 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShiftable Context: Addressing Training-Inference Context Mismatch in Simultaneous Speech Translation
Jul 03, 2023Transformer models using segment-based processing have been an effective architecture for simultaneous speech translation. However, such models create a context mismatch between training and inference environments, hindering potential translation accuracy. We solve this issue by proposing Shiftable Context, a simple yet effective scheme to ensure that consistent segment and context sizes are maintained throughout training and inference, even with the presence of partially filled segments due to the streaming nature of simultaneous translation. Shiftable Context is also broadly applicable to segment-based transformers for streaming tasks. Our experiments on the English-German, English-French, and English-Spanish language pairs from the MUST-C dataset demonstrate that when applied to the Augmented Memory Transformer, a state-of-the-art model for simultaneous speech translation, the proposed scheme achieves an average increase of 2.09, 1.83, and 1.95 BLEU scores across each wait-k value for the three language pairs, respectively, with a minimal impact on computation-aware Average Lagging.
RAPID: Enabling Fast Online Policy Learning in Dynamic Public Cloud Environments
Apr 10, 2023



Resource sharing between multiple workloads has become a prominent practice among cloud service providers, motivated by demand for improved resource utilization and reduced cost of ownership. Effective resource sharing, however, remains an open challenge due to the adverse effects that resource contention can have on high-priority, user-facing workloads with strict Quality of Service (QoS) requirements. Although recent approaches have demonstrated promising results, those works remain largely impractical in public cloud environments since workloads are not known in advance and may only run for a brief period, thus prohibiting offline learning and significantly hindering online learning. In this paper, we propose RAPID, a novel framework for fast, fully-online resource allocation policy learning in highly dynamic operating environments. RAPID leverages lightweight QoS predictions, enabled by domain-knowledge-inspired techniques for sample efficiency and bias reduction, to decouple control from conventional feedback sources and guide policy learning at a rate orders of magnitude faster than prior work. Evaluation on a real-world server platform with representative cloud workloads confirms that RAPID can learn stable resource allocation policies in minutes, as compared with hours in prior state-of-the-art, while improving QoS by 9.0x and increasing best-effort workload performance by 19-43%.
PROMPT: Learning Dynamic Resource Allocation Policies for Edge-Network Applications
Jan 19, 2022A growing number of service providers are exploring methods to improve server utilization, reduce power consumption, and reduce total cost of ownership by co-scheduling high-priority latency-critical workloads with best-effort workloads. This practice requires strict resource allocation between workloads to reduce resource contention and maintain Quality of Service (QoS) guarantees. Prior resource allocation works have been shown to improve server utilization under ideal circumstances, yet often compromise QoS guarantees or fail to find valid resource allocations in more dynamic operating environments. Further, prior works are fundamentally reliant upon QoS measurements that can, in practice, exhibit significant transient fluctuations, thus stable control behavior cannot be reliably achieved. In this paper, we propose a novel framework for dynamic resource allocation based on proactive QoS prediction. These predictions help guide a reinforcement-learning-based resource controller towards optimal resource allocations while avoiding transient QoS violations due to fluctuating workload demands. Evaluation shows that the proposed method incurs 4.3x fewer QoS violations, reduces severity of QoS violations by 3.7x, improves best-effort workload performance, and improves overall power efficiency compared with prior work.
Optimizing Routerless Network-on-Chip Designs: An Innovative Learning-Based Framework
May 11, 2019

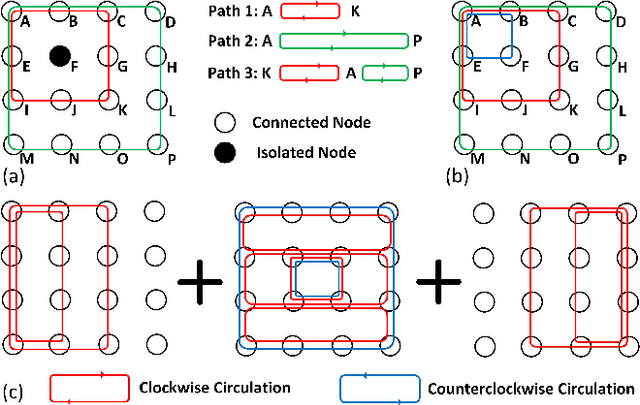
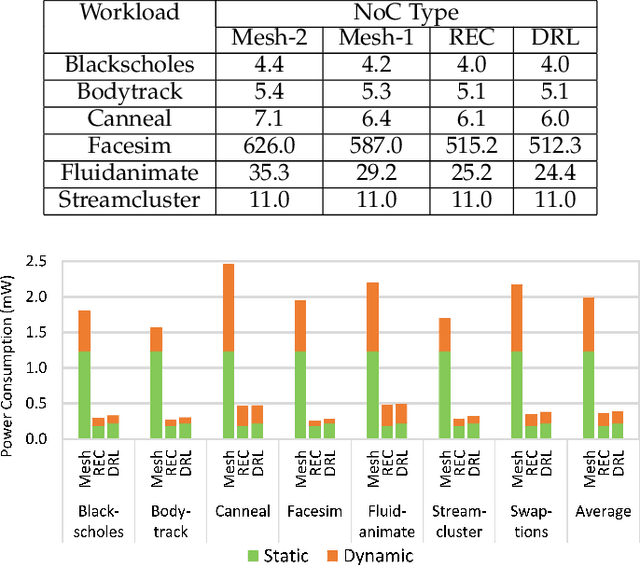
Machine learning applied to architecture design presents a promising opportunity with broad applications. Recent deep reinforcement learning (DRL) techniques, in particular, enable efficient exploration in vast design spaces where conventional design strategies may be inadequate. This paper proposes a novel deep reinforcement framework, taking routerless networks-on-chip (NoC) as an evaluation case study. The new framework successfully resolves problems with prior design approaches being either unreliable due to random searches or inflexible due to severe design space restrictions. The framework learns (near-)optimal loop placement for routerless NoCs with various design constraints. A deep neural network is developed using parallel threads that efficiently explore the immense routerless NoC design space with a Monte Carlo search tree. Experimental results show that, compared with conventional mesh, the proposed deep reinforcement learning (DRL) routerless design achieves a 3.25x increase in throughput, 1.6x reduction in packet latency, and 5x reduction in power. Compared with the state-of-the-art routerless NoC, DRL achieves a 1.47x increase in throughput, 1.18x reduction in packet latency, and 1.14x reduction in average hop count albeit with slightly more power overhead.