 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest Practices for Convolutional Neural Networks Applied to Object Recognition in Images
Paper and Code
Oct 29, 2019
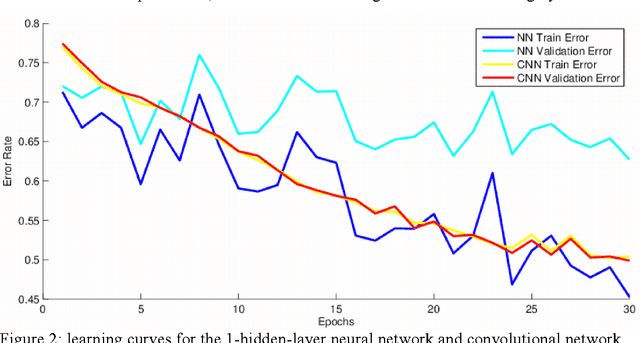
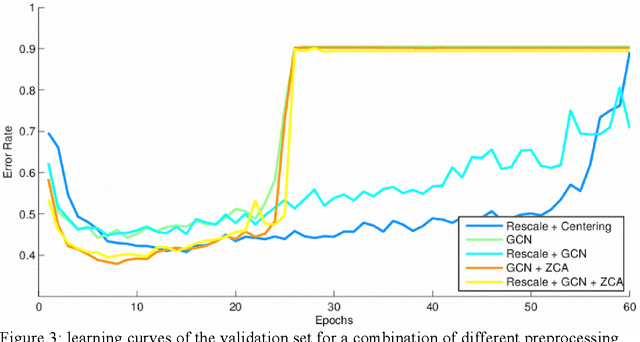
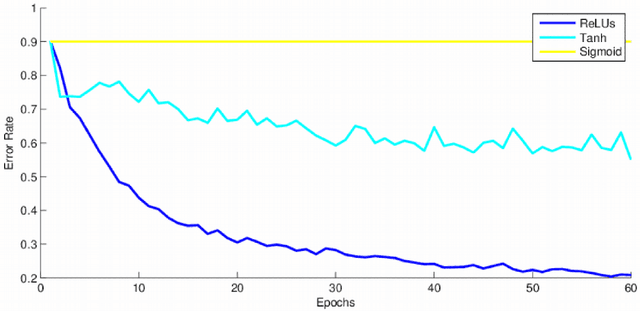
This research project studies the impact of convolutional neural networks (CNN) in image classification tasks. We explore different architectures and training configurations with the use of ReLUs, Nesterov's accelerated gradient, dropout and maxout networks. We work with the CIFAR-10 dataset as part of a Kaggle competition to identify objects in images. Initial results show that CNNs outperform our baseline by acting as invariant feature detectors. Comparisons between different preprocessing procedures show better results for global contrast normalization and ZCA whitening. ReLUs are much faster than tanh units and outperform sigmoids. We provide extensive details about our training hyperparameters, providing intuition for their selection that could help enhance learning in similar situations. We design 4 models of convolutional neural networks that explore characteristics such as depth, number of feature maps, size and overlap of kernels, pooling regions, and different subsampling techniques. Results favor models of moderate depth that use an extensive number of parameters in both convolutional and dense layers. Maxout networks are able to outperform rectifiers on some models but introduce too much noise as the complexity of the fully-connected layers increases. The final discussion explains our results and provides additional techniques that could improve performance.