 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariable-Rate Learned Image Compression with Multi-Objective Optimization and Quantization-Reconstruction Offsets
Feb 29, 2024Achieving successful variable bitrate compression with computationally simple algorithms from a single end-to-end learned image or video compression model remains a challenge. Many approaches have been proposed, including conditional auto-encoders, channel-adaptive gains for the latent tensor or uniformly quantizing all elements of the latent tensor. This paper follows the traditional approach to vary a single quantization step size to perform uniform quantization of all latent tensor elements. However, three modifications are proposed to improve the variable rate compression performance. First, multi objective optimization is used for (post) training. Second, a quantization-reconstruction offset is introduced into the quantization operation. Third, variable rate quantization is used also for the hyper latent. All these modifications can be made on a pre-trained single-rate compression model by performing post training. The algorithms are implemented into three well-known image compression models and the achieved variable rate compression results indicate negligible or minimal compression performance loss compared to training multiple models. (Codes will be shared at https://github.com/InterDigitalInc/CompressAI)
Learned Lossless Image Compression Through Interpolation With Low Complexity
Dec 26, 2022With the increasing popularity of deep learning in image processing, many learned lossless image compression methods have been proposed recently. One group of algorithms that have shown good performance are based on learned pixel-based auto-regressive models, however, their sequential nature prevents easily parallelized computations and leads to long decoding times. Another popular group of algorithms are based on scale-based auto-regressive models and can provide competitive compression performance while also enabling simple parallelization and much shorter decoding times. However, their major drawback are the used large neural networks and high computational complexity. This paper presents an interpolation based learned lossless image compression method which falls in the scale-based auto-regressive models group. The method achieves better than or on par compression performance with the recent scale-based auto-regressive models, yet requires more than 10x less neural network parameters and encoding/decoding computation complexity. These achievements are due to the contributions/findings in the overall system and neural network architecture design, such as sharing interpolator neural networks across different scales, using separate neural networks for different parameters of the probability distribution model and performing the processing in the YCoCg-R color space instead of the RGB color space.
Image Compression With Learned Lifting-Based DWT and Learned Tree-Based Entropy Models
Dec 07, 2022This paper explores learned image compression based on traditional and learned discrete wavelet transform (DWT) architectures and learned entropy models for coding DWT subband coefficients. A learned DWT is obtained through the lifting scheme with learned nonlinear predict and update filters. Several learned entropy models are proposed to exploit inter and intra-DWT subband coefficient dependencies, akin to traditional EZW, SPIHT, or EBCOT algorithms. Experimental results show that when the proposed learned entropy models are combined with traditional wavelet filters, such as the CDF 9/7 filters, compression performance that far exceeds that of JPEG2000 can be achieved. When the learned entropy models are combined with the learned DWT, compression performance increases further. The computations in the learned DWT and all entropy models, except one, can be simply parallelized, and the systems provide practical encoding and decoding times on GPUs.
A Learned Pixel-by-Pixel Lossless Image Compression Method with 59K Parameters and Parallel Decoding
Dec 02, 2022This paper considers lossless image compression and presents a learned compression system that can achieve state-of-the-art lossless compression performance but uses only 59K parameters, which is more than 30x less than other learned systems proposed recently in the literature. The explored system is based on a learned pixel-by-pixel lossless image compression method, where each pixel's probability distribution parameters are obtained by processing the pixel's causal neighborhood (i.e. previously encoded/decoded pixels) with a simple neural network comprising 59K parameters. This causality causes the decoder to operate sequentially, i.e. the neural network has to be evaluated for each pixel sequentially, which increases decoding time significantly with common GPU software and hardware. To reduce the decoding time, parallel decoding algorithms are proposed and implemented. The obtained lossless image compression system is compared to traditional and learned systems in the literature in terms of compression performance, encoding-decoding times and computational complexity.
