 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMF-VITON: High-Fidelity Mask-Free Virtual Try-On with Minimal Input
Mar 11, 2025Recent advancements in Virtual Try-On (VITON) have significantly improved image realism and garment detail preservation, driven by powerful text-to-image (T2I) diffusion models. However, existing methods often rely on user-provided masks, introducing complexity and performance degradation due to imperfect inputs, as shown in Fig.1(a). To address this, we propose a Mask-Free VITON (MF-VITON) framework that achieves realistic VITON using only a single person image and a target garment, eliminating the requirement for auxiliary masks. Our approach introduces a novel two-stage pipeline: (1) We leverage existing Mask-based VITON models to synthesize a high-quality dataset. This dataset contains diverse, realistic pairs of person images and corresponding garments, augmented with varied backgrounds to mimic real-world scenarios. (2) The pre-trained Mask-based model is fine-tuned on the generated dataset, enabling garment transfer without mask dependencies. This stage simplifies the input requirements while preserving garment texture and shape fidelity. Our framework achieves state-of-the-art (SOTA) performance regarding garment transfer accuracy and visual realism. Notably, the proposed Mask-Free model significantly outperforms existing Mask-based approaches, setting a new benchmark and demonstrating a substantial lead over previous approaches. For more details, visit our project page: https://zhenchenwan.github.io/MF-VITON/.
TED-VITON: Transformer-Empowered Diffusion Models for Virtual Try-On
Nov 26, 2024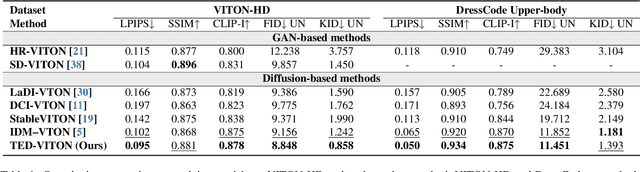
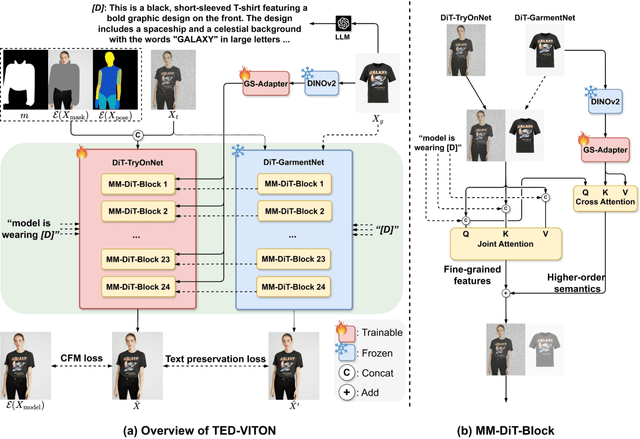


Recent advancements in Virtual Try-On (VTO) have demonstrated exceptional efficacy in generating realistic images and preserving garment details, largely attributed to the robust generative capabilities of text-to-image (T2I) diffusion backbones. However, the T2I models that underpin these methods have become outdated, thereby limiting the potential for further improvement in VTO. Additionally, current methods face notable challenges in accurately rendering text on garments without distortion and preserving fine-grained details, such as textures and material fidelity. The emergence of Diffusion Transformer (DiT) based T2I models has showcased impressive performance and offers a promising opportunity for advancing VTO. Directly applying existing VTO techniques to transformer-based T2I models is ineffective due to substantial architectural differences, which hinder their ability to fully leverage the models' advanced capabilities for improved text generation. To address these challenges and unlock the full potential of DiT-based T2I models for VTO, we propose TED-VITON, a novel framework that integrates a Garment Semantic (GS) Adapter for enhancing garment-specific features, a Text Preservation Loss to ensure accurate and distortion-free text rendering, and a constraint mechanism to generate prompts by optimizing Large Language Model (LLM). These innovations enable state-of-the-art (SOTA) performance in visual quality and text fidelity, establishing a new benchmark for VTO task.