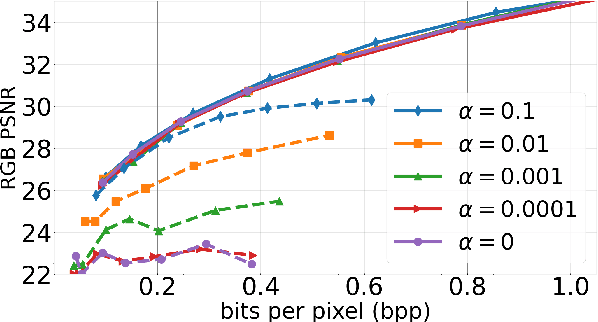
Spatial frequency analysis and transforms serve a central role in most engineered image and video lossy codecs, but are rarely employed in neural network (NN)-based approaches. We propose a novel NN-based image coding framework that utilizes forward wavelet transforms to decompose the input signal by spatial frequency. Our encoder generates separate bitstreams for each latent representation of low and high frequencies. This enables our decoder to selectively decode bitstreams in a quality-scalable manner. Hence, the decoder can produce an enhanced image by using an enhancement bitstream in addition to the base bitstream. Furthermore, our method is able to enhance only a specific region of interest (ROI) by using a corresponding part of the enhancement latent representation. Our experiments demonstrate that the proposed method shows competitive rate-distortion performance compared to several non-scalable image codecs. We also showcase the effectiveness of our two-level quality scalability, as well as its practicality in ROI quality enhancement.