End-to-End Learned Block-Based Image Compression with Block-Level Masked Convolutions and Asymptotic Closed Loop Training
Mar 22, 2022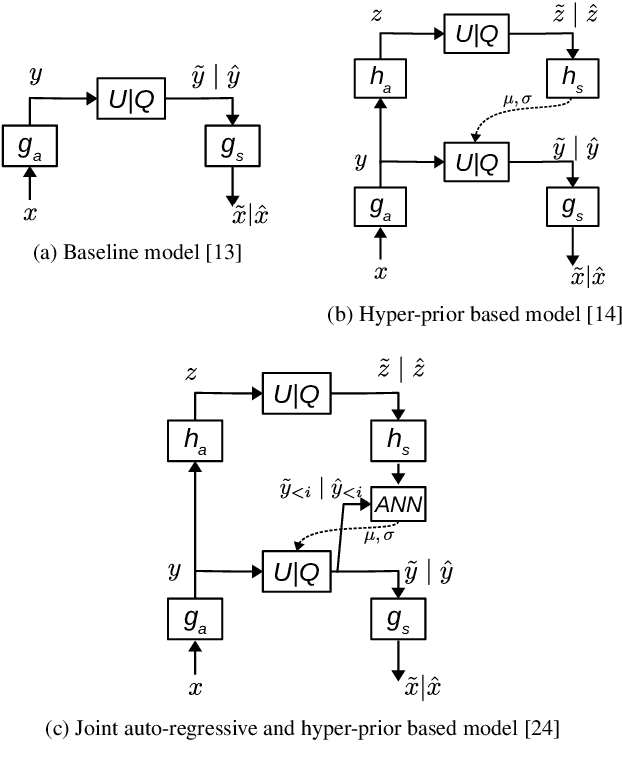

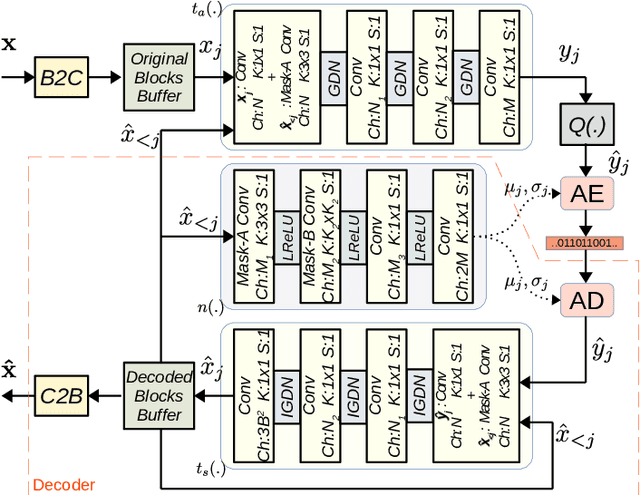
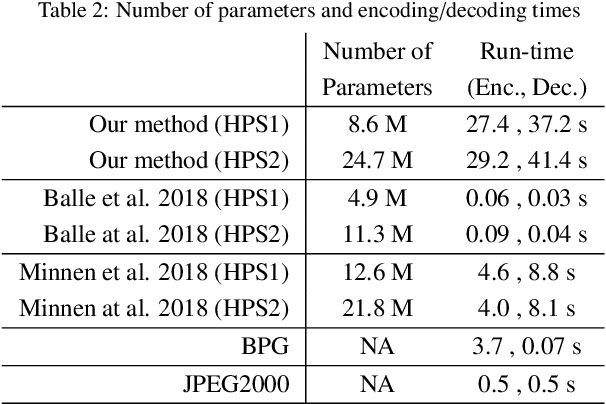
Learned image compression research has achieved state-of-the-art compression performance with auto-encoder based neural network architectures, where the image is mapped via convolutional neural networks (CNN) into a latent representation that is quantized and processed again with CNN to obtain the reconstructed image. CNN operate on entire input images. On the other hand, traditional state-of-the-art image and video compression methods process images with a block-by-block processing approach for various reasons. Very recently, work on learned image compression with block based approaches have also appeared, which use the auto-encoder architecture on large blocks of the input image and introduce additional neural networks that perform intra/spatial prediction and deblocking/post-processing functions. This paper explores an alternative learned block-based image compression approach in which neither an explicit intra prediction neural network nor an explicit deblocking neural network is used. A single auto-encoder neural network with block-level masked convolutions is used and the block size is much smaller (8x8). By using block-level masked convolutions, each block is processed using reconstructed neighboring left and upper blocks both at the encoder and decoder. Hence, the mutual information between adjacent blocks is exploited during compression and each block is reconstructed using neighboring blocks, resolving the need for explicit intra prediction and deblocking neural networks. Since the explored system is a closed loop system, a special optimization procedure, the asymptotic closed loop design, is used with standard stochastic gradient descent based training. The experimental results indicate competitive image compression performance.